【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习
17.1 大型数据集的学习 Learning With Large Datasets
如果有一个低方差的模型, 通常通过增加数据集的规模,可以获得更好的结果。

但是如果数据集特别大,则首先应该检查这么大规模是否真的必要,也许只用 1000个训练集也能获得较好的效果,可以绘制学习曲线来帮助判断。

17.2 随机梯度下降法 Stochastic Gradient Descent
如果必须使用一个大规模的训练集,则可以尝试使用随机梯度下降法(SGD)来代替批量梯度下降法。
随机梯度下降算法 则首先对训练集随机“洗牌”,然后在每一次计算之后便更新参数 θ

在批量梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但 SGD 不是每一步都是朝着”正确”的方向迈出的。因此虽然会逐渐走向全局最小值的位置,但可能无法到达最小值点,而是在附近徘徊。不过很多时候这已经足够了。

17.3 小批量梯度下降 Mini-Batch Gradient Descent
小批量梯度下降算法,介于批量梯度下降算法和随机梯度下降算法之间,每计算常数b次训练实例,更新一次参数 θ 。
通常会令 b 在 2-100 之间。小批量梯度下降的好处在于可以用向量化的方式来循环b个训练实例,如果用的线性代数函数库能支持平行处理,那算法的总体表现将与随机梯度下降近似。

17.4 随机梯度下降算法的收敛 Stochastic Gradient Descent Convergence
在批量梯度下降中,可以令代价函数 J 为迭代次数的函数,绘制图表判断梯度下降是否收敛。但是,在大规模的训练集下不现实,因为计算代价太大。
当数据集很大时使用随机梯度下降算法,这时为了检查随机梯度下降的收敛性,我们在每1000次迭代运算后,对最后1000个样本的cost值求一次平均,将这个平均值画到图中。

