Spark(十四)SparkStreaming的官方文档
一、SparkCore、SparkSQL和SparkStreaming的类似之处

二、SparkStreaming的运行流程
2.1 图解说明
2.2 文字解说
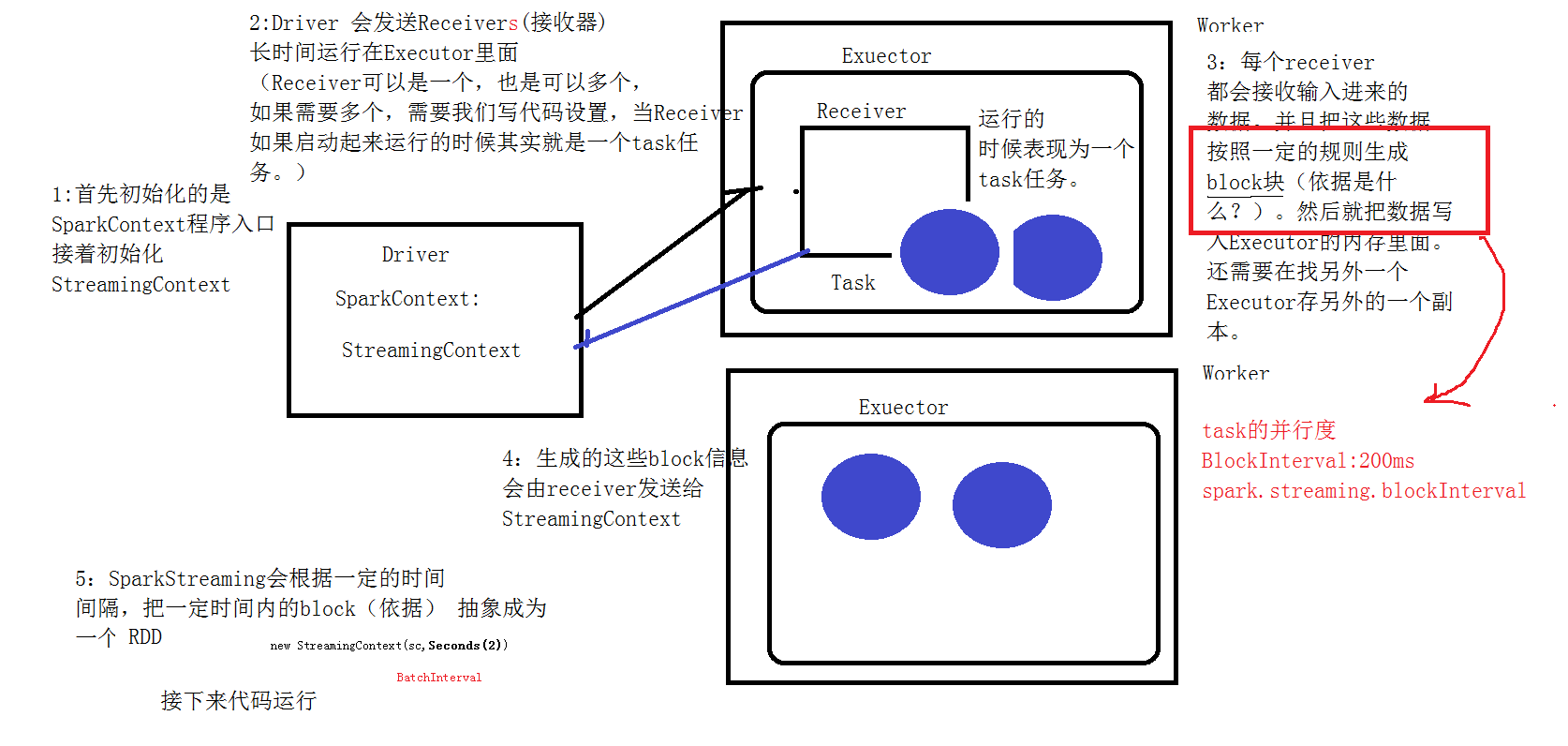
1、我们在集群中的其中一台机器上提交我们的Application Jar,然后就会产生一个Application,开启一个Driver,然后初始化SparkStreaming的程序入口StreamingContext;
2、Master会为这个Application的运行分配资源,在集群中的一台或者多台Worker上面开启Excuter,executer会向Driver注册;
3、Driver服务器会发送多个receiver给开启的excuter,(receiver是一个接收器,是用来接收消息的,在excuter里面运行的时候,其实就相当于一个task任务)
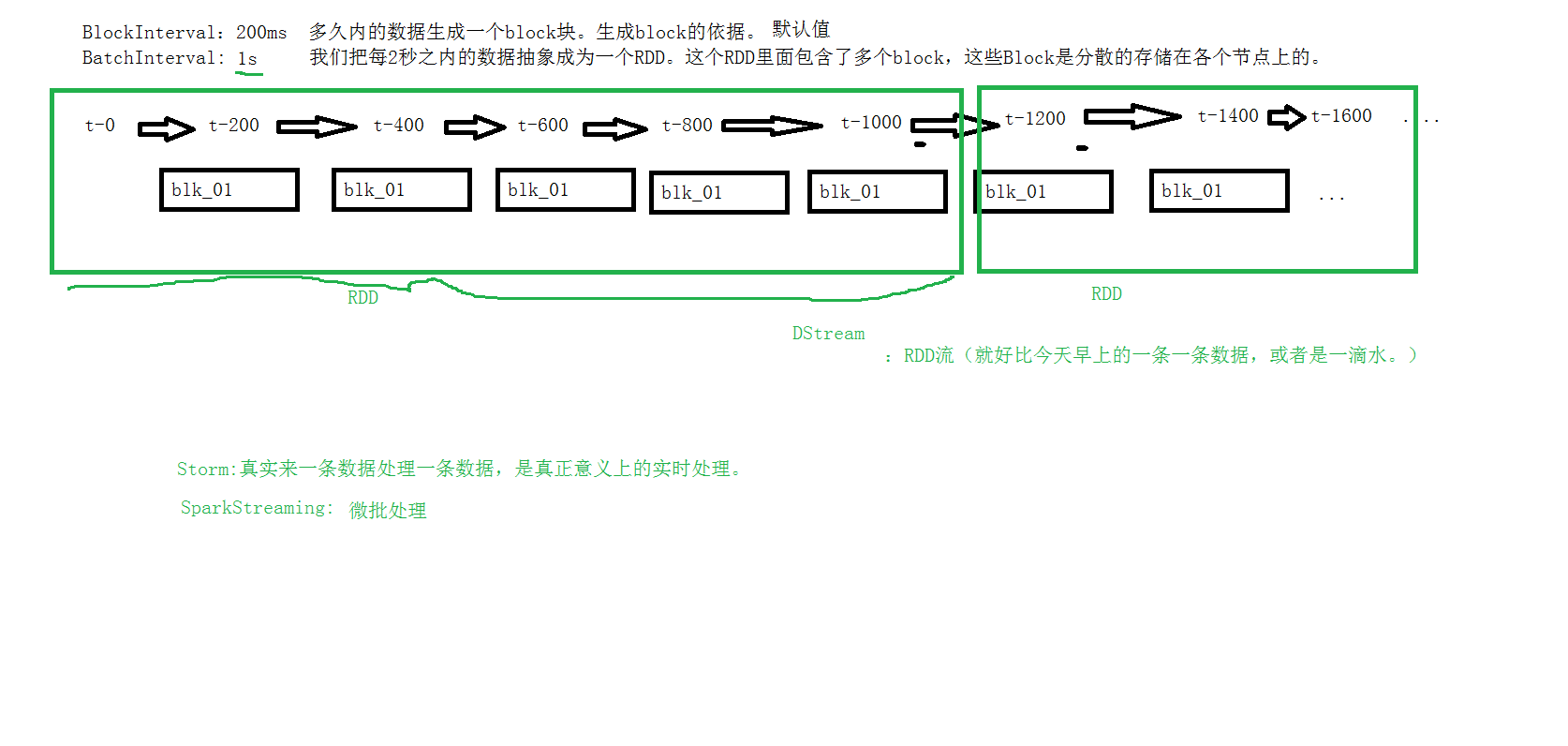
4、receiver接收到数据后,每隔200ms就生成一个block块,就是一个rdd的分区,然后这些block块就存储在executer里面,block块的存储级别是Memory_And_Disk_2;
5、receiver产生了这些block块后会把这些block块的信息发送给StreamingContext;
