HBase的访问方式
这里只介绍三种最常用的方式
1.HBase shell
HBase的命令行工具是最简单的接口,主要用于HBase管理
首先启动HBase

帮助
hbase(main):001:0> help
查看HBase服务器状态
hbase(main):001:0> status

查询HBse版本
hbase(main):002:0> version

ddl操作
1.创建一个member表
hbase(main):013:0> create 'table1','tab1_id','tab1_add','tab1_info'

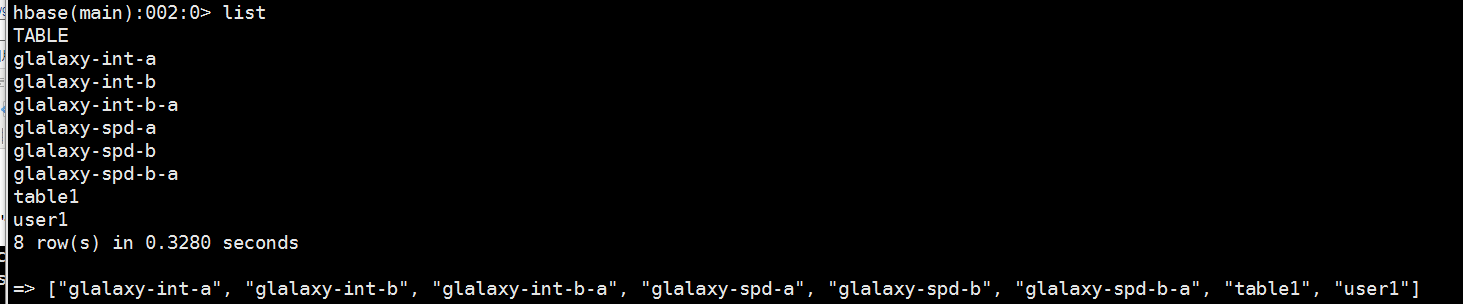
2.查看所有的表
hbase(main):006:0> list
3.查看表结构
hbase(main):007:0> describe 'member'

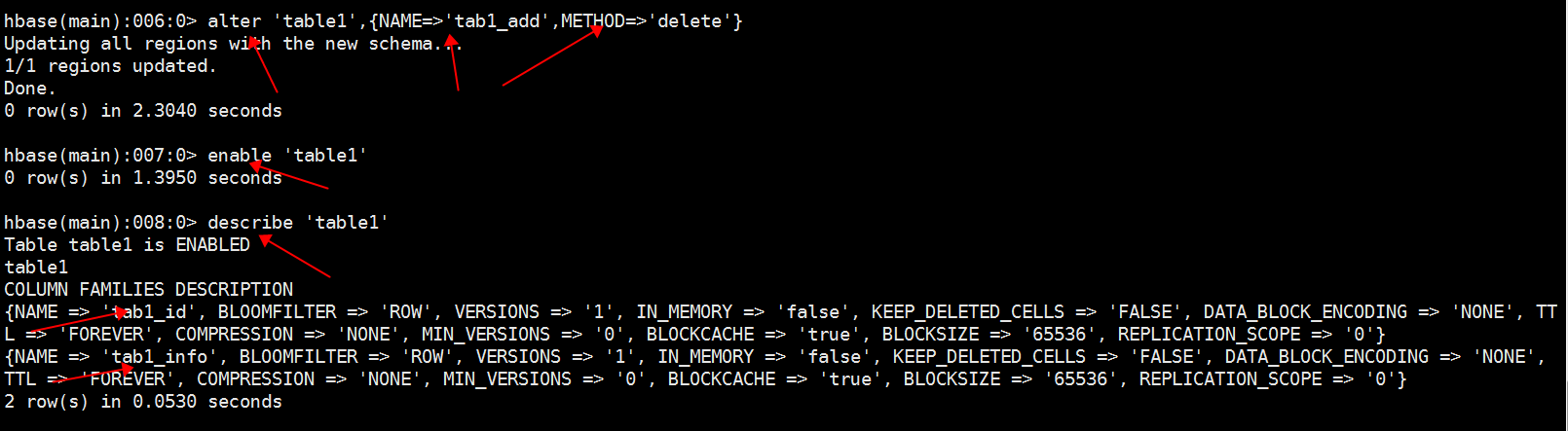
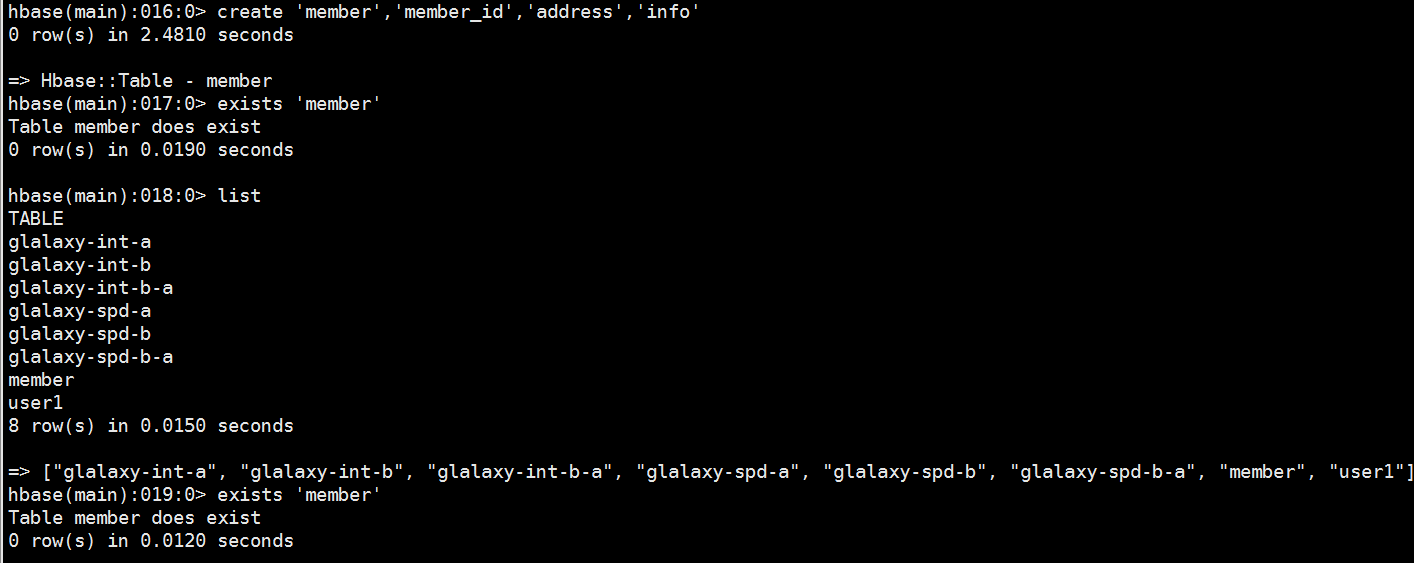
4.删除一个列簇

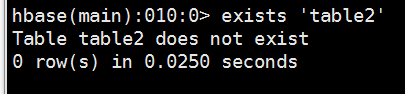
5、查看表是否存在
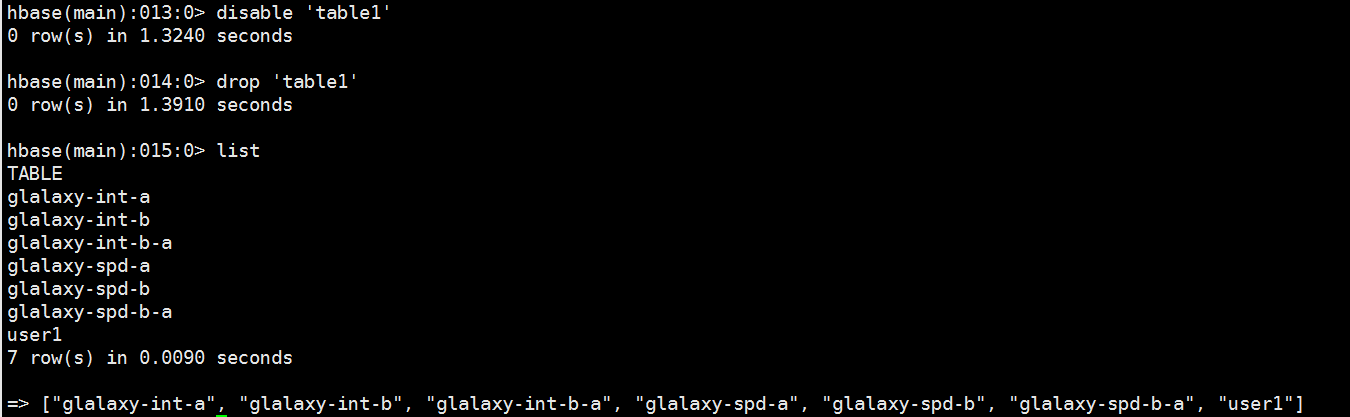
6、判断表是否为"enable"

7、删除一个表
dml操作
1、创建member表
删除一个列簇(一般不超过两个列簇)
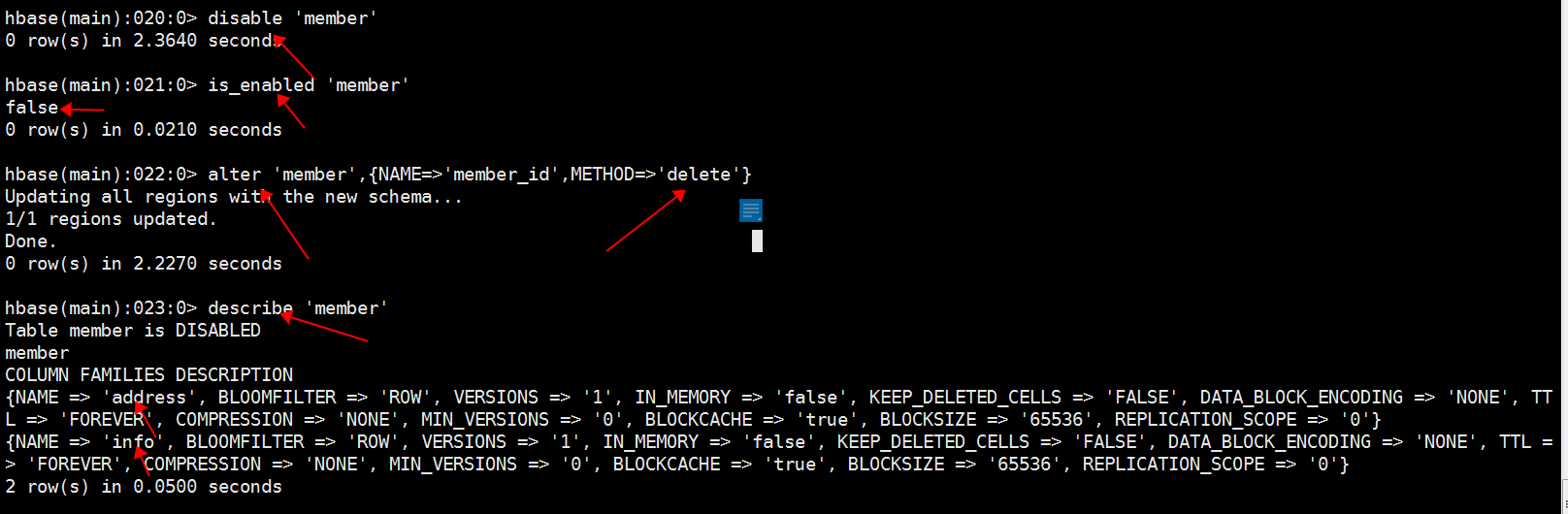

2、往member表插入数据

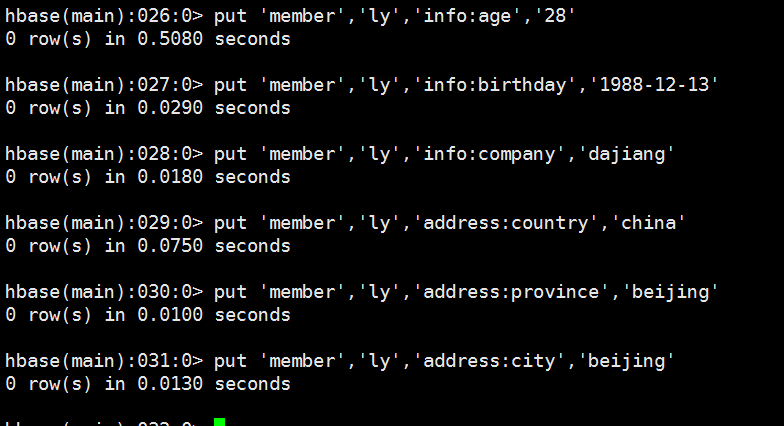
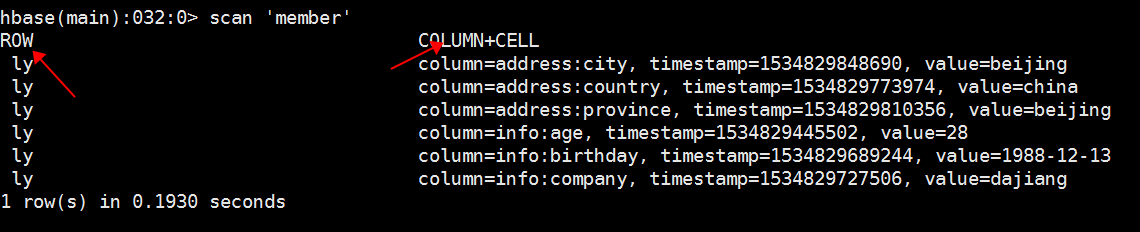
3、扫描查看数据
4、获取数据
获取一个rowkey的所有数据
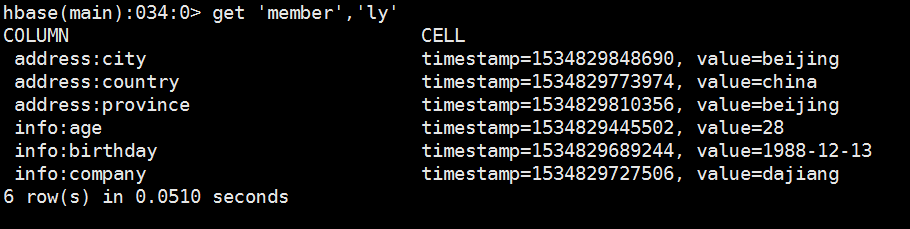
获取一个rowkey,一个列簇的所有数据

获取一个rowkey,一个列簇中一个列的所有数据

5、更新数据
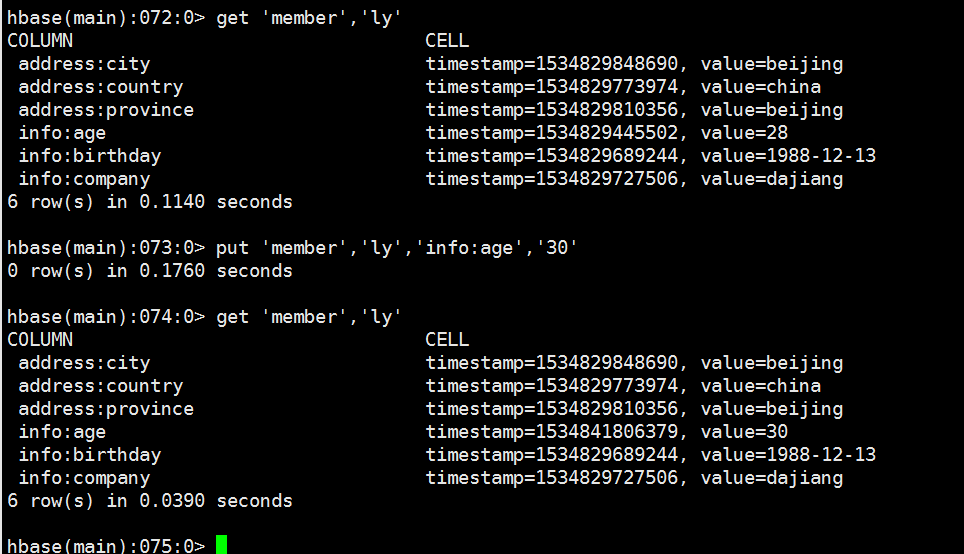
6、删除列簇中其中一列
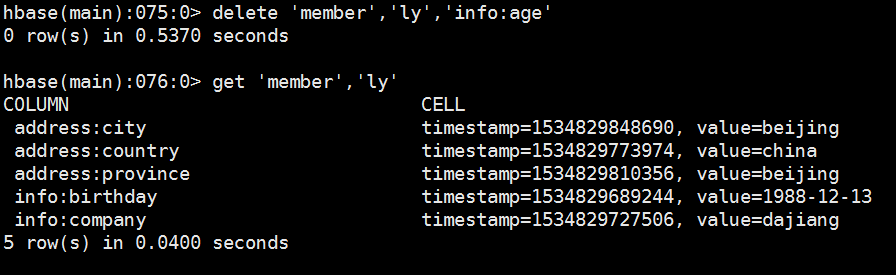
7、统计表中总的行数
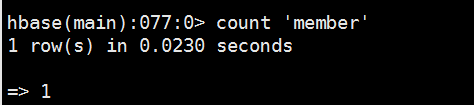
8、清空表中数据
2.java API
最常规且最高效的访问方式
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes; public class HbaseTest {
public static Configuration conf;
static{
conf = HBaseConfiguration.create();//第一步
conf.set("hbase.zookeeper.quorum", "header-2,core-1,core-2");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.master", "header-1:60000");
} public static void main(String[] args) throws IOException{
