scrapy-redis 更改队列和分布式爬虫
这里分享两个技巧
1.scrapy-redis分布式爬虫
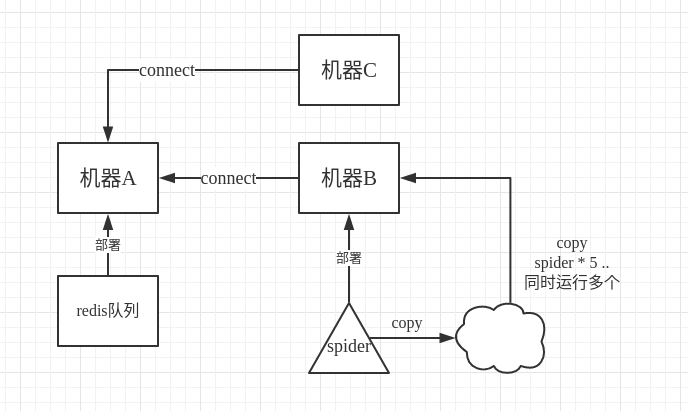
我们知道scrapy-redis的工作原理,就是把原来scrapy自带的queue队列用redis数据库替换,队列都在redis数据库里面了,每次存,取,删,去重,都在redis数据库里进行,那我们如何使用分布式呢,假设机器A有redis数据库,我们在A上把url push到redis里面,然后在机器B上启动scrapy-redis爬虫,在机器B上connect到A,有远程端口可以登入,在爬虫程序里,保存的时候注意启用追加模式,而不是每次保存都删除以前的东西,这样的话,我们可以在B上面多次运行同一个程序。
如图所示,其实连copy都不要,直接另开一个终端,接着运行同样的程序即可。
当然我们也可以在机器C上同样这样运行,所以这就是分布式爬虫。
2.队列不存url改为关键字。
我们的redis队列里保存的是url,正常情况下没毛病,当我们的url不是通过extract网页获取的时候,而是通过构造关键字得到的时候,而且关键字还是很大量的情况下,我们就没有必要在redis里面保存url了,而是直接保存关键字,这样省很大 的内存空间,我们把构造url的任务放到即将要request的时候进行。
当然,这里是改了源码的,如果想这么操作的话,建议在虚拟python环境下进行,安全可靠。
site-packages/scrapy_redis/spiders.py
def make_request_from_data(self, data):
"""Returns a Request instance from data coming from Redis. By default, ``data`` is an encoded URL. You can override this method to
provide your own message decoding. Parameters
----------
data : bytes
Message from redis. """
data=data.split(',')
if data[1]=='':
a = data[0].strip()
vb = {}
vb['word'] = a
vb['sid'] = 'e13f45a56c8e03b5a2262a6fcab43082'
vb['pq'] = vb['word']
url2 = 'https://sug.so.360.cn/suggest?callback=suggest_so&encodein=utf-8&encodeout=utf-8&format=json&fields=word'
data2 = urllib.urlencode(vb)
geturl2 = url2 + '&' + data2
url = bytes_to_str(geturl2, self.redis_encoding)
return self.make_requests_from_url(url)
而在我们的push程序里,是这样子了:
for res in open(file_name,'r'):
client.lpush('%s:start_urls' % redis_key, res+',360')
这里只改写了scrapy_redis/spiders.py文件里的类RedisMixin的 make_request_from_data 函数,人家作者吧接口单独预留了,让我们能够看得很清楚,还是很厉害的。
另外,scrapy-redis框架储存内容的时候,是以list形式 储存的,client.lpush ,redis关于list的操作详见 Redis 列表
scrapy-redis 更改队列和分布式爬虫的更多相关文章
- 基于Redis的三种分布式爬虫策略
前言: 爬虫是偏IO型的任务,分布式爬虫的实现难度比分布式计算和分布式存储简单得多. 个人以为分布式爬虫需要考虑的点主要有以下几个: 爬虫任务的统一调度 爬虫任务的统一去重 存储问题 速度问题 足够“ ...