6、StreamingContext接收到这些数据后,会根据一定的规则将这些产生的block块定义成一个rdd;
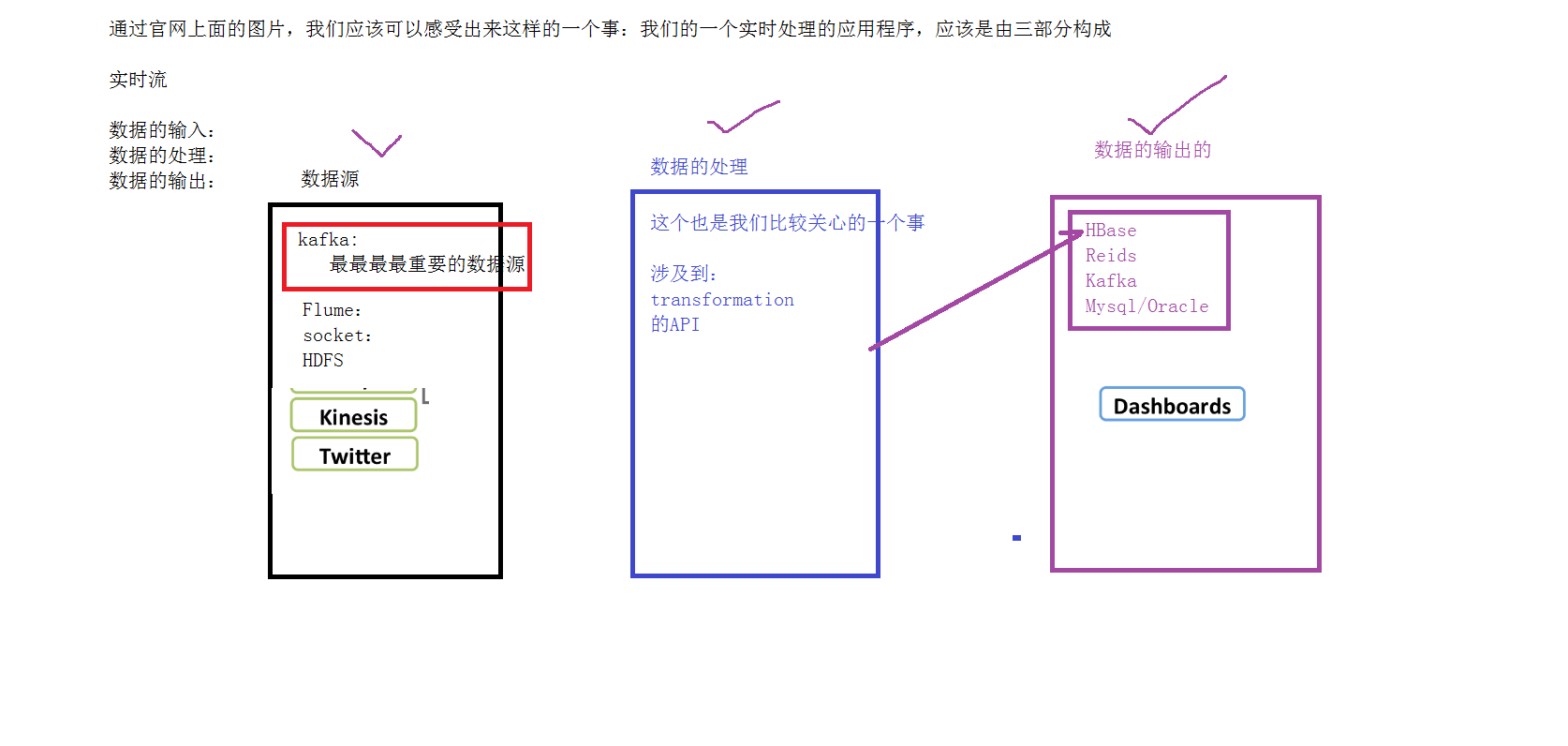
三、SparkStreaming的3个组成部分
四、 离散流(DStream)
五、小例子
5.1 简单的单词计数
Scala代码
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object NetWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
val sparkContext = new SparkContext(conf)
val sc = new StreamingContext(sparkContext,Seconds(2))
/**
* 数据的输入
* */
val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("bigdata",9999)
inDStream.print()
/**
* 数据的处理
* */
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
/**
* 数据的输出
* */
resultDStream.print()
/**
*启动应用程序
* */
sc.start()
sc.awaitTermination()
sc.stop()
}
}
在Linux上执行以下命令

