day5-import机制详述
一、概述
但凡稍微复杂一些的python程序,都不可避免地需要import一些内置模块或外部模块,当然也有可能import进来一个package,java语言中也经常见到各种import打头,可见其用法很常见了。今天就来讲述一下python中import代码里面那些不为人知的故事。
二、模块和包的概念
目前接触到的python中的import,仅限于import模块或import包,如果有其他对象可以被import,后续再另行补充。
- 模块
用来从逻辑组织一段python代码(变量,函数,类,方法),实现某个或某些特定的逻辑功能,本质上就是一个语法ok的.py结尾的python文件。如编写了一个test.py文件,其对应的模块名就是test(去掉后缀)
模块可以分为以下几类:
(1) 内置模块
即标准库,如常用的import os ,import sys等
(2) 开源模块
这个就不赘述了,github上很多
(3) 自定义模块
自己编写的模块文件,实际项目中这种情况应该不少。 - 包
用来从逻辑上组织模块(.py文件)的,本质上是一个目录,但必须包含名为__init__.py文件。
通过pycharm来new一个package时,可以看到实际上只是创建了一个仅仅包含名为__init__.py文件的目录(当然你也可以在这个目录下新建其它的.py文件/模块)
三、import的本质
3.1 import的过程
明确了可以被import的对象(模块和包)的概念后,我们由表及里,看一下import这两种对象的实质:
- import模块
由于模块就是一个具体的.py文件,对应于一段python代码,因此import一个模块的本质是在当前.py文件下,解释执行被import的模块对应的.py文件(对应于一段python代码)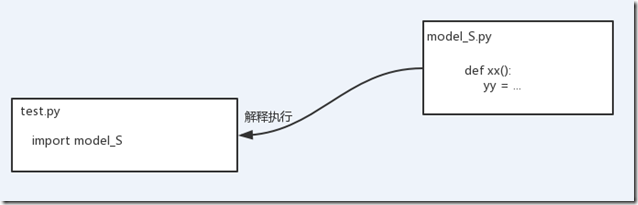
import model_S (model_S=’model_S.py -----> all code’) 相当于把import的模块名作为一个变量,而该变量对应于模块名(.py文件)定义的全部python代码。 - import包
package是一个目录,至少应该包含一个名为__init__.py的文件。import 一个package的过程,本质是执行该包下的__init__.py文件。
3.2 import的路径搜索
上述章节阐述了import一个模块和一个包的过程,细心的同学会发现这里会引入另外一个问题,我们平时在执行一个python程序时,要么是在当前目录下直接以python xx.py形式执行,要么是在某个目录下,通过绝对路径的形式定义python程序的路径来执行,即python absPath/xx.py。也就是说我们需要明确告知解释器我们的程序所在的位置,那么刚刚提到的import的过程,无论是import一个模块,还是import一个包,本质都是在需要import的.py文件中执行另外一个.py文件,而我们在import的时候,并木有明确指定需要被import的模块或包所在的路径(即它们各自所对应的.py文件),这里是不是可以作一个猜想,被import的模块或包是在当前工作目录呢(即需要import的.py文件所在目录)?这里不得不说说import的路径搜索机制了。
在import过程中,解释器要为我们需要import进来的模块或包创建上下文环境,以便正常解释执行他们,这个上下文环境就是解释器的搜索路径,解释器只会在搜索路径下去搜索被import的包或模块。这个搜索路径,就是当前程序的环境变量,即sys.path的输出,这就是import的路径搜索机制。sys.path的输出是一个包含了所有环境变量在内的列表。其中第一个元素就是当前目录,因此import当前工作目录下的模块或包是完全ok的。
1 import sys
2 print(sys.path)
3
4 输出:
5 ['D:\\python\\S13\\Day5', 'D:\\python','C:\\Program Files (x86)\\python3.6.1\\python36.zip', 'C:\\Program Files (x86)\\python3.6.1\\DLLs', 'C:\\Program Files (x86)\\python3.6.1\\lib', 'C:\\Program Files (x86)\\python3.6.1', 'C:\\Program Files (x86)\\python3.6.1\\lib\\site-packages']
import的路径搜索机制,意味着我们要成功import一个模块或包时,它们必须在sys.path输出的路径之一中存在,否则import会失败。还是实际验证一下吧。
我们先来看下当前工作目录和sys.path的输出:
1 import sys,os
2 print(os.getcwd())
3 print('----------------')
4 print(sys.path)
5
6 输出:
7 D:\python\S13\Day5 #当前工作目录
8 ----------------
9 ['D:\\python\\S13\\Day5', 'D:\\python','C:\\Program Files (x86)\\python3.6.1\\python36.zip', 'C:\\Program Files (x86)\\python3.6.1\\DLLs', 'C:\\Program Files (x86)\\python3.6.1\\lib', 'C:\\Program Files (x86)\\python3.6.1', 'C:\\Program Files (x86)\\python3.6.1\\lib\\site-packages']