//createTable("member");
//insertDataByPut("member");
//QueryByGet("member");
QueryByScan("member");
//DeleteData("member");
} /**
* 创建表 通过HBaseAdmin对象操作
*
* @param tablename
* @throws IOException
* @throws ZooKeeperConnectionException
* @throws MasterNotRunningException
*
*/
public static void createTable(String tableName) throws MasterNotRunningException, ZooKeeperConnectionException, IOException {
//创建HBaseAdmin对象
HBaseAdmin hBaseAdmin = new HBaseAdmin(conf);
//判断表是否存在,若存在就删除
if(hBaseAdmin.tableExists(tableName)){
hBaseAdmin.disableTable(tableName);
hBaseAdmin.deleteTable(tableName);
}
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
//添加Family
tableDescriptor.addFamily(new HColumnDescriptor("info"));
tableDescriptor.addFamily(new HColumnDescriptor("address"));
//创建表
hBaseAdmin.createTable(tableDescriptor);
//释放资源
hBaseAdmin.close();
} /**
*
* @param tableName
* @throws IOException
*/
@SuppressWarnings("deprecation")
public static void insertDataByPut(String tableName) throws IOException {
//第二步 获取句柄,传入静态配置和表名称
HTable table = new HTable(conf, tableName); //添加rowkey,添加数据, 通过getBytes方法将string类型都转化为字节流
Put put1 = new Put(getBytes("djt"));
put1.add(getBytes("address"), getBytes("country"), getBytes("china"));
put1.add(getBytes("address"), getBytes("province"), getBytes("beijing"));
put1.add(getBytes("address"), getBytes("city"), getBytes("beijing")); put1.add(getBytes("info"), getBytes("age"), getBytes("28"));