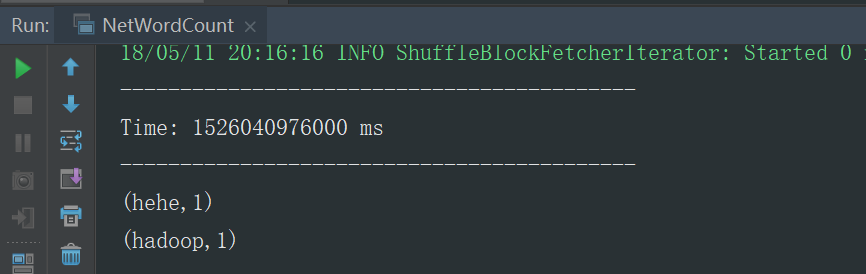
运行结果
5.2 监控HDFS上的一个目录
HDFS上的目录需要先创建
Scala代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext} object HDFSWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName)
val sc = new StreamingContext(conf,Seconds(2)) val inDStream: DStream[String] = sc.textFileStream("hdfs://hadoop1:9000/streaming")
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
resultDStream.print() sc.start()
sc.awaitTermination()
sc.stop()
}
}
Linux上的命令
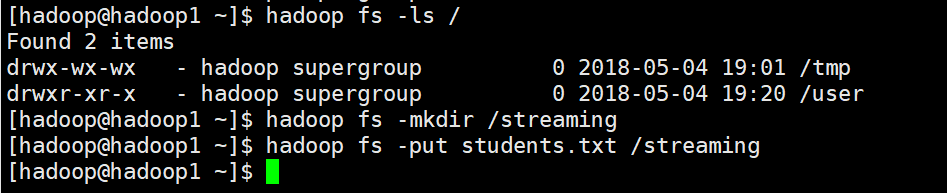
student.txt
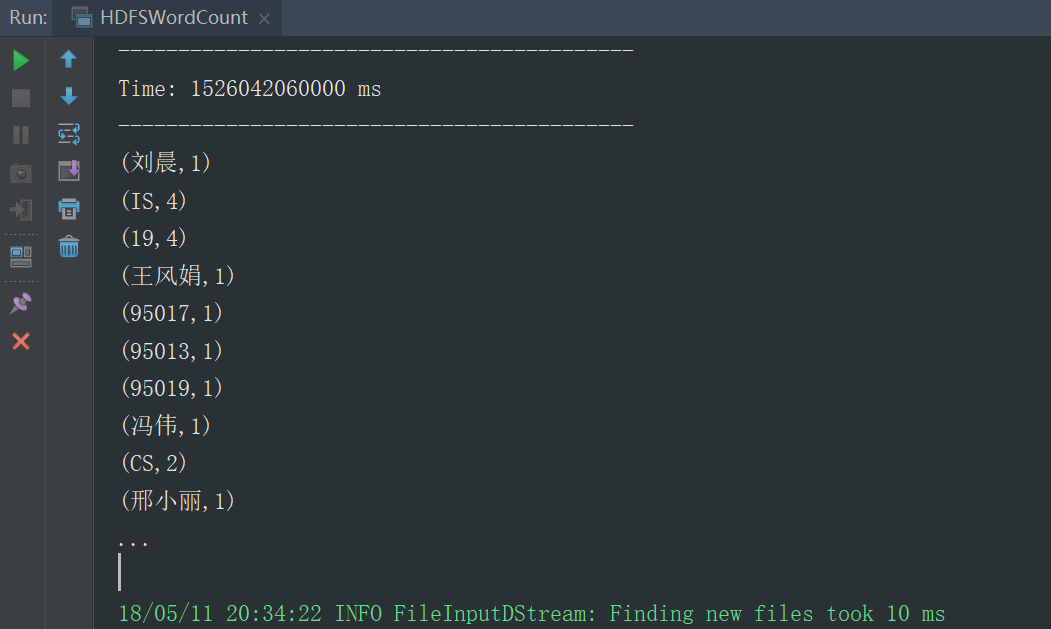
95002,刘晨,女,19,IS
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95019,邢小丽,女,19,IS
运行结果,默认展示的10条
