第12课:Spark Streaming源码解读之Executor容错安全性
一、Spark Streaming 数据安全性的考虑:
- Spark Streaming不断的接收数据,并且不断的产生Job,不断的提交Job给集群运行。所以这就涉及到一个非常重要的问题数据安全性。
- Spark Streaming是基于Spark Core之上的,如果能够确保数据安全可好的话,在Spark Streaming生成Job的时候里面是基于RDD,即使运行的时候出现问题,那么Spark Streaming也可以借助Spark Core的容错机制自动容错。
- 对Executor容错主要是对数据的安全容错
- 为啥这里不考虑对数据计算的容错:计算的时候Spark Streaming是借助于Spark Core之上的容错的,所以天然就是安全可靠的。
Executor容错方式:
1. 最简单的容错是副本方式,基于底层BlockManager副本容错,也是默认的容错方式。
2.WAL日志方式
3. 接收到数据之后不做副本,支持数据重放,所谓重放就是支持反复读取数据。
BlockManager备份:
- 默认在内存中两份副本,也就是Spark Streaming的Receiver接收到数据之后存储的时候指定StorageLevel为MEMORY_AND_DISK_SER_2,底层存储是交给BlockManager,BlockManager的语义确保了如果指定了两份副本,一般都在内存中。所以至少两个Executor中都会有数据。

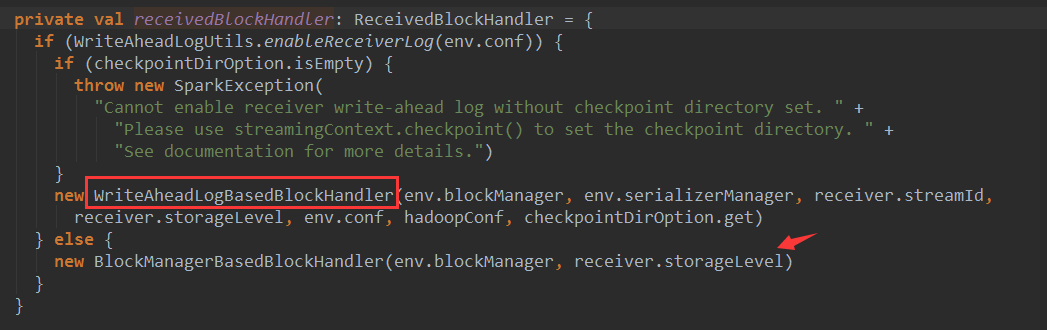

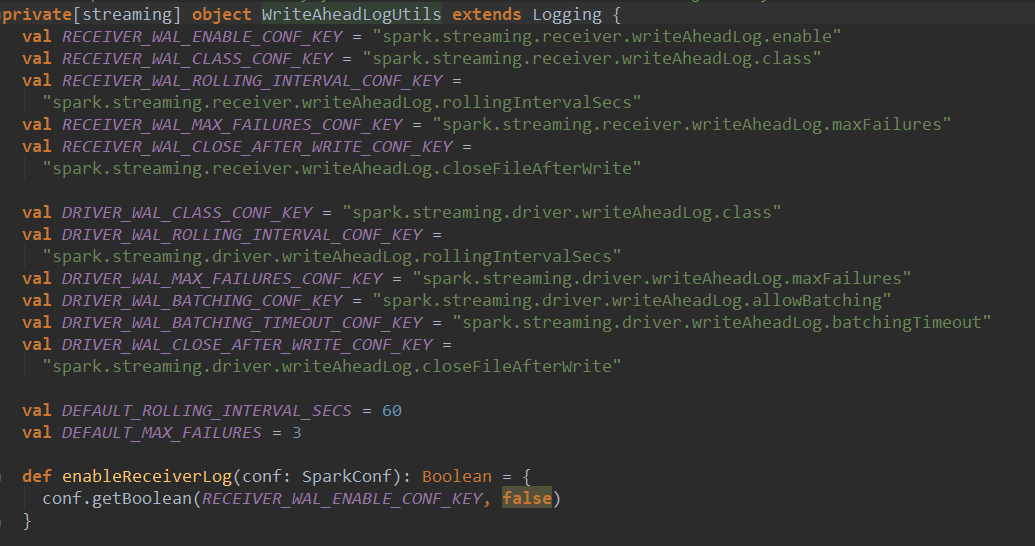
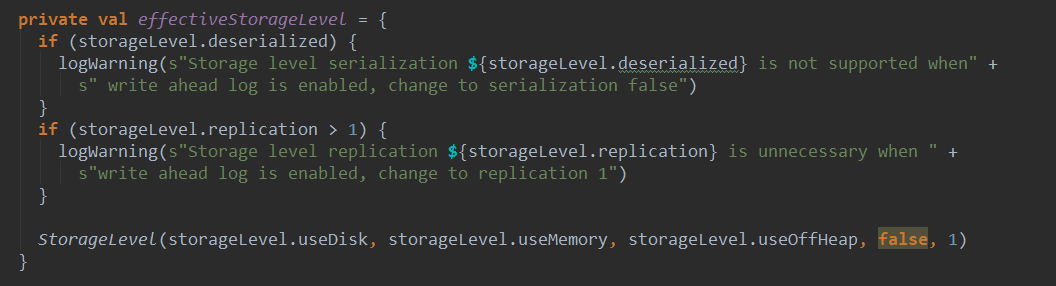