put1.add(getBytes("info"), getBytes("birthdy"), getBytes("1998-12-23"));
put1.add(getBytes("info"), getBytes("company"), getBytes("dajiang")); //第三步
table.put(put1); //释放资源
table.close();
} /**
* 查询一条记录
* @param tableName
* @throws IOException
*/
public static void QueryByGet(String tableName) throws IOException {
//第二步
HTable table = new HTable(conf, tableName);
//根据rowkey查询
Get get = new Get(getBytes("djt"));
Result r = table.get(get);
System.out.println("获得到rowkey:" + new String(r.getRow()));
for(KeyValue keyvalue : r.raw()){
System.out.println("列簇:" + new String(keyvalue.getFamily())
+ "====列:" + new String(keyvalue.getQualifier())
+ "====值:" + new String(keyvalue.getValue()));
}
table.close();
} /**
* 扫描
* @param tableName
* @throws IOException
*/
public static void QueryByScan(String tableName) throws IOException {
// 第二步
HTable table = new HTable(conf, tableName);
Scan scan = new Scan();
//指定需要扫描的列簇,列.如果不指定就是全表扫描
scan.addColumn(getBytes("info"), getBytes("company"));
ResultScanner scanner = table.getScanner(scan);
for(Result r : scanner){
System.out.println("获得到rowkey:" + new String(r.getRow()));
for(KeyValue kv : r.raw()){
System.out.println("列簇:" + new String(kv.getFamily())
+ "====列:" + new String(kv.getQualifier())
+ "====值 :" + new String(kv.getValue()));
}
}
//释放资源
scanner.close();
table.close();
} /**
* 删除一条数据
* @param tableName
* @throws IOException
*/
public static void DeleteData(String tableName) throws IOException {
