【 C# 】(一) ------------- 泛型带头节点的单链表,双向链表实现
在编程领域,数据结构与算法向来都是提升编程能力的重点。而一般常见的数据结构是链表,栈,队列,树等。事实上C#也已经封装好了这些数据结构,在头文件 System.Collections.Generic 中,直接创建并调用其成员方法就行。不过我们学习当然要知其然,亦知其所以然。
本文实现的是链表中的单链表和双向链表,并且实现了一些基本方法
一. 定义一个链表接口 MyList
接口里声明了我们要实现的方法:
interface MyList<T>
{
int GetLength(); //获取链表长度
void Clear(); //清空链表
bool IsEmpty(); //判断链表是否为空
void Add(T item); //在链表尾部添加新节点
void AddPre(T item,int index); //在指定节点前添加新节点
void AddPost(T item,int index); //在指定节点后添加新节点
T Delete(int index); //按索引删除节点
T Delete(T item,bool isSecond = true); //按内容删除节点,如果有多个内容相同点,则删除第一个
T this[int index] { get; } //实现下标访问
T GetElem(int index); //根据索引返回元素
int GetPos(T item); //根据元素返回索引地址
void Print(); //打印
}
二. 实现单链表
2.1 节点类
先定义一个单链表所用的节点类,Node。而且我们要实现泛型
先定义一个数据域和下一节点(“Next”),并进行封装,然后给出数个重载构造器。这一步比较简单,这里直接给出代码
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks; namespace 线性表
{
/// <summary>
/// 单向链表节点
/// </summary>
/// <typeparam name="T"></typeparam>
class Node<T>
{
private T data; //内容域
private Node<T> next; //下一节点 public Node()
{
this.data = default(T);
this.next = null;
} public Node(T value)
{
this.data = value;
this.next = null;
} public Node(T value,Node<T> next)
