MySQL执行计划之EXPLAIN基本解释说明
一、EXPLAIN使用潜规则
explain + sql语句
例如: EXPLAIN SELECT * FROM `t_user`;

二、 表头字段详解
(1) id-----> 表的读取顺序
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
它的值有三种情况:
<1> id相同,执行顺序(可以理解成mysql加载表table的顺序)由上而下
<2> id不相同,如果是子查询,id的序号会递增,id值越大,越先被执行
<3> id相同不相同同时存在,id如果相同,可以认为是一组,从上往下执行;在所有组中,id越大越先执行
(2)select_type ----> 数据读取的操作类型
常见值: simple, primary,subquery,derived,union, union result
<1> simple , 简单的select查询,查询中不包含子查询或者union
<2> primary, 查询中若包含任何复杂的子查询部分,最外层查询则被标记为primary
<3> subquery, 在select 或 where 列表中包含了子查询,
<4> derived, 在fromg列表中包含的子查询被标记为derived(衍生),mysql递归执行这些子查询,并把结果放在这个临时表中
<5> union , 若第二个select 出现在union之后,则被标记为union; 若union包含在from子句的子查询中,外层select 标记为derived.
<6> union_result , 从union表获取结果的select.
(3)table
(4) type
常见值: all,index,range,ref,eq_ref,const,system,null
表示查询使用何种类型。 从优到差的顺序: system> const> eq_ref> ref> range> index> all
工作中,查询至少得保证到range级别,最到是ref.
<1> system , 表中只有一个记录(相当于系统表),这是const类型的特例。
<2> const , 通过索引一次就找到了,const用于比较primarykey或者unique索引, 只匹配一行数据,所有查询超级快。 如将主键置于where 列表中,mysql就会将查询转换为一个常量。
<3> eq_ref , 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用于主键与唯一索引扫描。
<4> ref, 非唯一 性索引扫描,返回匹配某个单独值的所有行。 本质上就是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能找到多个符合条件的行,所以它应该属性查找和扫描的混合操作。
<5> range, 只检索指定范围的行,使用一个索引来选择行,key列显示使用了那个索引, 一般就是在where语句中出现了between, < , >, in等查询。 这种范围扫描比全表扫描效率要好,因为它只用开始于某一个值 ,结束于另一个值, 不用扫描全表。
<6> index, Full Index Scan, index 与all的区别在于index只遍历索引树,这肯定比all快,因为索引文件通常比数据文件小。
<7> all , 全表扫描, 数据量上百万就要考虑加索引了。
(5) key/possible_keys -----> 用于判断索引是否失败,到底用了那些索引
possible_keys : 显示可能应用到这张表中的索引 ,一个或多个。 查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
key: 实际使用的索引,如果为NULL,则没有使用索引。查询中若使用了覆盖索引,则该索引仅出现在key列表中。
(6)key_len : 表示索引字段最大可能长度,并非实际使用长度,在精确度相当的情况下,该值越小越好。所以说查询精度与key_len的大小是相悖的。
(7)ref : 显示索引的那一列被使用,如果可能的话,是一个常数。即是哪些列或常量被用于查找索引列上的值。
(8)rows : 多少行被查询,越小越好
(9)Extra 额外信息
<1> Using filesort : mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。 mysql中无法利用索引完成的排序称为“文件排序”... 坑爹的情况,内部产生了二次排序 ,需要优化。

分析: 创建了复合索引 idx_col1_col2_col3 , 但是第一条查询语句使用到的索引列顺序是col1,col3;第二条查询语句使用到的索引列顺序是col1,col2,col3,恰好创建 的索引列全都用到,而且顺序都一致。对比这两条查询语句可以看出using filesort出现的场景了。
<2> Using tempoary : 比Using filesort还要坑爹,新建了一个内部的临时表,常见于order by 和 group by ,
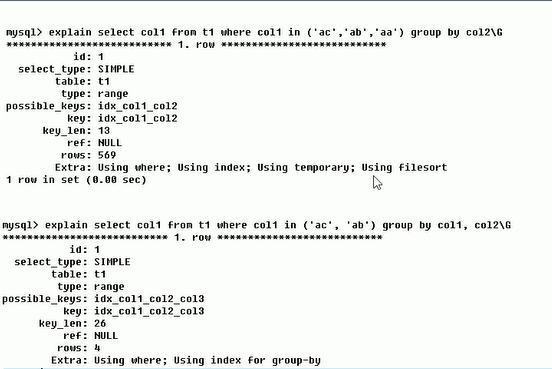
group by 要么不用索引, 要么就必须跟索引列顺序一样, 不然Using tempoary就出现了。
<3> Using index : 表示相应的select 操作中使用了覆盖索引(covering index), 避免访问了表的数据行,效率不错!
如果同时出现了using where ,表明索引被用来执行索引键值的查找; 如果没有同时出现using where ,表明索引用到读取数据而非执行查找操作。

出现了using where , 表示索引被用来执行索引健值的查找, 索引是两列col1,col2 , 而只查找col2 .