// 第二步
HTable table = new HTable(conf, tableName); Delete delete = new Delete(getBytes("djt"));
delete.addColumn(getBytes("info"), getBytes("age")); table.delete(delete);
//释放资源
table.close();
} /**
* 转换byte数组(string类型都转化为字节流)
*/
public static byte[] getBytes(String str){
if(str == null)
str = "";
return Bytes.toBytes(str);
}
}
3.MapReduce
直接使用MapReduce作业处理HBase数据
import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; /**
* 将hdfs里面的数据导入hbase
* @author Administrator
*
*/
public class MapReduceWriteHbaseDriver { public static class WordCountMapperHbase extends Mapper<Object, Text,
ImmutableBytesWritable, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
//输出到hbase的key类型为ImmutableBytesWritable
context.write(new ImmutableBytesWritable(Bytes.toBytes(word.toString())), one);
}
}
} public static class WordCountReducerHbase extends TableReducer<ImmutableBytesWritable,
IntWritable, ImmutableBytesWritable>{
private IntWritable result = new IntWritable();
public void reduce(ImmutableBytesWritable key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException{
int sum = 0;
for(IntWritable val : values){
sum += val.get();
}
//put实例化 key代表主键,每个单词存一行
Put put = new Put(key.get());
//三个参数分别为:列簇content 列count 列值为词频
put.add(Bytes.toBytes("content"), Bytes.toBytes("count"), Bytes.toBytes(String.valueOf(sum)));
context.write(key, put);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
String tableName = "wordcount";//hbase数据库表名 也可以通过命令行传入表名args