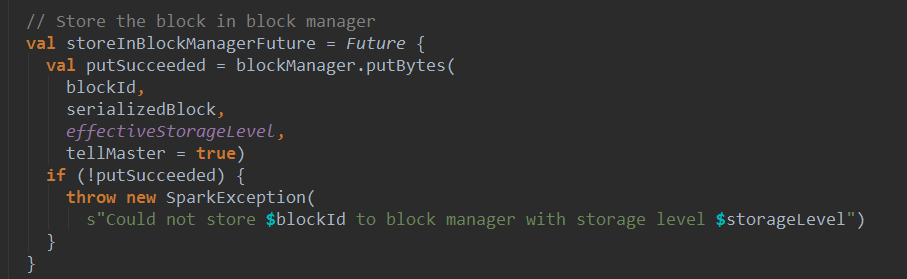

WAL写数据的时候是顺序写,数据不可修改,所以读的时候只需要按照指针(也就是要读的record在那,长度是多少)读即可。所以WAL的速度非常快。浏览一下WriteAheadLog,他是一个抽象类: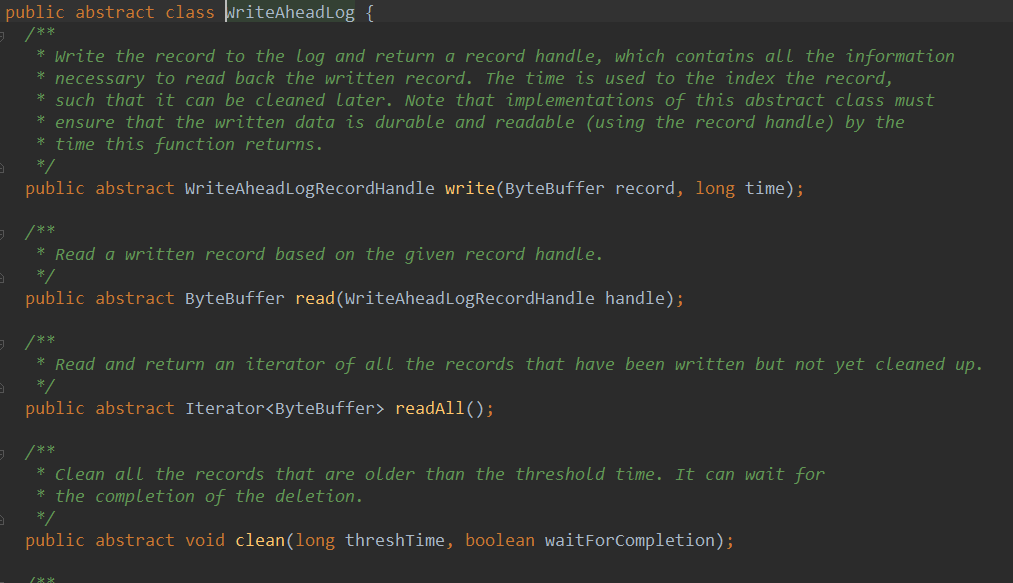
看一下WriteAheadLog的一个实现类FileBasedWriteAheadLog的write方法: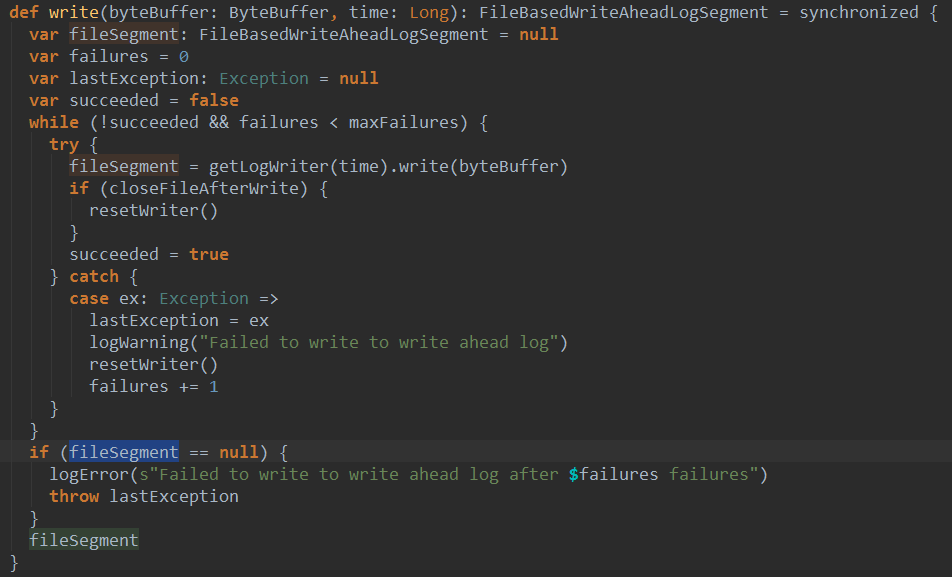
根据不同时间获取不同Writer将序列化结果写入文件,返回一个FileBasedWriteAheadLogSegment类型的对象fileSegment。
读数据:
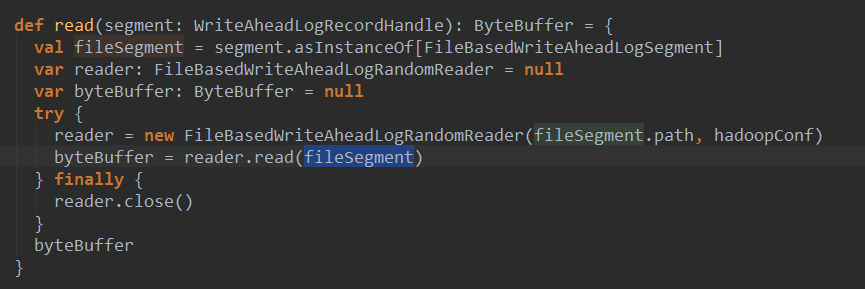
其中创建了一个FileBaseWriteAheadLogRandomReader对象,然后调用了该对象的read方法:

支持数据重放。
在实际的开发中直接使用Kafka,因为不需要容错,也不需要副本。
Kafka有Receiver方式和Direct方式
Receiver方式:是交给Zookeeper去管理数据的,也就是偏移量offSet.如果失效后,Kafka会基于offSet重新读取,因为处理数据的时候中途崩溃,不会给Zookeeper发送ACK,此时Zookeeper认为你并没有消息这个数据。但是在实际中越来用的越多的是Direct的方式直接操作offSet.而且还是自己管理offSet.
- DirectKafkaInputDStream会去查看最新的offSet,并且把offSet放到Batch中。
