使用K近邻算法改进约会网站的配对效果
1 定义数据集导入函数
import numpy as np
"""
函数说明:打开并解析文件,对数据进行分类:1 代表不喜欢,2 代表魅力一般,3 代表极具魅力 Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类Label向量
"""
def file2matrix(filename):
# 打开文件
fr = open(filename)
# 读取文件所有内容
array0Lines = fr.readlines()
# 得到文件行数
number0fLines = len(array0Lines)
# 返回一个NumPy矩阵,解析完成的数据:number0fLines行,3列
returnMat = np.zeros((number0fLines, 3))
# 返回的分类标签向量
classLabelVector = []
# 行的索引值
index = 0
for line in array0Lines:
# s.strip(rm), 当rm空时,默认删除空白符(包括'\n', '\r', '\t', ' '),去除的首部和尾部的空白符
line = line.strip()
# 使用s.strip(str = "", num = string, cout(str))将字符串根据 '\t' 分隔符进行切片
listFromLine = line.split('\t')
# 将数据前三列提取出来,存放到returnMat的NumPy矩阵中,也就是特征矩阵
returnMat[index, :] = listFromLine[0:3]
# 根据文本中标记的喜欢的程度进行分类,1 代表不喜欢,2 代表魅力一般,3 代表极具魅力
if listFromLine[-1] == "":
classLabelVector.append(1)
elif listFromLine[-1] == "":
classLabelVector.append(2)
elif listFromLine[-1] == "":
classLabelVector.append(3)
index += 1
# 返回特征矩阵和标签向量
return returnMat, classLabelVector """
函数说明:main函数 Parameters:
无
Returns:
无
"""
if __name__ == '__main__':
# 打开的文件名
filename = 'datingTestSet2.txt'
# 打开并处理数据
datingDataMat, datingLabels = file2matrix(filename)
# 打印
print(datingDataMat)
print(datingLabels)

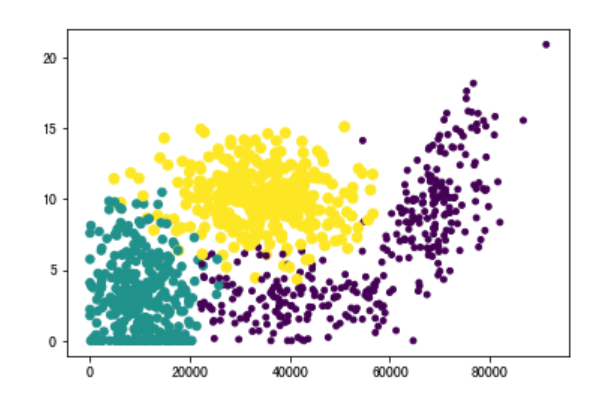
2 分析数据:数据可视化
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0*np.array(datingLabels), 15.0*np.array(datingLabels))
plt.show()
3 数据归一化
import numpy as np
"""
函数说明:对数据进行归一化 Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
def autoNorm(dataSet):
# 获得数据的最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
# 最大值和最小值的范围
ranges = maxVals - minVals
# shape(dataSet)返回dataSet的矩阵行列数
normDataSet = np.zeros(np.shape(dataSet))
# 返回dataSet的行数
m = dataSet.shape[0]
# 原始值减最小值
normDataSet = dataSet - np.tile(minVals, (m, 1))
# 除以最大和最小值的差,得到归一化数据
normDataSet = normDataSet / np.tile(ranges, (m, 1))
# 返回归一化数据结果,数据范围,最小值
return normDataSet, ranges, minVals
if __name__ == '__main__':
normDataSet, ranges, minVals = autoNorm(datingDataMat)
print(normDataSet)
print(ranges)
print(minVals)

4 定义K近邻算法
import numpy as np
import operator """
函数说明:kNN算法,分类器 Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inX, dataSet, labels, k):
# 获取dataSet(训练集)的行数,即有多少个样本
dataSetSize = dataSet.shape[0]
# 将inX纵向重复dataSetSize次,横向重复1次,得到的diffMat矩阵规格与dataSet一致
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 二维特征相减之后求平方。(注:参考求两点间的距离公式)
sqDiffMat = diffMat ** 2
# 接下俩进行求和,将sqDiffMat[0] + sqDiffMat[1],可以使用sum(axis = 1)来完成
sqDistance = sqDiffMat.sum(axis = 1)
# 开方,计算出距离
distances = sqDistance ** 0.5
# 返回distance中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
# 定义一个记录类别次数的字典
classCount = {}
for i in range(k):
# 首先取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
# dict.get(key, default = None), 字典的get()方法,返回指定键的值,如果值不在字典中,返回默认值
# 计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# Python 字典 items() 方法以列表返回可遍历的(键, 值) 元组数组
# key = operator.itemgetter(1)根据字典的值进行排序
# key = operator.itemgetter(0) 根据字典的键进行排序
# reverse降序排序字典
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse=True)
# 返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
5 测试分类器
"""
函数说明:分类器测试函数 Parameters:
无
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
def datingClassTest():
# 打开的文件名
filename = 'datingTestSet2.txt'
# 将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中
datingDataMat, datingLabels = file2matrix(filename)
# 取所有数据的百分之十做为测试集
hoRatio = 0.10
# 数据归一化,返回归一化后的矩阵,数据范围,数据最小值
normMat, ranges, minVals = autoNorm(datingDataMat)
# 获得normMat的行数
m = normMat.shape[0]
# 百分之十的测试数据的个数
numTestVecs = int(m * hoRatio)
# 分类错误计数
errorCount = 0.0 for i in range(numTestVecs):
# 前numTestVecs个数作为测试集,后m - numTestVecs个数作为训练集
classifierResult = classify0(normMat[i, :], normMat[numTestVecs : m, :], datingLabels[numTestVecs : m], 4)
print("分类结果:%d\t真实类别:%d" %(classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("错误率:%f%%" %(errorCount / float(numTestVecs) * 100)) if __name__ == '__main__':
datingClassTest()