Configuration conf = HBaseConfiguration.create();//实例化Configuration
conf.set("hbase.zookeeper.quorum", "header-2,core-1,core-2");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.master", "header-1"); //如果表已经存在就先删除
HBaseAdmin admin = new HBaseAdmin(conf);
if(admin.tableExists(tableName)){
admin.disableTable(tableName);
admin.deleteTable(tableName);
} HTableDescriptor htd = new HTableDescriptor(tableName);//指定表名
HColumnDescriptor hcd = new HColumnDescriptor("content");//指定列簇名
htd.addFamily(hcd);//创建列簇
admin.createTable(htd);//创建表 Job job = new Job(conf, "import from hdfs to hbase");
job.setJarByClass(MapReduceWriteHbaseDriver.class); job.setMapperClass(WordCountMapperHbase.class); //设置插入hbase时的相关操作
TableMapReduceUtil.initTableReducerJob(tableName, WordCountReducerHbase.class, job, null, null, null, null, false); //map输出
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(IntWritable.class); //reduce输出
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Put.class); //读取数据
FileInputFormat.addInputPaths(job, "hdfs://header-1:9000/user/test.txt");
System.out.println(job.waitForCompletion(true) ? 0 : 1);
}
}
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* 读取hbse数据存入HDFS
* @author Administrator
*
*/
public class MapReduceReaderHbaseDriver {
public static class WordCountHBaseMapper extends TableMapper<Text, Text>{
protected void map(ImmutableBytesWritable key, Result values,Context context) throws IOException, InterruptedException{