- 在Batch每次生成的时候都会调用latestLeaderOffsets查看最近的offSet,此时的offSet就会与上一个offSet相减获得这个Batch的范围。这样就可以知道读那些数据。
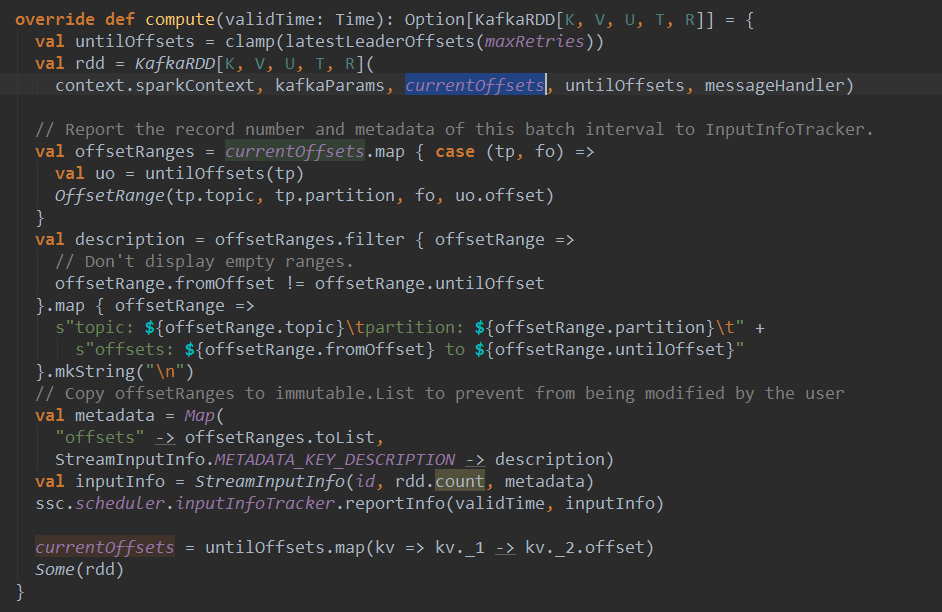
protected final def latestLeaderOffsets(retries: Int): Map[TopicAndPartition, LeaderOffset] = {
val o = kc.getLatestLeaderOffsets(currentOffsets.keySet)
// Either.fold would confuse @tailrec, do it manuallyif (o.isLeft) {
val err = o.left.get.toString
if (retries <= 0) {
throw new SparkException(err)
} else {
log.error(err)
Thread.sleep(kc.config.refreshLeaderBackoffMs)
latestLeaderOffsets(retries - 1)
}
} else {
o.right.get
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
第12课:Spark Streaming源码解读之Executor容错安全性的更多相关文章
- Spark Streaming源码解读之Executor容错安全性
本期内容 : Executor的WAL 消息重放 数据安全的角度来考虑整个Spark Streaming : 1. Spark Streaming会不断次序的接收数据并不断的产生Job ,不断的提交J ...