然后我们在D:\python\S13\Day4目录下有一个hello.py程序:
我们试试导入hello模块的情况:
1 import sys,os
2 print(os.getcwd())
3 print('----------------')
4 print(sys.path)
5
6 import hello
7 say_hello()
8
9 程序输出:
10 D:\python\S13\Day5
11 ----------------
12 ['D:\\python\\S13\\Day5', 'D:\\python', 'C:\\Program Files (x86)\\python3.6.1\\python36.zip', 'C:\\Program Files (x86)\\python3.6.1\\DLLs', 'C:\\Program Files (x86)\\python3.6.1\\lib', 'C:\\Program Files (x86)\\python3.6.1', 'C:\\Program Files (x86)\\python3.6.1\\lib\\site-packages']
13 Traceback (most recent call last):
14 File "D:/python/S13/Day5/test.py", line 9, in <module>
15 import hello
16 ModuleNotFoundError: No module named 'hello' #报错没有hello模块
由于搜索路径sys.path下找不到hello.py文件,因此import后调用它的函数会直接报错。
OK,既然要成功import一个模块或者包意味着它们必须存在于sys,path的路径输出中,那么我们怎么才能成功import一个非同级目录下的模块或者包呢?实际这部分内容在早期的不同目录间的模块调用中已经讲述过,链接http://www.cnblogs.com/linupython/p/7736816.html。既然搜索路径依赖于sys.path的输出,因此我们把需要import进来的模块或包所在的目录,添加到sys.path环境变量中即可为其创建上下文环境来import了。具体可以考虑用list的insert方法或append方法,当然直接使用insert方法插入到列表头部理论上解释器在搜索时会更快找到。
还是通过代码来解决刚刚不能import的问题吧:
1 import sys,os
2 print(os.getcwd())
3 print('----------------')
4 print(sys.path)
5
6 path1 = os.path.dirname(os.path.dirname(__file__))
7 sys.path.insert(0, path1) #把当前文件的父目录的父目录插入到环境变量中
8 print('================')
9 print(sys.path)
10 from Day4 import hello
11 hello.say_hello()
12
13 输出:
14 D:\python\S13\Day5
15 ----------------
16 ['D:\\python\\S13\\Day5', 'D:\\python', 'C:\\Program Files (x86)\\python3.6.1\\python36.zip', 'C:\\Program Files (x86)\\python3.6.1\\DLLs', 'C:\\Program Files (x86)\\python3.6.1\\lib', 'C:\\Program Files (x86)\\python3.6.1', 'C:\\Program Files (x86)\\python3.6.1\\lib\\site-packages']
17 ['D:/python/S13', 'D:\\python\\S13\\Day5', 'D:\\python','C:\\Program Files (x86)\\python3.6.1\\python36.zip', 'C:\\Program Files (x86)\\python3.6.1\\DLLs', 'C:\\Program Files (x86)\\python3.6.1\\lib', 'C:\\Program Files (x86)\\python3.6.1', 'C:\\Program Files (x86)\\python3.6.1\\lib\\site-packages']
18 Hello Python!
但是我们不建议通过insert方式来改变解释器的搜索路径,这是因为解释器的默认搜索路径具有自己的先后逻辑顺序,人为强行破坏这个逻辑顺序,有可能导致程序运行出现非预期结果。这个具体的逻辑顺序如下:
1. 需要import的py文件所在目录(如果是软链接,那么是实际所在目录)或当前目录;
2. 环境变量 PYTHONPATH中列出的目录(类似环境变量 PATH,由用户定义,默认为空,Linux下可通过echo $PYTHONPATH来获取);
3. site 模块被 import 时添加的路径(site 会在运行时被自动 import)。
以上论述引用自https://loggerhead.me/posts/python-de-import-ji-zhi.html#fn:import-site,有部分改编,感谢大神的分享了!
