scrapy-redis 更改队列和分布式爬虫
这里分享两个技巧
1.scrapy-redis分布式爬虫
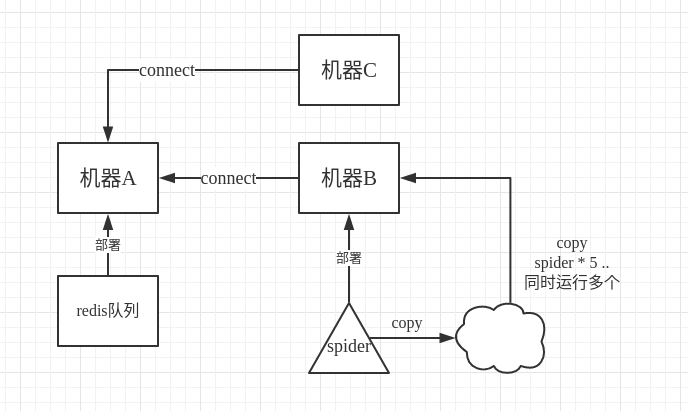
我们知道scrapy-redis的工作原理,就是把原来scrapy自带的queue队列用redis数据库替换,队列都在redis数据库里面了,每次存,取,删,去重,都在redis数据库里进行,那我们如何使用分布式呢,假设机器A有redis数据库,我们在A上把url push到redis里面,然后在机器B上启动scrapy-redis爬虫,在机器B上connect到A,有远程端口可以登入,在爬虫程序里,保存的时候注意启用追加模式,而不是每次保存都删除以前的东西,这样的话,我们可以在B上面多次运行同一个程序。
如图所示,其实连copy都不要,直接另开一个终端,接着运行同样的程序即可。
当然我们也可以在机器C上同样这样运行,所以这就是分布式爬虫。
2.队列不存url改为关键字。
我们的redis队列里保存的是url,正常情况下没毛病,当我们的url不是通过extract网页获取的时候,而是通过构造关键字得到的时候,而且关键字还是很大量的情况下,我们就没有必要在redis里面保存url了,而是直接保存关键字,这样省很大 的内存空间,我们把构造url的任务放到即将要request的时候进行。
当然,这里是改了源码的,如果想这么操作的话,建议在虚拟python环境下进行,安全可靠。
site-packages/scrapy_redis/spiders.py
def make_request_from_data(self, data):
"""Returns a Request instance from data coming from Redis. By default, ``data`` is an encoded URL. You can override this method to
provide your own message decoding. Parameters
----------
data : bytes
Message from redis. """
data=data.split(',')
if data[1]=='':
a = data[0].strip()
vb = {}
vb['word'] = a
vb['sid'] = 'e13f45a56c8e03b5a2262a6fcab43082'
vb['pq'] = vb['word']
url2 = 'https://sug.so.360.cn/suggest?callback=suggest_so&encodein=utf-8&encodeout=utf-8&format=json&fields=word'
data2 = urllib.urlencode(vb)
geturl2 = url2 + '&' + data2
url = bytes_to_str(geturl2, self.redis_encoding)
return self.make_requests_from_url(url)
而在我们的push程序里,是这样子了:
for res in open(file_name,'r'):
client.lpush('%s:start_urls' % redis_key, res+',360')
这里只改写了scrapy_redis/spiders.py文件里的类RedisMixin的 make_request_from_data 函数,人家作者吧接口单独预留了,让我们能够看得很清楚,还是很厉害的。
另外,scrapy-redis框架储存内容的时候,是以list形式 储存的,client.lpush ,redis关于list的操作详见 Redis 列表
scrapy-redis 更改队列和分布式爬虫的更多相关文章
- 基于Redis的三种分布式爬虫策略
前言: 爬虫是偏IO型的任务,分布式爬虫的实现难度比分布式计算和分布式存储简单得多. 个人以为分布式爬虫需要考虑的点主要有以下几个: 爬虫任务的统一调度 爬虫任务的统一去重 存储问题 速度问题 足够“ ...