StringBuffer sb = new StringBuffer("");
//获取列簇content下面的值
for(java.util.Map.Entry<byte[], byte[]> value : values.getFamilyMap("content".getBytes()).entrySet()){
String str = new String(value.getValue());
if(str != null){
sb.append(str);
}
context.write(new Text(key.get()), new Text(new String(sb)));
}
}
} public static class WordCountHBaseReducer extends Reducer<Text, Text, Text, Text>{
private Text result = new Text();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{
for(Text val : values){
result.set(val);
context.write(key, result);
}
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
String tableName = "wordcount";//表名称
Configuration conf = HBaseConfiguration.create();//实例化Configuration
conf.set("hbase.zookeeper.quorum", "header-2,core-1,core-2");
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.master", "header-1:60000"); Job job = new Job(conf, "import from hbase to hdfs");
job.setJarByClass(MapReduceReaderHbaseDriver.class); job.setReducerClass(WordCountHBaseReducer.class);
//配置读取hbase的相关操作
TableMapReduceUtil.initTableMapperJob(tableName, new Scan(), WordCountHBaseMapper.class, Text.class, Text.class, job, false); //输出路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://header-1:9000/user/out"));
System.out.println(job.waitForCompletion(true) ? 0 : 1);
}
}
HBase的访问方式的更多相关文章
- hbase的几种访问方式
Hbase的访问方式 1.Native Java API:最常规和高效的访问方式: 2.HBase Shell:HBase的命令行工具,最简单的接口,适合HBase管理使用: 3.Thrift Gat ...