因此还是建议使用sys.path.append方法来增加搜索路径。
四、import的用法
import的用法有好几种,下面来逐一阐述:
- 直接import
可导入单模块或单个包,需要导入多个模块或包时,多个模块或包之间通过逗号分隔即可。这种方式相当于全局导入,即导入执行目标模块或目标包的全部代码,引入了目标模块或包的全部可用方法,但需要通过module名称来引用模块的方法,成员变量,函数,类等。具体形式是:
import A
调用:”A.B”
import A相当于在当前文件中赋值变量A=’A.py的全部代码’
来个最简单的相同目录下的模块调用栗子:
程序结构: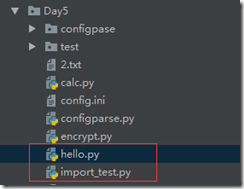
代码:1 ### hello.py
2 # !/usr/bin/env python
3 # -*- coding: utf-8 -*-
4 def say_hi():
5 language = "java"
6 print("Hello, world! Let's play %s" % language)
7
8
9 ### import_test.py
10 # !/usr/bin/env python
11 # -*- coding: utf-8 -*-
12 def say_hi():
13 language = "python"
14 print("Hello, world! Let's play %s" % language)
15
16
17 import hello
18 hello.say_hi()
19 say_hi()
20
21
22 ### 程序输出
23 Hello, world! Let's play java
24 Hello, world! Let's play python目标模块hello中存在与本地文件中同名的函数, 但由于调用时需要添加目标模块作为前缀, 因此并没有引起任何冲突。
- 使用from import方式
from后面跟上模块名或包名,import后面跟上模块里面的类,函数,方法等,可以import *,也可以import某个或某些具体的对象,import多个时依然通过逗号分隔。调用目标模块或包的方法时直接调用即可,无需像import那样还要加上模块名或包名作为前缀:
from A import B
调用: "B”
不建议使用from A import *这种用法,因此from A import B只是引入了目标模块或目标包的某个或某几个方法,并非import第一种情况下的全部引入。另外需要注意的是,由于调用目标模块或包的方法时与调用本地文件中定义的方法没有区别,因此如果存在重复命名的方法,from A import B会污染本地namespace,覆盖本地当前文件中定义的同名方法。
还是使用上面import栗子中的相同代码文件把:1 ### hello.py
2 # !/usr/bin/env python
3 # -*- coding: utf-8 -*-
4 def say_hi():
5 language = "java"
6 print("Hello, world! Let's play %s" % language)
7
8
9 ### import_test.py
10 # !/usr/bin/env python
11 # -*- coding: utf-8 -*-
12 def say_hi():
13 language = "python"
14 print("Hello, world! Let's play %s" % language)
15
16
17 from hello import say_hi #注意导入方式有变化
18 say_hi() #引用函数的方式也变了
19
20 say_hi()
21
22 ### 程序输出
23 Hello, world! Let's play java
24 Hello, world! Let's play java从上面的程序输出结果可看出,解释器只能把重名的函数say_hi()单一的解释为目标模块中调用的函数,本地同名函数已经被覆盖污染了!因此使用这种方式import时千万要注意这个问题!但也不要惊慌,可通过from A import B as C的用法来化解namespace被污染的问题(as即为import的方法启用别名)。
还是示例一下,实践为王:
1 ### hello.py
2 # !/usr/bin/env python
3 # -*- coding: utf-8 -*-
4 __author__ = 'Maxwell'
5
6 def say_hi():
7 language = "java"
8 print("Hello, world! Let's play %s" % language)
9
10
11 ### import_test.py
12 # !/usr/bin/env python
13 # -*- coding: utf-8 -*-
14 __author__ = 'Maxwell'
15
16
17 def say_hi():
18 language = "python"
19 print("Hello, world! Let's play %s" % language)
20
21 from hello import say_hi as say_hello
22 say_hello()
23 say_hi()
24
25 程序输出:
26 Hello, world! Let's play java
27 Hello, world! Let's play python上述程序通过from … import … as …的方式,规避了同名函数的冲突覆盖问题。
实际上from … import的使用方式非常灵活,具体有以下几种:
from 包.[..包] import 模块
或
from 包.模块 import 方法
或
from 模块 import 方法
如果import后面跟的是模块,那么调用时仍然需要使用“模块.方法”来进行,其他情况下直接使用“方法”进行调用即可。
导入包的程序示例:
程序结构图:|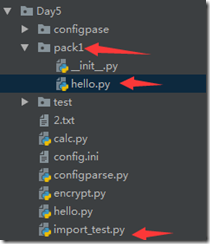
程序代码:1 ### pack1/hello.py
2
3 # !/usr/bin/env python
4 # -*- coding: utf-8 -*-
5 __author__ = 'Maxwell'
6
7 def say_hi():
8 language = "Golang"
9 print("Hello, world! Let's play %s" % language)
10 # pack1包中的init.py为空
11
12
13 ### import_test.py
14 # !/usr/bin/env python
15 # -*- coding: utf-8 -*-