{
this.data = value;
this.next = next;
} public T Data
{
get { return data; }
set { data = value; }
} public Node<T> Next
{
get { return next; }
set { next = value; }
}
}
}
2.2 链表类
创建一个链表类,命名为 LinkList 并继承 MyList。
先定义一个头结点,尾节点和一个 count;
其中,head 表示该链表的头部,不包含数据;
tail 表示尾节点,指向该链表最后一个节点,当链表中只有 head 时,tail 指向 head。定义 tail 会方便接下来的操作
count 用来表示该链表中除了 head 以外的节点个数
构造函数:
/// <summary>
/// 构造器
/// </summary>
public LinkList()
{
head = new Node<T>();
tail = head;
count = 0;
}
在我们实现成员函数之前,先实现两个特别的方法,因为在许多的成员方法中都要做两个操作:
- 判断索引 index 是否合法,即是否小于0或者大于当前链表的节点个数
- 寻找到 index 所代表的节点
①. 判断索引是否合法,然后可以根据其返回的数值进行判断操作
②. 寻找节点。
定义这两个方法主要是它们的重复使用率高,所以把它们的代码抽出来。
相对于数组,链表的插入与删除更方便,而查找却更加费时,一般都是从头结点开始遍历链表,时间复杂度为 O(n) ,而跳跃链表则会对查询进行优化,当然这会在下一篇中详述。现在继续来实现成员方法。
1. 获取链表长度
这个方法实际上是比较简单的,因为 count 会随着添加,删除等操作自动增减,所以直接返回 count 就相当于 链表长度。
需要注意的是,本文中的 count 是不计算空头结点的,即 head 不会计算入内
2. 清空链表
这里要注意对 tail 的操作,而 head.Next 原本所指的节点不再被引用后,会被GC自动回收
3. 判断链表是否为空
因为本文实现的链表是带空头结点的,所以这里认为,当除了头结点外没有别的节点时,则为空链表
4. 在链表尾部添加节点
在链表尾添加节点一般考虑两种情况:
- 当前除了头结点没有别的节点,此时相当于创建第一个节点
- 寻找到最后一个节点
对于带空头结点的链表来说,这两种情况有着一样的操作,只不过第一种情况要多做一步:让 head 指向新创建的节点
定义了 tail 节点省去了 遍历寻找最后节点的步骤,如果此时是空链表的话,tail 则指向 head