下面是可能得到的几种图像:
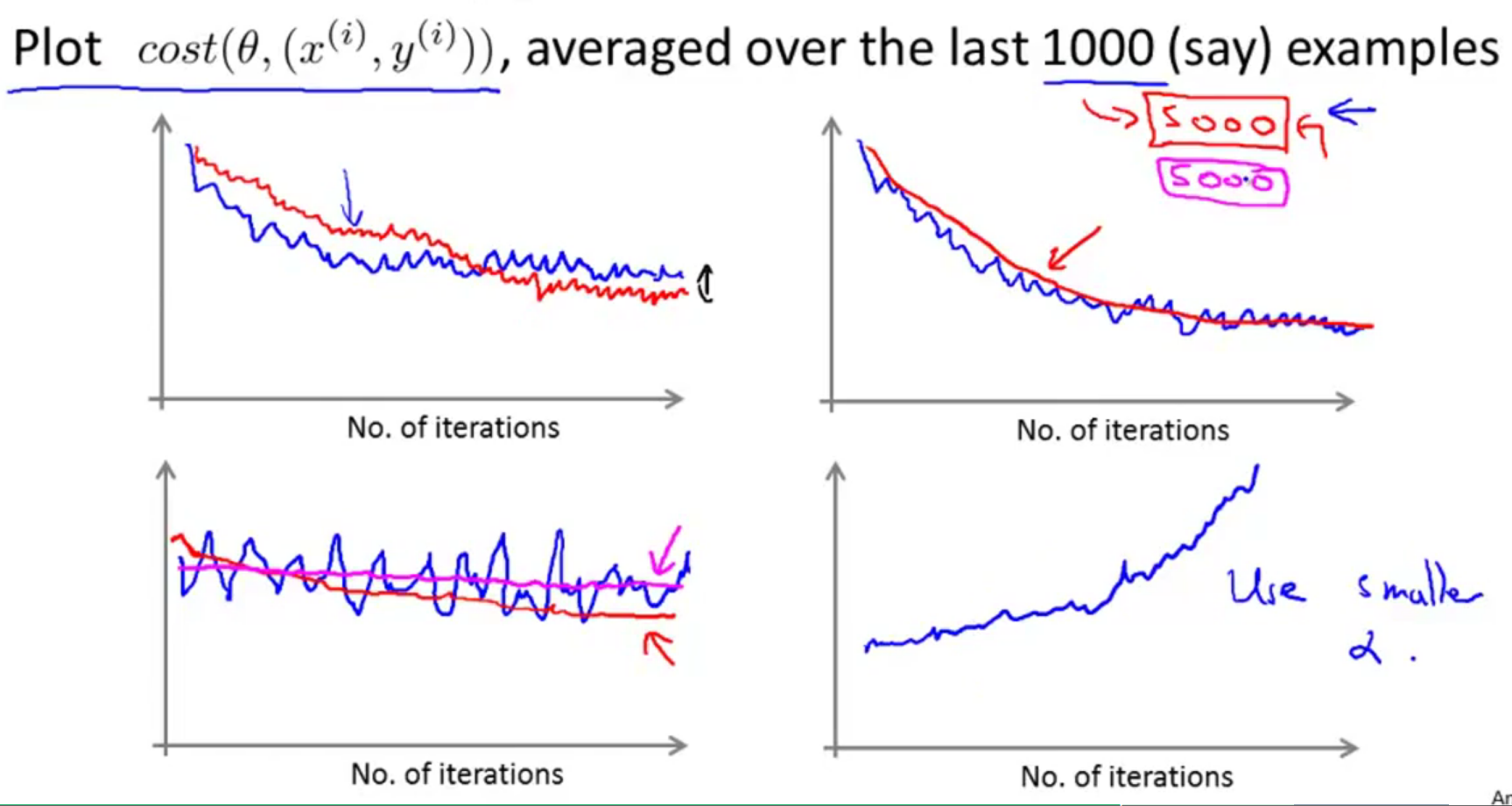
图1:红色线的学习率比蓝色线要小,因此收敛的慢,最后收敛的更好一些。
图2:红线通过对5000次迭代求平均,而不是1000个,得到更加平滑的曲线。
图3:蓝线颠簸不平而且没有明显减少。可以增大α来使得函数更加平缓,也许能使其像红线一样下降;或者可能仍像粉线一样颠簸不平且不下降,说明模型本身可能存在一些错误。
图4:如果曲线正在上升,说明算法发散。应该把学习速率α的值减小。
还可以令学习率随着迭代次数的增加而减小,例如令:
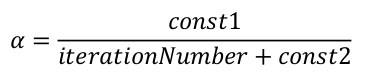
这样,随着不断地靠近全局最小值,学习率会越来越小,迫使算法收敛而非在最小值附近徘徊。
但是通常不需要这样做便能有非常好的效果,对α进行调整所耗费的计算通常不值得。
17.5 在线学习 Online Learning
有一种大规模的机器学习机制,叫做在线学习机制。让我们可以模型化问题。它指的是针对数据流,而非针对离线静态数据集进行学习。例如,许多在线网站都有持续不断的用户流,对于每一个用户,网站希望能不将数据存储到数据库中,便顺利地进行算法学习。
在线学习的算法与随机梯度下降算法有些类似,只对单一的实例进行学习,而非对一个提前定义的训练集进行循环:
Repeat forever (as long as the website is running) {
Get (x, y) corresponding to the current user
θ: = θj − α(hθ(x) − y)xj
(for j = 0: n)
}
一旦对一个数据的学习完成,便可以丢弃它,不需要再存储。这样的好处在于可以针对用户当前行为,不断更新模型以适应该用户。慢慢地调试学习到的假设,将其调节更新到最新的用户行为。

17.6 映射化简和数据并行 Map Reduce and Data Parallelism
映射化简和数据并行对于大规模机器学习问题而言非常重要。之前提到,批量梯度下降算法计算代价非常大。如果能将数据集分配给多台计算机,让每一台计算机处理数据集的一个子集,然后将结果汇总求和,这样的方法叫做映射简化。
例如有 400 个训练实例,可以将批量梯度下降的求和任务分配给 4 台计算机进行处理:
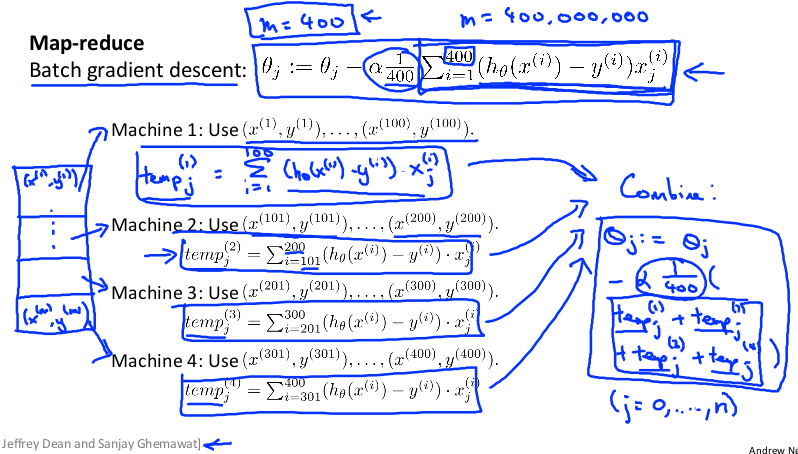