16 __author__ = 'Maxwell'
17
18
19 def say_hi():
20 language = "python"
21 print("Hello, world! Let's play %s" % language)
22
23 ### 以下两种import和调用方式均可
24
25 # from pack1 import hello
26 # hello.say_hi()
27
28 from pack1.hello import say_hi
29 say_hi()
30
31 程序输出:
32 Hello, world! Let's play Golang - 不同目录间模块调用时import和from … import …双拼应用
上面的程序示例都是在同级目录前提下(需要import的文件和被import的模块在同级目录下)展开的,而不同目录间调用模块在实际项目中用的更多。早些时候在写不同目录间模块调用时,功课明显做的不够,没有深入学习import的机制,这里借此机会把不同目录间模块调用的方法再重复一下,提升一下理解的程度。
大致思路是:
(1). 通过os模块逐步获取到被import模块与当前文件(模块)的公共目录
(2). 把第一步获取到的目录追加到sys.path中,为import创建上下文环境
(3). 通过from path import module方式把目标模块import进来,注意这里from后面接的是sys.path中某个元素的子目录
(4). 通过module.function()形式调用目标模块的函数模块
到这里我们基本可以认为这种思路是from import和import的复合双拼式应用,说明import机制在实际应用中的形式非常灵活。
还是来一个实际栗子把:
程序结构: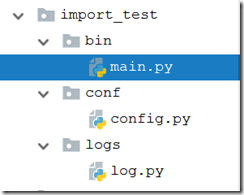
代码:1 ### log.py
2 # !/usr/bin/env python
3 # -*- coding: utf-8 -*-
4 __author__ = 'Maxwell'
5
6 import logging
7
8 def logger(x):
9 logging.warning('[INFO] %s' % x)
10
11 ### config.py
12 # !/usr/bin/env python
13 # -*- coding: utf-8 -*-
14 __author__ = 'Maxwell'
15
16 settings = {'db':'mysql','port':3306, 'master':'true'}
17
18
19 ### main.py
20 # !/usr/bin/env python
21 # -*- coding: utf-8 -*-
22 __author__ = 'Maxwell'
23
24
25 import sys,os
26
27
28 BASEDIR = os.path.dirname(os.path.dirname(__file__))
29 print(BASEDIR)
30 sys.path.append(BASEDIR)
31
32
33 from logs import log
34
35 from conf import config
36 if config.settings['db'] == 'mysql':
37 log.logger('Check mysql config')
38 if config.settings['port'] == 3306 and config.settings['master'] == 'true':
39 log.logger('Check config for mysql master OK!')
40
41
42 ### 运行结果
43 WARNING:root:[INFO] Check mysql config
44 WARNING:root:[INFO] Check config for mysql master OK!
45上面的实例程序是一个很简单的不同目录间的模块调用示例, 结合实际的项目来理解体会会更深刻。
五、import机制总结及优化
关于import机制的要点总结如下:
(1) import的过程
实际上包括两个部分,第一部分类似于shell 的 "source" 命令, 具体说即相当于将被import的module(即python文件)在当前环境下执行一遍;第二部分使被import的成员(变量名, 函数名, 类....)可见,为保证不发生命名冲突, 需要以 module.name 的方式访问导入的成员(不存在命名冲突问题)。import的机制是将目标模块中的对象完整的引入当前模块,但并不引入新的变量名。
(2) "from *** import "的过程
以这种方式导入module时, python会在当前module 的命名空间中新建相应的命名。即, "from t2 import var1" 相当于:
import t2
var1= t2.var1
在此过程中有一个隐含的赋值的过程。from import的机制则是通过引入新的变量名的形式,将目标模块的对象的引用拷贝到新的变量名下的方式引入当前模块。
(3) import和from import的作用机制完全不同,import的范围更广(先全部引入然后再挑选),from … import的对象更确切更有针对性(相当于局部引入,需要哪个就引入哪个)
(4) 重复import或from import多次都只会作用一次
上述内容转自https://blog.csdn.net/lianliange85/article/details/17223429 和 https://www.jianshu.com/p/c82429550dca,有少部分改编。
import的优化目前只有一点:
import的范围更广(先全部引入然后再挑选),from … import的对象更确切更有针对性(相当于局部引入,需要哪个就引入哪个),因此对于需要重复调用模块中方法的情况,通过from import方式可以优化代码执行速度(避免过多引入),但需要注意命名覆盖污染问题。
附录:import机制其他参考资料
http://blog.sina.com.cn/s/blog_c612638e0101q8kc.html
https://loggerhead.me/posts/python-de-import-ji-zhi.html
https://www.cnblogs.com/Cirgo/p/8417490.html
day5-import机制详述的更多相关文章
- python 的import机制2
http://blog.csdn.net/sirodeng/article/details/17095591 python 的import机制,以备忘: python中,每个py文件被称之为模块, ...