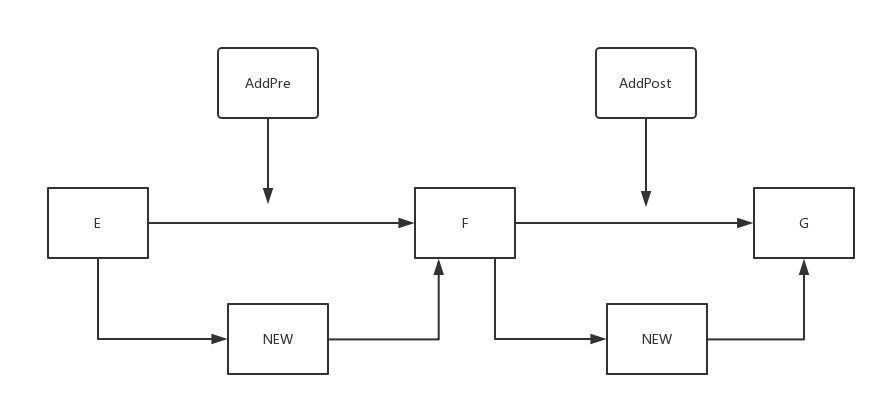
5. 在指定索引的前或后添加节点
这两个方法的思路实际上相差无几的
如图,当 index 为 F 时:
- AddPost: ① 找到 F 节点 ②创建 NEW 节点;③ NEW 节点指向 G;④ F 指向 NEW 节点
- AddPre : ① 找到 E 节点 ②创建 NEW 节点;③ NEW 节点指向 F ;④ E 指向 NEW 节点
AddPre 相当于 index - 1 处的 AddPost;AddPost 相当于 index + 1 处的 AddPre(当然,这是在 index -1 与 index + 1 合法的情况下)
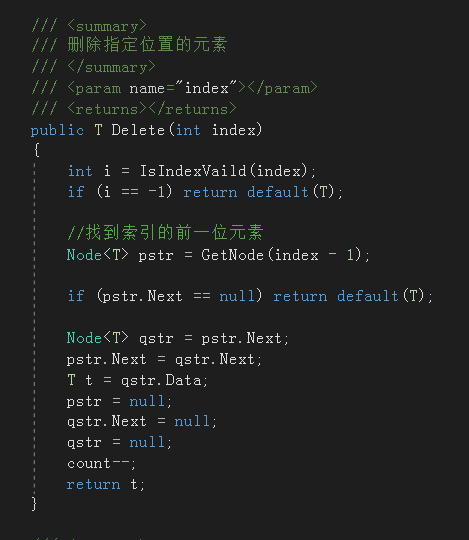
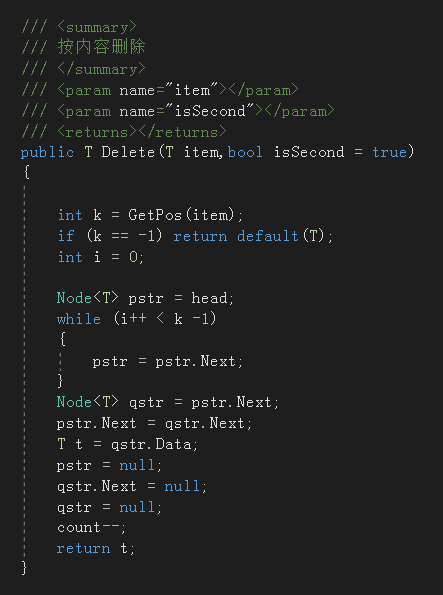
6. 两种删除节点方法
- 按索引删除:找到索引所指节点,删除
- 按元素删除:找元素所在的索引;当找不到该元素时表明链表中不存在应该删除的节点,不执行删除操作;当链表中存在多个相同的元素时,找到并删除第一个
两种删除方法操作都是相似的,只是搜索节点的方法不同,删除时要严格注意节点间指向的,即注意书写代码时的顺序
7. 实现下标访问
这是个比较有趣的实现。前文说过对比于数组,链表胜于增减,弱于访问。对链表实现下标式访问,虽然它的内核依然是遍历链表,然后返回节点,但在使用上会方便许多,如同使用数组一般。
8. 根据索引返回元素
这个和 GetNode 方法一致
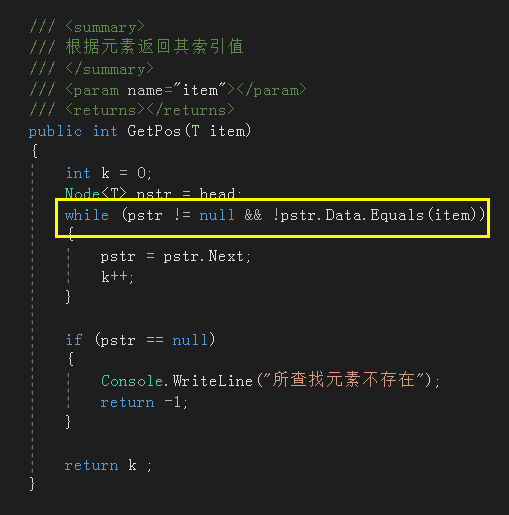
9. 根据元素返回索引地址
这个方法也是比较简单的,只是需要注意的一点是:while循环条件中 && 号两端的条件不能调换位置。因为如果调换位置后,当链表遍历到最后一个节点仍没找到元素时,pstr 会被赋值下一节点(此时为NULL),然后循环继续执行,执行到 !pstr.Data.Equals(item) 这一句时会报空指针,因为此时 pstr 就是空指针;还有因为这是泛型,所以判断两个值是否相等不能用 == 号,除非你重载 == 号。
10.打印链表
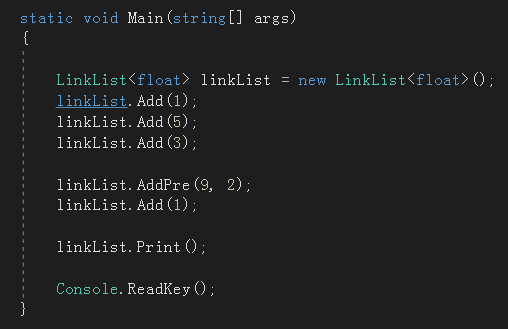
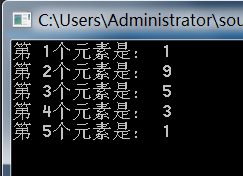
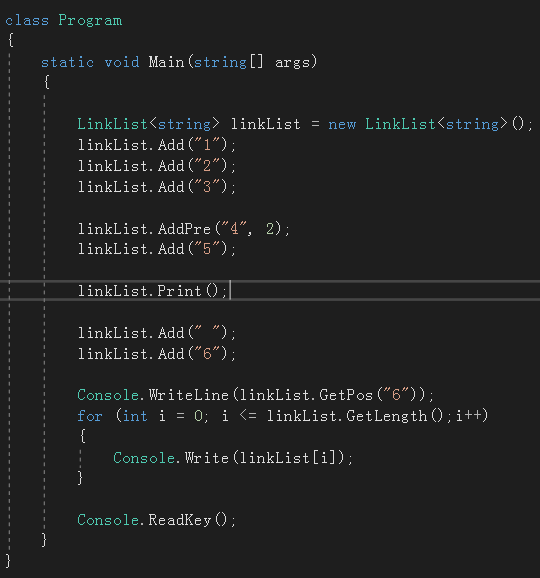
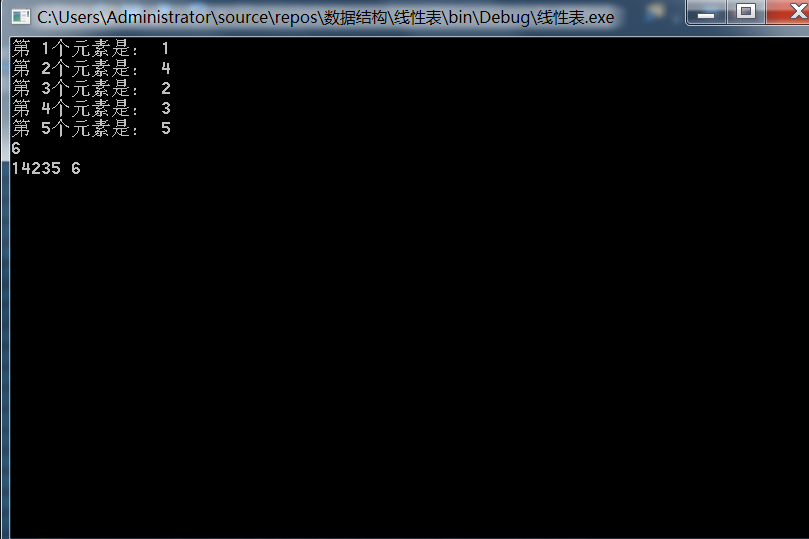
至此,所以的成员方法都实现了,先来测试一下。
1
.