5.3 第二次运行的时候更新原先的结果
Scala代码
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object UpdateWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
System.setProperty("HADOOP_USER_NAME","hadoop")
val sparkContext = new SparkContext(conf)
val sc = new StreamingContext(sparkContext,Seconds(2))
sc.checkpoint("hdfs://hadoop1:9000/streaming")
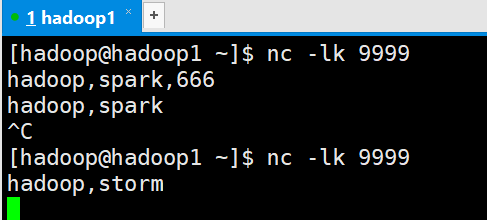
val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("hadoop1",9999)
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(","))
.map((_, 1))
.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
val currentCount: Int = values.sum
val lastCount: Int = state.getOrElse(0)
Some(currentCount + lastCount)
})
resultDStream.print()
sc.start()
sc.awaitTermination()
sc.stop()
}
}
Linux运行命令
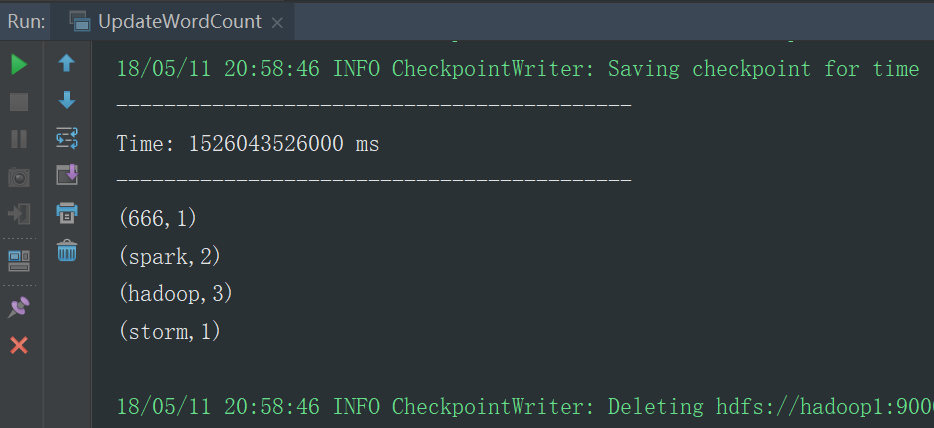
运行结果
5.4 DriverHA
5.3的代码一直运行,结果可以一直累加,但是代码一旦停止运行,再次运行时,结果会不会接着上一次进行计算,上一次的计算结果丢失了,主要原因上每次程序运行都会初始化一个程序入口,而2次运行的程序入口不是同一个入口,所以会导致第一次计算的结果丢失,第一次的运算结果状态保存在Driver里面,所以我们如果想用上一次的计算结果,我们需要将上一次的Driver里面的运行结果状态取出来,而5.3里面的代码有一个checkpoint方法,它会把上一次Driver里面的运算结果状态保存在checkpoint的目录里面,我们在第二次启动程序时,从checkpoint里面取出上一次的运行结果状态,把这次的Driver状态恢复成和上一次Driver一样的状态
Spark(十四)SparkStreaming的官方文档的更多相关文章
- ios学习笔记第四天之官方文档总结
start developing ios app today. 官方文档的体系结构为: 各层的主要框架图: objectice-c是动态语言 Objective-C 为 ANSI C 添加了下述语法和 ...