没有同时出现using where ,表明索引 被用来读取数据而非执行查找动作。 读取col1,col2的数据就是索引中,所以不用从表中查询了, 只直读索引即可。
补充: 覆盖索引
就是select的数据列只用从索引中就能够取得,不必读取数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件。 换句来讲就是查询列要被所建的索引列所覆盖。 select * 基本不会出现覆盖索引了,。。。。
<4> using where : 表示使用where 过滤
<5> using join buffer : 使用了连接缓存、
<6> impossible where : where 子句的值 总是false ,不能用来获取任何数据。
explain select * from user where gender = '男' and gender = '女';
<7> select tables optimized away 在没有group by 子句的情况下,基于索引优化min/max操作或者对于MyISAM存储引擎优化count(*) 操作,不必等到执行阶段再进行计算,查询执行计划生成阶段即完成优化。
<8> distinct : 优化distinct操作
MySQL执行计划之EXPLAIN基本解释说明的更多相关文章
- MySQL执行计划【explain】详解
本文已经收录到github仓库,仓库用于分享Java相关知识总结,包括Java基础.MySQL.Springboot.mybatis.Redis.rabbitMQ等等,欢迎大家提pr和star! gi ...
- 高性能可扩展MySQL数据库设计及架构优化 电商项目(慕课)第3章 MySQL执行计划(explain)分析
ID:相同就从上而下,不同数字越大越优先
- (转)mysql执行计划分析
转自:https://www.cnblogs.com/liu-ke/p/4432774.html MySQL执行计划解读 Explain语法 EXPLAIN SELECT …… 变体: 1. EX ...
- MySQL执行计划 EXPLAIN参数
MySQL执行计划参数详解 转http://www.jianshu.com/p/7134286b3a09 MySQL数据库中,在SELECT查询语句前边加上“EXPLAIN”或者“DESC”关键字,即 ...
- MySQL 执行计划explain详解
MySQL 执行计划explain详解 2015-08-10 13:56:27 分类: MySQL explain命令是查看查询优化器如何决定执行查询的主要方法.这个功能有局限性,并不总会说出真相,但 ...
- MySQL学习系列2--MySQL执行计划分析EXPLAIN
原文:MySQL学习系列2--MySQL执行计划分析EXPLAIN 1.Explain语法 EXPLAIN SELECT …… 变体: EXPLAIN EXTENDED SELECT …… 将执行 ...
- MySQL学习系列2--MySQL执行计划分析EXPLAIN [原创]
1.Explain语法 EXPLAIN SELECT …… 变体: EXPLAIN EXTENDED SELECT …… 将执行计划“反编译”成SELECT语句,运行SHOW WARNINGS 可 ...
- MySQL执行计划解读
Explain语法 EXPLAIN SELECT …… 变体: 1. EXPLAIN EXTENDED SELECT …… 将执行计划“反编译”成SELECT语句,运行SHOW WARNINGS 可得 ...
- 如何查看MySQL执行计划
在介绍怎么查看MySQL执行计划前,我们先来看个后面会提到的名词解释: 覆盖索引: MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件 包含所有满足查询需要的数据的索引 ...
随机推荐
- 修改oracle数据库字段类型,处理ORA-01439错误
修改表PTLOG的列TYPE的char(1)为varchar(2)类型? 在PTLOG 表新增一列 TYPE_2:ALTER TABLE PTLOG ADD TYPE_2 VARCHAR2(2) de ...
- day33—前端开发的模块化和组件化
转行学开发,代码100天——2018-04-18 今天是记录前端开发中模块化.组件化的知识.关于何为模块化,何为组件化以及为何要如此,目前还是处于一个只可意会不可言传的理解应用阶段. 当然,这样的存在 ...
- 【GDAL】聊聊GDAL的数据模型(二)——Band对象
在GDAL中栅格数据直接参与各种计算的重要对象是Band 摘录官方描述: Raster Band A raster band is represented in GDAL with the GDALR ...
- linux下rpm包安装、配置和卸载mysq
l WIN10下虚拟机:VMware workstation 12 PRO 安装 # 1.查看系统版本 [root@vm-xiluhua][/home/xiluhua]$ cat /etc/red ...
- Flannel - 配置
原文地址 flannel 从 ETCD 中读取配置. 默认情况下,flannel 从 /coreos.com/network/config 中读取配置,可以使用 --etcd-prefix 覆盖. 通 ...
- Vue过滤器:全局过滤器
Vue.js 允许你自定义过滤器,可被用于一些常见的文本格式化. 过滤器可以用在两个地方:双花括号插值和 v-bind 表达式 (后者从 2.1.0+ 开始支持). 过滤器应该被添加在 JavaScr ...
- rsync+sersync实现文件同步
一.目的 A服务器:11.11.11.11 源服务器 B服务器:22.22.22.22 目标服务器,既同步备份的目标 将A服务器的文件同步到B服务器上 二.rsync环境部署 1.关闭selinux, ...
- c语言自带的排序与查找
qsort与bsearch qsort(元素起始地址,元素总数,单个元素的大小,比较函数) bsearch(key元素地址,元素起始地址,元素总数,单个元素的大小,比较函数) 比较函数: 原型为int ...
- HTML设置<table>的<td>横跨3列
第一步:html中 <table> <tr> <td>列一</td> <td>列二</td> <td>列三</ ...
- debain8 安装mysql8
一.下载apt源 https://dev.mysql.com/downloads/repo/apt/ 二.更新apt sudo apt-get update 三.安装mysql sudo apt-ge ...