6 使用算法构建完整可用系统
"""
函数说明:通过输入一个人的三维特征,进行分类输出 Parameters:
无
Returns:
无
"""
def classifyPerson():
# 输出结果
resultList = ['讨厌', '有些喜欢', '非常喜欢']
# 三维特征用户输入
precentTats = float(input("玩视频游戏所耗时间百分比:"))
ffMiles = float(input("每年获得的飞行常客里程数:"))
iceCream = float(input("每周消费的冰淇淋公升数:"))
# 打开的文件名
filename = 'datingTestSet2.txt'
# 打开并处理数据
datingDataMat, datingLabels = file2matrix(filename)
# 训练集归一化
normMat, ranges, minVals = autoNorm(datingDataMat)
# 生成Numpy数组,测试集
inArr = np.array([ffMiles, precentTats, iceCream])
# 测试集归一化
norminArr = (inArr - minVals) / ranges
# 返回分类结果
classifierResult = classify0(norminArr, normMat, datingLabels, 3)
# 打印结果
print("你可能%s这个人" % (resultList[classifierResult - 1])) if __name__ == "__main__":
classifyPerson()

数据集链接:
链接:https://pan.baidu.com/s/12rbDWeFPzyPuR-Xc0Tjc9A
提取码:1ilc
参考:
1、《机器学习实战》书籍
2、https://cuijiahua.com/blog/2017/11/ml_1_knn.html
3、深度之眼机器学习实战训练营课后作业(http://www.deepshare.net/)
使用K近邻算法改进约会网站的配对效果的更多相关文章
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- 【Machine Learning in Action --2】K-近邻算法改进约会网站的配对效果
摘自:<机器学习实战>,用python编写的(需要matplotlib和numpy库) 海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的 ...
- 机器学习读书笔记(二)使用k-近邻算法改进约会网站的配对效果
一.背景 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可以进行如下分类 不喜欢的人 魅力一般的人 极具魅 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 使用k-近邻算法改进约会网站的配对效果
---恢复内容开始--- < Machine Learning 机器学习实战>的确是一本学习python,掌握数据相关技能的,不可多得的好书!! 最近邻算法源码如下,给有需要的入门者学习, ...
- 机器学习实战1-2.1 KNN改进约会网站的配对效果 datingTestSet2.txt 下载方法
今天读<机器学习实战>读到了使用k-临近算法改进约会网站的配对效果,道理我都懂,但是看到代码里面的数据样本集 datingTestSet2.txt 有点懵,这个样本集在哪里,只给了我一个文 ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
- kNN分类算法实例1:用kNN改进约会网站的配对效果
目录 实战内容 用sklearn自带库实现kNN算法分类 将内含非数值型的txt文件转化为csv文件 用sns.lmplot绘图反映几个特征之间的关系 参考资料 @ 实战内容 海伦女士一直使用在线约会 ...
- k-近邻算法-优化约会网站的配对效果
KNN原理 1. 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系. 2. 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较. a. 计算新 ...
随机推荐
- mplayer - Linux下的电影播放器
概要 mplayer [选项] [ 文件 | URL | 播放列表 | - ] mplayer [全局选项] 文件1 [特定选项] [文件2] [特定选项] mplayer [全局选项] {一组文件和 ...
- mongodb 在 linux 中的安装和简单使用
一.环境介绍 1.mongodb版本: mongodb-linux-x86_64-rhel70-3.2.22 # 点击下载2.linux版本: Ubuntu 18.04.2 LTS 二.安装1.上传 ...
- Windows 开启 winrm
# Windows 开启 winrm ``` Enable-PSRemoting winrm enumerate winrm/config/listener winrm quickconf ...
- Centos 7 Mysql 最大连接数超了问题解决
错误:Can not connect to MySQL server. Too many connections -mysql 1040错误 这是因为对 Mysql 进行访问,未释放的连接数已经达到 ...
- python如何导入自定义文件和模块$PYTHONHOME$\Lib\site-packages 方法
python 中如何引用自己创建的源文件(*.py)呢? 也就是所谓的模块. 假如,你有一个自定义的源文件,文件名:saySomething.py .里面有个函数,函数名:sayHello.如下图: ...
- Java课程作业02
01. 一.设计思想: 第一种使用n!的公式直接计算,利用递归方法求n! 第二种使用递推的公式,利用递归返回求和. 二.程序流程图 三.源代码 import java.util.*;import ja ...
- TodoList案例
我们今天模仿ToDoList进行一个简单的增,删,改,查的操作 可参考官网 http://www.todolist.cn/ 下边直接上代码 import React from 'react'; cl ...
- 使用VisualStudio 开发Arduino
Arduino IDE界面简洁,整体功能还算完善,相比其他编译器明显的不足就是不能进行硬件调试,再就是没有代码提示功能,文件关系不清晰.头文件打开不方便. VisualStudio作为时下最为流行的W ...
- toString和toLocalString
toLocalString()是调用每个数组元素的 toLocaleString() 方法,然后使用地区特定的分隔符把生成的字符串连接起来,形成一个字符串. toString()方法获取的是Strin ...
- kafka完全分布式搭建(2.12版)
1.下载解压 tar -xvf kafka_2.12-1.0.0.tgz 2.进入config目录下,修改server.propeties文件 broker.id=0 #当前server编号 port ...