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore.SparkSQL和SparkStreaming的类似之处 SparkStreaming的运行流程 1.我们在集群中的其中一台机器上提交我们的Application Jar,然后就会 ...
- 【Phabricator】教科书一般的Phabricator安装教程(配合官方文档并带有踩坑解决方案)
随着一声惊雷和滂沱的大雨,我的Phabricator页面终于在我的学生机上跑了起来. 想起在这五个小时内踩过的坑甚如大学隔壁炮王干过的妹子,心里的成就感不禁油然而生. 接下来,我将和大家分享一下本人在 ...
- Spring 4 官方文档学习(十四)WebSocket支持
个人提示:如果需要用到页面推送,高频且要低延迟,WebSocket无疑是最佳选择.否则还是轮询和long polling吧. 做了一个小demo放在码云上,有兴趣的可以看一下,简单易懂:websock ...
- Spark Streaming官方文档学习--上
官方文档地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html Spark Streaming是spark ap ...
- 转:ArcGIS API For JavaScript官方文档(二十)之图形和要素图层——①Graphics概述
原文地址:ArcGIS API For JavaScript官方文档(二十)之图形和要素图层——①Graphics概述 ArcGIS JavaScript API允许在地图上绘制graphic(图形) ...
- Spark官方文档 - 中文翻译
Spark官方文档 - 中文翻译 Spark版本:1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 引入Spark(Linki ...
随机推荐
- Hadoop基础原理
Hadoop基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 业内有这么一句话说:云计算可能改变了整个传统IT产业的基础架构,而大数据处理,尤其像Hadoop组件这样的技术出 ...
- 转:RAC中比较replay, replayLast, and replayLazily
A co-worker recently asked me about the difference between -replay, -replayLast, and -replayLazily i ...
- Python之路,Day2 - Python基础,列表,循环
1.列表练习name0 = 'wuchao'name1 = 'jinxin'name2 = 'xiaohu'name3 = 'sanpang'name4 = 'ligang' names = &quo ...
- SQL分页数据重复问题
对于关系数据库来说,直接写SQL拉数据在列表中显示是很常用的做法.但如此便带来一个问题:当数据量大到一定程度时,系统内存迟早会耗光.另外,网络传输也是问题.如果有1000万条数据,用户想看最后一条,这 ...
- 使用JavaScript 修改浏览器 URL 地址栏
现在的浏览器里,有一个十分有趣的功能,你可以在不刷新页面的情况下修改浏览器URL;在浏览过程中.你可以将浏览历史储存起来,当你在浏览器点击后退按钮的时候,你可以冲浏览历史上获得回退的信息,这听起来并不 ...
- 悲催的IE6 七宗罪大吐槽(带解决方法)第三部分
五:文字溢出bug(注释bug) 1.在以下情况下将会引起文字溢出bug 一个容器包含2两个具有“float”样式的子容器. 第二个容器的宽度大于父容器的宽度,或者父容器宽度减去第二个容器宽度的值小于 ...
- CSS实现DIV层背景透明而文字不透明
在我们设计制作一些网页的时候可能会用到半透明的效果,首先我们可能会想到用PNG图片处理,当然这是一个不错的办法,唯一的兼容性问题就是ie6 下的BUG,但这也不困难,加上一段js处理就行了.但假如我们 ...
- linux查询进程 kill进程
查询进程 #ps aux #查看全部进程 #ps aux|grep firewall #查询与firewall相关的进程 kill进程一 kill进程pid为711进程: #pkill -9 711 ...
- 【转】 jquery easyui datagrid使用,分页、排序、查询
$('#dg').datagrid({ url: "xxx.ashx", pagination: true, p ...
- python初步学习-python 模块之 sys(持续补充)
sys sys 模块包括了一组非常实用的服务,内含很多函数方法和变量 sys 模块重要函数变量 sys.stdin 标准输出流 sys.stdout 标准输出流 sys.stderr 标准错误流 sy ...