其它功能读者可以自行测试,完整代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks; namespace 线性表
{
class LinkList<T> : MyList<T>
{
private Node<T> head; //头结点
private Node<T> tail; //尾节点
private int count; //节点个数 /// <summary>
/// 构造器
/// </summary>
public LinkList()
{
head = new Node<T>();
tail = head;
count = 0;
} /// <summary>
/// 实现下标访问法
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public T this[int index]
{
get
{
int i = IsIndexVaild(index);
if(i == -1) return default(T); int k = 0;
Node<T> pstr = head;
while (k++ < index )
{
pstr = pstr.Next;
} return pstr.Data; }
} /// <summary>
/// 在链表最末端添加新节点
/// </summary>
/// <param name="item"></param>
public void Add(T item)
{
Node<T> tailNode = new Node<T>(item);
tail.Next = tailNode;
tail = tailNode;
if (count == 0) head.Next = tailNode;
count++;
} /// <summary>
/// 在第 index 号元素后插入一个节点
/// <param name="item"></param>
/// <param name="index"></param>
public void AddPost(T item, int index)
{
int i = IsIndexVaild(index);
if (i == -1) return; //找到索引元素
Node<T> pstr = GetNode(index); //链接新节点
Node<T> node = new Node<T>(item);
node.Next = pstr.Next;
pstr.Next = node;
if (index == count) tail = node;
count++;
pstr = null;
} /// <summary>
/// 在第 index 号元素前插入一个节点
/// </summary>
/// <param name="item"></param>
/// <param name="index"></param>
public void AddPre(T item, int index)
{
int i = IsIndexVaild(index);
if (i == -1) return; //找到索引的前一位元素
Node<T> pstr = GetNode(index - 1); //链接新节点
Node<T> node = new Node<T>(item);
node.Next = pstr.Next;
pstr.Next = node;
count++;
pstr = null;
} /// <summary>
/// 清空链表
/// </summary>
public void Clear()
{
head.Next = null;
tail = head;
} /// <summary>
/// 删除指定位置的元素
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public T Delete(int index)
{
int i = IsIndexVaild(index);
if (i == -1) return default(T); //找到索引的前一位元素
Node<T> pstr = GetNode(index - 1); if (pstr.Next == null) return default(T); Node<T> qstr = pstr.Next;
pstr.Next = qstr.Next;
T t = qstr.Data;
pstr = null;
qstr.Next = null;
qstr = null;
count--;
return t;
} /// <summary>
/// 按内容删除
/// </summary>
/// <param name="item"></param>
/// <param name="isSecond"></param>
/// <returns></returns>
public T Delete(T item,bool isSecond = true)
{ int k = GetPos(item);
if (k == -1) return default(T);
int i = 0; Node<T> pstr = head;
while (i++ < k -1)
{
pstr = pstr.Next;
}
Node<T> qstr = pstr.Next;
pstr.Next = qstr.Next;
T t = qstr.Data;
pstr = null;
qstr.Next = null;
qstr = null;
count--;
return t;
} /// <summary>
/// 返回指定索引的元素
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public T GetElem(int index)
{
int i = IsIndexVaild(index);
if (i == -1) return default(T); return GetNode(index).Data;
} /// <summary>
/// 返回链表长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return count;
} /// <summary>
/// 根据元素返回其索引值
/// </summary>
/// <param name="item"></param>
/// <returns></returns>
public int GetPos(T item)
{
int k = 0;
Node<T> pstr = head.Next;
while (pstr != null && item != null && !pstr.Data.Equals(item))
{
pstr = pstr.Next;
k++;
} if (pstr == null)