- 基于docker+redis++urlib/request的分布式爬虫原理
一.整体思路及中心节点的配置 1.首先在虚拟机中运行一个docker,docker中运行的是一个linux系统,里面有我们所有需要的东西,linux系统,python,mysql,redis以及一些p ...
- scrapy分布式爬虫scrapy_redis一篇
分布式爬虫原理 首先我们来看一下scrapy的单机架构: 可以看到,scrapy单机模式,通过一个scrapy引擎通过一个调度器,将Requests队列中的request请求发给下载器,进行页 ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- python3 分布式爬虫
背景 部门(东方IC.图虫)业务驱动,需要搜集大量图片资源,做数据分析,以及正版图片维权.前期主要用node做爬虫(业务比较简单,对node比较熟悉).随着业务需求的变化,大规模爬虫遇到各种问题.py ...
- 基于scrapy-redis的分布式爬虫
一.介绍 1.原生的scrapy框架 原生的scrapy框架是实现不了分布式的,其原因有: 1. 因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- 爬虫--Scrapy-CrawlSpider&基于CrawlSpide的分布式爬虫
CrawlSpider 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调par ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
随机推荐
- [老法新用]使用PADDING-TOP:(PERCENTAGE)实现响应式背景图片
处理响应式布局中背景图片的简单方法是等比例缩放背景图片.我们知道宽度设为百分比的 <img> 元素,其高度会随着宽度的变化自动调整,且其宽高比不变.如果想在背景图片中实现同样的效果,我们 ...
- jdk与jdt
jdk是java的开发环境 ,程序的编译.运行都需要jdk.一个java开发平台,jdk少不了,而编辑器 可以多种多样,除了 eclipse中的JDT,还有独立的jcreate ,或者用记事本以其他加 ...
- Java操作Kafka执行不成功的解决方法,Kafka Broker Advertised.Listeners属性的设置
创建Spring Boot项目继承Kafka,向Kafka发送消息始终不成功.具体项目配置如下: <?xml version="1.0" encoding="UTF ...
- jvm内存模型(运行时数据区)
运行时数据区(runtime data area) jvm定义了几个运行时数据区,这些运行时数据区存储的数据,供开发者的应用或者jvm本身使用.按线程共享与否可以分为线程间共享和线程间独立. 线程间独 ...
- bzoj千题计划156:bzoj1571: [Usaco2009 Open]滑雪课Ski
http://www.lydsy.com/JudgeOnline/problem.php?id=1571 DP不一定全部全状态转移 贪心的舍去一些不合法的反而更容易转移 在一定能力范围内,肯定滑雪所需 ...
- numpy基础整理
记笔记用jupyter实在太方便了,懒得再重新写到博客园上,直接放个链接吧→_→ numpy(一):https://douzujun.github.io/page/%E6%95%B0%E6%8D%AE ...
- SQL分页数据重复问题
对于关系数据库来说,直接写SQL拉数据在列表中显示是很常用的做法.但如此便带来一个问题:当数据量大到一定程度时,系统内存迟早会耗光.另外,网络传输也是问题.如果有1000万条数据,用户想看最后一条,这 ...
- 打包python脚本为exe的坎坷经历, by pyinstaller方法
打包python脚本为exe的坎坷经历, by pyinstaller方法 又应验了那句歌词. 不经历风雨, 怎么见得了彩虹. 安装过程略去不提, 仅提示: pip install pyinstall ...
- Python入门系列教程(五)函数
全局变量 修改全局变量 a=100 def test(): global a a=200 print a 多个返回值 缺省参数 def test3(a,b=1): print a,b test3(a) ...
- TIP协议
1. TIP是什么? CISCO给TIP的定义如下: The TIP protocol specifications describe how to multiplex multiple screen ...