- Spark Streaming源码解读之Driver容错安全性
本期内容 : ReceivedBlockTracker容错安全性 DStreamGraph和JobGenerator容错安全性 Driver的安全性主要从Spark Streaming自己运行机制的角 ...
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- 15、Spark Streaming源码解读之No Receivers彻底思考
在前几期文章里讲了带Receiver的Spark Streaming 应用的相关源码解读,但是现在开发Spark Streaming的应用越来越多的采用No Receivers(Direct Appr ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming源码解读之生成全生命周期彻底研究与思考
本期内容 : DStream与RDD关系彻底研究 Streaming中RDD的生成彻底研究 问题的提出 : 1. RDD是怎么生成的,依靠什么生成 2.执行时是否与Spark Core上的RDD执行有 ...
- Spark Streaming源码解读之Job动态生成和深度思考
本期内容 : Spark Streaming Job生成深度思考 Spark Streaming Job生成源码解析 Spark Core中的Job就是一个运行的作业,就是具体做的某一件事,这里的JO ...
随机推荐
- bzoj 1513 POI2006 Tet-Tetris 3D 二维线段树+标记永久化
1511: [POI2006]OKR-Periods of Words Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 351 Solved: 220[S ...
- dfs.datanode.du.reserved 预留空间不生效的问题
生产环境(cdh5.5.1)遇到一个问题:已经设置 dfs.datanode.du.reserved预留空间为20G,但是磁盘仍然被写满了. 当挂载磁盘作为datanode的存储空间,如果磁盘大小为2 ...
- Python使用redis介绍
一.Redis的介绍 redis是业界主流的key-value nosql 数据库之一.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).se ...
- Jenkins+SVN+Maven发布项目
一.安装jenkins插件 登入Jenkis后,安装几个插件: Maven Integration plugin # 没有这个插件,不能创建maven项目 Subversion Plug-in Pub ...
- Kubernetes 1.5部署sonarqube
前面几篇博文我们一直在说kubernetes的基础环境的安装及部署.在基础环境部署完成以后,我们开始尝试使用kubernetes来管理我们的应用.本篇博文通过一个简单的示例来向大家展示如何通过depl ...
- AngularJs附件上传下载
首先:angular-file-upload 是一款轻量级的 AngularJS 文件上传工具,为不支持浏览器的 FileAPI polyfill 设计,使用 HTML5 直接进行文件上传. 第一步: ...
- gcd的性质+分块 Bzoj 4028
4028: [HEOI2015]公约数数列 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 865 Solved: 311[Submit][Statu ...
- Python学习笔记(二十九)ThreadLocal
import threading #创建全局ThreadLocal对象: local_school = threading.local() def process_student(): #获取当前线程 ...
- Linux Shell 程序调试
Linux Shell 程序调试 Shell程序的调试是通过运行程序时加入相关调试选项或在脚本程序中加入相关语句,让shell程序在执行过程中显示出一些可供参考的“调试信息”.当然,用户也可以在she ...
- SMTP暴力破解
这里实现一个SMTP的暴力破解程序,实验搭建的是postfix服务器,猜解用户名字典(user.txt)和密码字典(password.txt)中匹配的用户名密码对, 程序开发环境是: WinXP VC ...