{
Console.WriteLine("所查找元素不存在");
return -1;
} return k ;
} /// <summary>
/// 判断链表是否为空
/// </summary>
/// <returns></returns>
public bool IsEmpty()
{
if (head == null || head.Next == null) return true;
return false;
} /// <summary>
/// 打印
/// </summary>
public void Print()
{
Node<T> pstr = head.Next;
int i = 1;
while(pstr != null)
{
Console.WriteLine("第 " + i++ + "个元素是: " + pstr.Data);
pstr = pstr.Next;
}
} /// <summary>
/// 判断索引是否错误
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public int IsIndexVaild(int index)
{
//判断索引是否越界
if (index < 0 || index > count)
{
Console.WriteLine("索引越界,不存在该元素");
return -1;
}
return 0;
} /// <summary>
/// 根据索引找到元素
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public Node<T> GetNode(int index)
{
int k = 0;
Node<T> pstr = head;
while (k++ < index)
{
pstr = pstr.Next;
}
return pstr;
}
}
}














三. 双向链表
双向链表在思路上和单链表差不多,只是多了一个指向上一个节点的 Prev,所以代码上要更小心地处理。具体就不多赘述了,直接给出代码吧
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks; namespace 线性表
{
class DBNode<T>
{
private T data;
private DBNode<T> next;
private DBNode<T> prev; public DBNode()
{
this.data = default(T);
this.next = null;
this.prev = null;
} public DBNode(T value)
{
this.data = value;
this.next = null;
this.prev = null;
} public DBNode(T value, DBNode<T> next)
{
this.data = value;
this.next = next;
this.prev = null;
} public T Data
{
get { return data; }
set { data = value; }
} public DBNode<T> Next
{
get { return next; }
set { next = value; }
} public DBNode<T> Prev
{
get { return prev; }
set { prev = value; }
}
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks; namespace 线性表
{
class DBLinkList<T> : MyList<T>
{
private DBNode<T> head;
private DBNode<T> tail;
private int count; /// <summary>
/// 构造器
/// </summary>
public DBLinkList()
{
head = new DBNode<T>();
tail = head;
count = 0;
} /// <summary>
/// 实现下标访问法
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public T this[int index]
{
get
{
int i = IsIndexVaild(index);
if (i == -1) return default(T); int k = 0;
DBNode<T> pstr = head;
while (k++ < index)
{
pstr = pstr.Next;
} return pstr.Data;
}
} /// <summary>
/// 在链表最末端添加新节点
/// </summary>
/// <param name="item"></param>
public void Add(T item)
{
if (count == 0)
{
DBNode<T> DbNode = new DBNode<T>(item);
DbNode.Prev = head;
head.Next = DbNode;
tail = DbNode;
count++;
return;
} DBNode<T> tailDBNode = new DBNode<T>(item);
tailDBNode.Prev = tail;
tail.Next = tailDBNode;
tail = tailDBNode;
count++;
} /// <summary>
/// 在第 index 号元素后插入一个节点,index 为 1,2,3,4.....
/// </summary>
/// <param name="item"></param>
/// <param name="index"></param>
public void AddPost(T item, int index)
{
//判断索引是否越界
int i = IsIndexVaild(index);
if (i == -1) return; //找到索引元素
DBNode<T> pstr = GetNode(index); //链接新节点
DBNode<T> newNode = new DBNode<T>(item);
newNode.Next = pstr.Next;
newNode.Prev = pstr;
if(pstr.Next != null) pstr.Next.Prev = newNode;
pstr.Next = newNode; //如果是在最后节点添加
if (index == count) tail = newNode;
count++;
pstr = null;
} /// <summary>
/// 在第 index 号元素前插入一个节点,index 为 1,2,3,4.....