如果任何学习算法能够表达为对训练集函数的求和,那么便能将这个任务分配给多台计算机(或者同一台计算机的不同 CPU 核心),以达到加速处理的目的。例如逻辑回归:

很多高级的线性代数函数库能够利用多核 CPU 的来并行地处理矩阵运算,这也是算法的向量化实现如此重要的缘故(比调用循环快)。

【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习的更多相关文章
- [C12] 大规模机器学习(Large Scale Machine Learning)
大规模机器学习(Large Scale Machine Learning) 大型数据集的学习(Learning With Large Datasets) 如果你回顾一下最近5年或10年的机器学习历史. ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 10—Advice for applying machine learning 机器学习应用建议
Lecture 10—Advice for applying machine learning 10.1 如何调试一个机器学习算法? 有多种方案: 1.获得更多训练数据:2.尝试更少特征:3.尝试更多 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 1_Introduction and Basic Concepts 介绍和基本概念
目录 1.1 欢迎1.2 机器学习是什么 1.2.1 机器学习定义 1.2.2 机器学习算法 - Supervised learning 监督学习 - Unsupervised learning 无 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- 大规模机器学习(Large Scale Machine Learning)
本博客是针对Andrew Ng在Coursera上的machine learning课程的学习笔记. 目录 在大数据集上进行学习(Learning with Large Data Sets) 随机梯度 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 15—Anomaly Detection异常检测
Lecture 15 Anomaly Detection 异常检测 15.1 异常检测问题的动机 Problem Motivation 异常检测(Anomaly detection)问题是机器学习算法 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 16—Recommender Systems 推荐系统
Lecture 16 Recommender Systems 推荐系统 16.1 问题形式化 Problem Formulation 在机器学习领域,对于一些问题存在一些算法, 能试图自动地替你学习到 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 14—Dimensionality Reduction 降维
Lecture 14 Dimensionality Reduction 降维 14.1 降维的动机一:数据压缩 Data Compression 现在讨论第二种无监督学习问题:降维. 降维的一个作用是 ...
随机推荐
- DVD项目
package sy.com.cn;import java.util.*; public class DvdWorker { public static void main(String[]args) ...
- 利用 TypeConverter,转换字符串和各种类型只需写一个函数
本文代码基于 .NET Framework 实现. 本来只想进行简单的配置存储的,不料发现 .NET 的基本类型多达十多种.于是,如果写成下面这样,那代码可就太多了哦: // 注:`Configura ...
- flask第十四篇——重定向
我们都知道京东的url是www.jd.com,但是当你输入www.jingdong.com时候,你会发现地址自动跳转到了www.jd.com,这种技术手段就叫做重定向. 重定向分为永久重定向和临时重定 ...
- 用fiddler设置手机代理
做App测试的朋友可能因为环境的需要,要切换不同的测试环境,这时就需要在自己的电脑上配置好环境,然后在手机上设置代理,用WiFi连自己的电脑,这样一来,手机网络走的就是自己的电脑网络,也就是说,手机的 ...
- ballerina 学习四 如何进行项目结构规划
备注: * ballerina 程序员可以将代码放到一个文件或者一个项目目录 * 一个ballerina program是一个已经编译以及链接的二进制文件 * package是一个包含ba ...
- ORACLE11g 没有控制文件如何通过rman备份恢复数据的详细实战过程
1.副总裁需要裸恢复的严峻现实 集团总部的信息部负责人给我打电话说为了找一年前的记录,所以需要对一年前2015年5月1日的数据进行恢复.而2016年初因为进行迁移,所以有些文件可能丢失,手上只有rma ...
- win7 QT +opencv环境搭建
1.Win7 Qt4.8.5+QtCreator2.8.0+mingw环境参考前博文先搭建 2.下载Cmake2.8.11.2版本,安装.运行 [项目]那编译器选择:MinGW4.4.另外,重新编译O ...
- 【常见Web应用安全问题】---4、Directory traversal
Web应用程序的安全性问题依其存在的形势划分,种类繁多,这里不准备介绍所有的,只介绍常见的一些. 常见Web应用安全问题安全性问题的列表: 1.跨站脚本攻击(CSS or XSS, Cross Si ...
- Oracle修改主键约束
项目需求,有张表,原有三个联合主键,现在需要再加一个字段进去,而恰恰这个字段可以为空的.去数据库捞了一把,还好数据都不为空: SQL> select count(*) from t_wlf_re ...
- linux 文件权限详细说明
在本章前部,当你试图转换到根用户的登录目录时,你收到了以下消息: cd /root bash: /root: Permission denied 这是 Linux 安全功能的一个演示.Linux 和 ...