- 基于docker+redis++urlib/request的分布式爬虫原理
一.整体思路及中心节点的配置 1.首先在虚拟机中运行一个docker,docker中运行的是一个linux系统,里面有我们所有需要的东西,linux系统,python,mysql,redis以及一些p ...
- scrapy分布式爬虫scrapy_redis一篇
分布式爬虫原理 首先我们来看一下scrapy的单机架构: 可以看到,scrapy单机模式,通过一个scrapy引擎通过一个调度器,将Requests队列中的request请求发给下载器,进行页 ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- python3 分布式爬虫
背景 部门(东方IC.图虫)业务驱动,需要搜集大量图片资源,做数据分析,以及正版图片维权.前期主要用node做爬虫(业务比较简单,对node比较熟悉).随着业务需求的变化,大规模爬虫遇到各种问题.py ...
- 基于scrapy-redis的分布式爬虫
一.介绍 1.原生的scrapy框架 原生的scrapy框架是实现不了分布式的,其原因有: 1. 因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- 爬虫--Scrapy-CrawlSpider&基于CrawlSpide的分布式爬虫
CrawlSpider 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调par ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
随机推荐
- 用Anaconda安装本地python包
Anaconda确实带来了很多方便,但是之前也过多的依赖了conda自带的一键下载python包的功能.这不,这几天突然要用FastFM这个包,无奈conda里没有,于是只能从github下载下来,实 ...
- 自动化工具制作PASCAL VOC 数据集
自动化工具制作PASCAL VOC 数据集 1. VOC的格式 VOC主要有三个重要的文件夹:Annotations.ImageSets和JPEGImages JPEGImages 文件夹 该文件 ...
- Django中url()
使用django的时候,如果我们希望我们编写的view可以被正常访问,就需要配置url. 在django的官方文档中,url()的例子如下: polls/urls.py from django.con ...
- 说明你javascript写的很烂的5个问题
Javascript在互联网上名声很臭,但你又很难再找到一个像它这样如此动态.如此被广泛使用.如此根植于我们的生活中的另外一种语言.它的低学习门槛让很多人都称它为学前脚本语言,它另外一个让人嘲笑的东西 ...
- 49、多线程创建的三种方式之继承Thread类
继承Thread类创建线程 在java里面,开发者可以创建线程,这样在程序执行过程中,如果CPU空闲了,就会执行线程中的内容. 使用Thread创建线程的步骤: 1.自定义一个类,继承java.lan ...
- 【译】第四篇 Integration Services:增量加载-Updating Rows
本篇文章是Integration Services系列的第四篇,详细内容请参考原文. 回顾增量加载记住,在SSIS增量加载有三个使用案例:1.New rows-add rows to the dest ...
- faskclick
PC网页上的大部分操作都是用鼠标的,即响应的是鼠标事件,包括mousedown.mouseup.mousemove和click事件.一次点击行为,事件的触发过程为:mousedown -> ...
- spfa+floyed+最长路+差分约束系统(F - XYZZY POJ - 1932)(题目起这么长感觉有点慌--)
题目链接:https://cn.vjudge.net/contest/276233#problem/F 题目大意:给你n个房子能到达的地方,然后每进入一个房子,会消耗一定的生命值(有可能是负),问你一 ...
- [转]STL 容器一些底层机制
1.vector 容器 vector 的数据安排以及操作方式,与 array 非常相似.两者的唯一区别在于空间的运用的灵活性.array 是静态空间,一旦配置了就不能改变,vector 是动态数组.在 ...
- [LeetCode] #112 #113 #437 Path Sum Series
首先要说明二叉树的问题就是用递归来做,基本没有其他方法,因为这数据结构基本只能用递归遍历,不要把事情想复杂了. #112 Path Sum 原题链接:https://leetcode.com/prob ...