/// </summary>
/// <param name="item"></param>
/// <param name="index"></param>
public void AddPre(T item, int index)
{
//判断索引是否越界
int i = IsIndexVaild(index);
if (i == -1) return; //找到索引的前一位元素
DBNode<T> pstr = GetNode(index - 1); //链接新节点
DBNode<T> newNode = new DBNode<T>(item);
newNode.Next = pstr.Next;
newNode.Prev = pstr;
pstr.Next.Prev = newNode;
pstr.Next = newNode;
count++;
pstr = null; //在 index 处AddPre相当于在 index - 1 处 AddPost,不过并不需要判断尾节点
} /// <summary>
/// 清空链表
/// </summary>
public void Clear()
{
head.Next = null;
tail = head;
} /// <summary>
/// 删除指定位置的元素
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public T Delete(int index)
{
//判断索引是否越界
int i = IsIndexVaild(index);
if (i == -1) return default(T); //找到索引的前一位元素
DBNode<T> pstr = head;
int k = 0;
while (k++ < index - 1 && pstr != null)
{
pstr = pstr.Next;
} if (pstr.Next == null) return default(T); DBNode<T> qstr = pstr.Next;
T t = qstr.Data; pstr.Next = qstr.Next;
qstr.Next.Prev = pstr; pstr = null;
qstr.Next = null;
qstr = null;
count--;
return t;
} /// <summary>
/// 按内容删除
/// </summary>
/// <param name="item"></param>
/// <param name="isSecond"></param>
/// <returns></returns>
public T Delete(T item,bool isSecond = true)
{ int k = GetPos(item);
if (k == -1) return default(T);
int i = 0; DBNode<T> pstr = head;
while (i++ < k - 1)
{
pstr = pstr.Next;
} DBNode<T> qstr = pstr.Next;
T t = qstr.Data; pstr.Next = qstr.Next;
if(qstr.Next != null) qstr.Next.Prev = pstr; pstr = null;
qstr.Next = null;
qstr = null;
count--;
return t;
} /// <summary>
/// 返回指定索引的元素
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public T GetElem(int index)
{
int i = IsIndexVaild(index);
if (i == -1) return default(T); int k = 0;
DBNode<T> pstr = head;
while (k++ < index)
{
pstr = pstr.Next;
} return pstr.Data;
} /// <summary>
/// 返回链表长度
/// </summary>
/// <returns></returns>
public int GetLength()
{
return count;
} /// <summary>
/// 根据元素返回其索引值
/// </summary>
/// <param name="item"></param>
/// <returns></returns>
public int GetPos(T item)
{
int k = 0;
DBNode<T> pstr = head.Next;
while (pstr != null && item != null && !pstr.Data.Equals(item))
{
pstr = pstr.Next;
k++;
} if (pstr == null)
{
Console.WriteLine("所查找元素不存在");
return -1;
} return k;
} /// <summary>
/// 判断链表是否为空
/// </summary>
/// <returns></returns>
public bool IsEmpty()
{
if (head == null || head.Next == null) return true;
return false;
} /// <summary>
/// 打印
/// </summary>
public void Print()
{
DBNode<T> pstr = head.Next;
while (pstr != null)
{
Console.WriteLine(pstr.Data);
pstr = pstr.Next;
}
} /// <summary>
/// 判断索引是否错误
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public int IsIndexVaild(int index)
{
//判断索引是否越界
if (index < 0 || index > count)
{
Console.WriteLine("索引越界,不存在该元素");
return -1;
}
return 0;
} /// <summary>
/// 根据索引找到元素
/// </summary>
/// <param name="index"></param>
/// <returns></returns>
public DBNode<T> GetNode(int index)
{
int k = 0;
DBNode<T> pstr = head;
while (k++ < index)
{
pstr = pstr.Next;
}
return pstr;
}
}
}
总结
事实上,链表是一种比较简单且常用的数据结构。实现起来并不困难,只是要小心谨慎。下一篇会说到跳跃链表,跳跃链表的效率更高。好了,希望本文能对大家有所帮助

【 C# 】(一) ------------- 泛型带头节点的单链表,双向链表实现的更多相关文章
- 带头节点的单链表-------C语言实现
/***************************************************** Author:Simon_Kly Version:0.1 Date:20170520 De ...
- 不带头结点的单链表------C语言实现
File name:no_head_link.c Author:SimonKly Version:0.1 Date: 2017.5.20 Description:不带头节点的单链表 Funcion L ...
- 有一个线性表,采用带头结点的单链表L来存储,设计一个算法将其逆置,且不能建立新节点,只能通过表中已有的节点的重新组合来完成。
有一个线性表,采用带头结点的单链表L来存储,设计一个算法将其逆置,且不能建立新节点,只能通过表中已有的节点的重新组合来完成. 分析:线性表中关于逆序的问题,就是用建立链表的头插法.而本题要求不能建立新 ...
