Parameter Initializations in Deep Learning
全零初始化的问题:
在Linear Regression中,常用的参数初始化方式是全零,因为在做Gradient Descent的时候,各个参数会在输入的各个分量维度上各自更新。更新公式为:

而在Neural Network(Deep Learning)中,当我们将所有的parameters做全零初始化,根据公式:

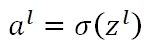
可知,每一层的Zl均为0,如果使用sigmoid activation,则al的值都等于0.5。在反向传播时,误差值
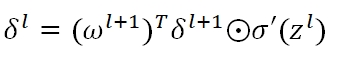
因为有ω在里面,所以导致δ都变成了零,而我们用于做Gradient Descent的梯度
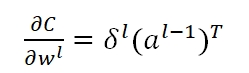
也就通通变为了零,从而,我们的Back propagation算法失效,参数矩阵将始终保持全零的状态,无法更新。
Parameter初始化过小的问题:
首先,Parameter过小,则经过一层层的Sigmoid Function,activation会越来越小,也就是最终的输出结果会非常接近于0。从Sigmoid的图形可以看出,在接近0的图形范围内,函数是类似线性的。所以Parameter初始化过小,会导致神经网络失去非线性功能。此外,在接近0点的部分,Sigmoid Activation的δ'(z)接近于1/4。同样地,在公式中:
随着Backpropagation的进行,δ指数级衰减。下式中的梯度会随着层数的回溯,越来越小,直至消失消失。
Parameter初始化过大的问题:
将导致Z值过大,从Sigmoid和Tanh图形可知,当Z值过大时,激励函数会饱和,其梯度将趋近为0。导致的结果是,参数将无法进行更新,或更新很慢。
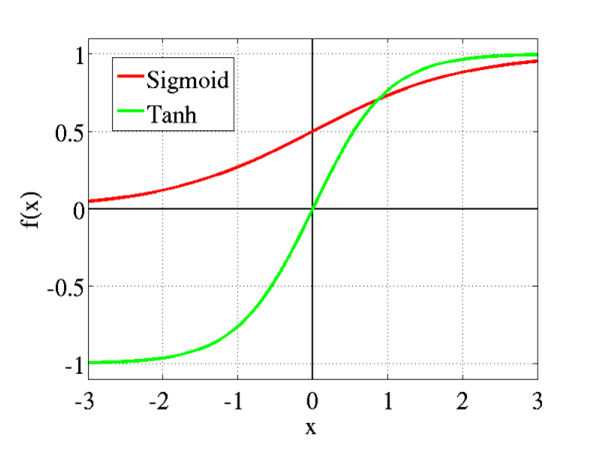
而如果我们通过调整bias,使得各层的z始终为0,则会有梯度爆炸的问题。还是在下式中
各层的δ‘(z)都是1/4,但ω却是很大的值。所以随着Backpropagation的推进,前层的δ会越来越大,如果层数很多,甚至变为NAN。
深度学习中的主流初始化方法有Xavier和He
Xavier Initialization有三种选择,Fan_in:
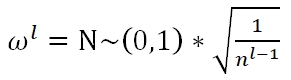
Fan_out:
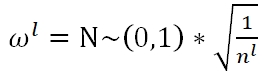
Average:
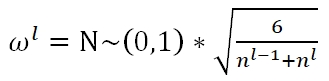
He Initialization:
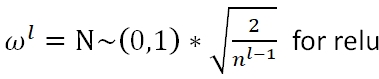
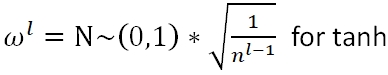
Parameter Initializations in Deep Learning的更多相关文章
- Decision Boundaries for Deep Learning and other Machine Learning classifiers
Decision Boundaries for Deep Learning and other Machine Learning classifiers H2O, one of the leading ...
- Edge Intelligence: On-Demand Deep Learning Model Co-Inference with Device-Edge Synergy
边缘智能:按需深度学习模型和设备边缘协同的共同推理 本文为SIGCOMM 2018 Workshop (Mobile Edge Communications, MECOMM)论文. 笔者翻译了该论文. ...
- A Brief Overview of Deep Learning
A Brief Overview of Deep Learning (This is a guest post by Ilya Sutskever on the intuition behind de ...
- Rolling in the Deep (Learning)
Rolling in the Deep (Learning) Deep Learning has been getting a lot of press lately, and is one of t ...
- 深度学习Deep learning
In the last chapter we learned that deep neural networks are often much harder to train than shallow ...
- Deep learning:五十一(CNN的反向求导及练习)
前言: CNN作为DL中最成功的模型之一,有必要对其更进一步研究它.虽然在前面的博文Stacked CNN简单介绍中有大概介绍过CNN的使用,不过那是有个前提的:CNN中的参数必须已提前学习好.而本文 ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- Deep Learning in a Nutshell: History and Training
Deep Learning in a Nutshell: History and Training This series of blog posts aims to provide an intui ...
- Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:三十三(ICA模型).Deep learning:三十九(ICA模型练习) 实验环境:win7, matlab2015b,16G内存,2T机 ...
随机推荐
- 8、神经网络:表述(Neural Networks: Representation)
8.1 非线性假设 我们之前学的,无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大. 下面是一个例子: 当我们使用x1, x2 的多次项式进行预测时,我们可以应用的很好 ...
- Python自学第二天学习之《元组与字典》
一. 元组:tuple类型,元组一级元素 不能修改 不能增加 不能删除,是有序的. 格式 :tu=(1,2,3,4,5,6) 1.类型转换: #字符串转换成元组 b=“123” c=tuple(b) ...
- 什么是 Python?
Python 是一种编程语言,它有对象.模块.线程.异常处理和自动内存管理,可以加入其他语言的对比. Python 是一种解释型语言,Python 在代码运行之前不需要解释. Python 是动 ...
- [转载]企业级应用架构(NHibernater+Spring.Net+MVC3)
本人已经从事公司两套这类架构系统的开发工作啦!对于这套架构,我惊叹不已!BPS和CMS系统都是采用这套架构.但本人也同时渐渐发现了这套架构有诸多 不足之处,于是本人利用闲暇时光进一步改进了这套架构.新 ...
- go中指针类型的用法小结
代码 // 指针的用法 package main import ( "fmt" ) func main() { var i int = 100 // 输出i的地址 fmt.Prin ...
- 从excel表中生成批量SQL
excel表格中有许多数据,需要将数据导入数据库中,又不能一个一个手工录入,可以生成SQL,来批量操作. ="insert into Log_loginUser (LogID, Logi ...
- 转载——CentOS---网络配置详解
看到一篇关于Centos网络配置很详细的文章,特此复制来.原文网址:http://blog.chinaunix.net/uid-26495963-id-3230810.html 一.配置文件详解在RH ...
- Spring_搭建过程中遇到的问题
先看一下问题: 1.在web.xml中配置Spring 加载Spring mvc的时候配置如下: <!--配置SpringMVC的前端控制器--> <servlet> < ...
- ps:选区的存储及载入
有时候需要把已经创建好的选区存储起来,方便以后再次使用.就要使用选区存储功能. 创建选区后,直接点击右键(限于选取工具)出现的菜单中就“存储选区”项目.也可以使用菜单[选择 存储选区].会出现一个名称 ...
- arm算力
arm 算力运算 MIPS: Million Instructions executed Per SecondDMIPS: Dhrystone Million Instructions execute ...