- JAVA package与import机制
JAVA package与import机制 http://files.cnblogs.com/files/misybing/JAVA-package-and-import.pdf import org ...
- 理解使用static import 机制(转)
J2SE 1.5里引入了“Static Import”机制,借助这一机制,可以用略掉所在的类或接口名的方式,来使用静态成员.本文介绍这一机制的使用方法,以及使用过程中的注意事项. 在Java程序中,是 ...
- 关于Python的import机制原理
很多人用过python,不假思索地在脚本前面加上import module_name,但是关于import的原理和机制,恐怕没有多少人真正的理解.本文整理了Python的import机制,一方面自己总 ...
- 理解使用static import 机制
J2SE 1.5里引入了“Static Import”机制,借助这一机制,可以用略掉所在的类或接口名的方式,来使用静态成员.本文介绍这一机制的使用方法,以及使用过程中的注意事项. 在Java程序中,是 ...
- 从一个简单的例子谈谈package与import机制
转,原文:http://annie09.iteye.com/blog/469997 http://blog.csdn.net/gdsy/article/details/398072 这两篇我也不知道到 ...
- 深入探讨 Python 的 import 机制:实现远程导入模块
深入探讨 Python 的 import 机制:实现远程导入模块 所谓的模块导入( import ),是指在一个模块中使用另一个模块的代码的操作,它有利于代码的复用. 在 Python 中使用 ...
- java的package和import机制
在说package.import机制前我们先来了解下java的CLASSPATH. CLASSPATH顾名思义就是class的路径,当我们在系统中运行某个java程序时,它就会告诉系统在这些地方寻找这 ...
- 初窥 Python 的 import 机制
本文适合有 Python 基础的小伙伴进阶学习 作者:pwwang 一.前言 本文基于开源项目: https://github.com/pwwang/python-import-system 补充扩展 ...
随机推荐
- IOS系统推送原理
IOS推送大致原理如下图 1.Provider:就是为指定IOS设备应用程序提供Push的服务器,(如果IOS设备的应用程序是客户端的话,那么Provider可以理解为服务端[消息的发起者]): 2. ...
- CIFAR和SVHN在各CNN论文中的结果
CIFAR和SVHN结果 加粗表示原论文中该网络的最优结果. 可以看出DenseNet-BC优于ResNeXt优于DenseNet优于WRN优于FractalNet优于ResNetv2优于ResNet ...
- Java并发编程之CountDownLatch的用法
一.含义 CountDownLatch类位于java.util.concurrent包下,利用它可以实现类似计数器的功能.CountDownLatch是一个同步的辅助类,它可以允许一个或多个线程等待, ...
- pom.xml文件报错:web.xml is missing and <failOnMissingWebXml> is set to true
这个错误原因是因为项目无法加载到web.xml,所以需要配置web项目的目录.具体解决,配置步骤如下: 1.右键项目属性,配置项目目录 /src/main/webapp,如果没有,新增一条 2.配置 ...
- [转]关于Navicat和MYSQL字符集不统一出现的中文乱码问题
原文链接:关于Navicat和MYSQL字符集不统一出现的中文乱码问题 最近遇到一串关于MYSQL中文乱码的问题,问题背景是这样的: 在此之前,服务器上安装好MySQL之后就立马重新配置了字符集为ut ...
- Python面试题之Python反射机制
0x00 前言 def f1(): print('f1') def f2(): print('f2') def f3(): print('f3') def f4(): print('f4') a = ...
- CF1157D N Problems During K Days(简单构造)
题目 题目 原数据是水成啥样了,\(<\longrightarrow <=,>=\longrightarrow <=,\)这也能过 被\(hack\)后身败名裂 做法 简单的贪 ...
- pxe基于虚拟机的自启动
环境系统:centos6.4 min版 虚拟机实现:提供的服务器ip为192.168.0.105,桥接 安装dhcp服务: yum -y install dhcp 配置dhcp服务,使能够成功启动: ...
- ECU
ECU(Electronic Control Unit)电子控制单元,又称“行车电脑”.“车载电脑”等.从用途上讲则是汽车专用微机控制器,也叫汽车专用单片机.它和普通的单片机一样,由微处理器(CPU) ...
- Jquery12 Ajax
学习要点: 1.Ajax 概述 2.load()方法 3.$.get()和$.post() 4.$.getScript()和$.getJSON() 5.$.ajax()方法 6.表单序列化 Ajax ...