- java编写带头结点的单链表
最近在牛客网上练习在线编程,希望自己坚持下去,每天都坚持下去练习,给自己一个沉淀,不多说了 我遇到了一个用java实现单链表的题目,就自己在做题中将单链表完善了一下,希望大家作为参考也熟悉一下,自己 ...
- C/C++中创建(带头结点、不带头结点的)单链表
1.带头结点的单链表(推荐使用带头结点的单链表)(采用尾插法) 了解单链表中节点的构成 从上图可知,节点包含数据域和指针域,因此,在对节点进行定义时,我们可以如下简单形式地定义: /* 定义链表 */ ...
- c语言实现--不带头结点的单链表操作
1,不带头结点的单链表操作中,除了InitList(),GetElem(),ListInsert(),ListDelete()操作与带头结点的单链表有差别外,其它的操作基本上一样. 2,不带头结点单链 ...
- 链表习题(2)-一个集合用带头结点的单链表L表示,编写算法删除其值最大的结点。
/*一个集合用带头结点的单链表L表示,编写算法删除其值最大的结点.*/ /* 算法思想:使用pre,p,premax,max四个指针,pre和p进行比较,premax和max进行最后的删除操作 通过遍 ...
- 链表习题(1)-设计一个递归算法,删除不带头结点的单链表L中所有值为x的结点
/*设计一个递归算法,删除不带头结点的单链表L中所有值为x的结点*/ /* 算法思想:设f(L,x)的功能是删除以L为首结点指针的单链表中所有值等于x的结点, 则显然有f(L->next,x)的 ...
- C语言:将带头节点的单向链表结点域中的数据从小到大排序。-求出单向链表结点(不包括头节点)数据域中的最大值。-将M*N的二维数组中的数据,按行依次放入一维数组,
//函数fun功能是将带头节点的单向链表结点域中的数据从小到大排序. //相当于数组的冒泡排序. #include <stdio.h> #include <stdlib.h> ...
随机推荐
- 学习python第四天——Oracle查询
3.子查询(难): 当进行查询的时候,发现需要的数据信息不明确,需要先通过另一个查询得到, 此查询称为子查询: 执行顺序:先执行子查询得到结果以后返回给主查询 组成部分: 1).主查询部分 2).子查 ...
- Dictionary<string, object>
Dictionary<string, object> dcic = JsonHelper.DataRowFromJSON(resultdepth); foreach (var depthk ...
- ASP.NET Core读取appsettings.json配置文件信息
1.在配置文件appsettings.json里新增AppSettings节点 { "Logging": { "LogLevel": { "Defau ...
- python110道面试题
1.一行代码实现1--100之和 利用sum()函数求和 2.如何在一个函数内部修改全局变量 利用global 修改全局变量 3.列出5个python标准库 os:提供了不少与操作系统相关联的函数 s ...
- unittest中setUp与setUpClass执行顺序
最基础的概念 1.setUP(self)看下面的执行顺序 import unittest class TestGo(unittest.TestCase): def setUp(self): print ...
- Kafka设计解析(十四)Kafka producer介绍
转载自 huxihx,原文链接 Kafka producer介绍 Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer.本文着重讨论新版本produce ...
- Handlebars模板引擎
介绍 Handlebars 是 JavaScript 一个语义模板库,通过对view和data的分离来快速构建Web模板.它采用"Logic-less template"(无逻辑模 ...
- 【题解】洛谷P2577 [ZJOI2005] 午餐(DP+贪心)
次元传送门:洛谷P2577 思路 首先贪心是必须的 我们能感性地理解出吃饭慢的必须先吃饭(结合一下生活) 因此我们可以先按吃饭时间从大到小排序 然后就能自然地想到用f[i][j][k]表示前i个人在第 ...
- jlink RTT 打印 BUG , FreeRTOS 在开启 tickless 模式下 无法使用的问题
一开始我以为是 jlink 的问题,后面发现是 tickless 模式搞鬼 tickless 模式下 ,内核 会 根据任务需求,会停止工作,这个时候 jlink rtt 打印就会失效!!! 不过 NR ...
- 我的react学习
基础部分 创建一个react的项目 创建一个react的项目 全局安装 react 指令 // 全局安装react (根据需要安装,不是必须的) npm i -g react // 或者 yarn - ...