- Hbase访问方式
Hbase访问方式 Hbase shell命令操作 Hbase shell命令操作--general操作 首先启动Hbase 启动shell 查看表结构 删除一个表 创建表和查看表结构 插入几条数据 ...
- HBase数据访问的一些常用方式
类型 特点 场合 优缺点分析 Native Java API 最常规和高效的访问方式 适合MapReduce作业并行批处理HBase表数据 Hbase Shell HBase的命令行工具,最简单的访问 ...
- 分布式结构化存储系统-HBase访问方式
分布式结构化存储系统-HBase访问方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. HBase提供了多种访问方式,包括HBase shell,HBase API,数据收集组件( ...
- ADO.NET编程之美----数据访问方式(面向连接与面向无连接)
最近,在学习ADO.NET时,其中提到了数据访问方式:面向连接与面向无连接.于是,百度了一下,发现并没有很好的资料,然而,在学校图书馆中发现一本好书(<ASP.NET MVC5 网站开发之美&g ...
- Objective-C 中self.与_访问方式的区别
Objective-C中属性self.a与_a访问的区别: 在OC中我们可以通过指令@property定义属性. OC对属性封装了许多方法,同时也会自动实现一些方法,相比实例变量,感觉更加面向对象些. ...
- 在APACHE服务器上的访问方式上去除index.php
在APACHE服务器上的访问方式上去除index.php 下面我说下 apache 下 ,如何 去掉URL 里面的 index.php 例如: 你原来的路径是: localhost/index ...
- Django 之 ForeignKey、ManyToMany的访问方式
1.ForeignKey 情况I: from django.db import models class Blog(models.Model): pass class Entry(models.Mod ...
- Java中Map集合的四种访问方式(转)
最近学习Java发现集合类型真是很多,访问方式也很灵活,在网上找的方法,先放下备用 public static void main(String[] args) { Map<String, St ...
随机推荐
- 《x86汇编语言:从实模式到保护模式 》学习笔记之:第一次编写汇编语言
1.汇编语言源文件:first.asm mov ax,0x3f add bx,ax add cx,ax 2.用nasm编译成二进制文件:first.bin nasm -f bin first.asm ...
- Linux root用户与普通用户时间不一致
造成这种原因有多种,可能是安装软件时选的时区不是本国时间等等. 今天检查了root用户和oracle及grid用户的时间不一样,幸好数据库还没有正式应用,不然可能会造成时间差影响. 现在将同步的方法步 ...
- 进程(process)和线程(thread)
1.计算机的核心是CPU,它承担了所有的计算任务.它就像一座工厂,时刻在运行. 2.假定工厂的电力有限,一次只能供给一个车间使用.也就是说,一个车间开工的时候,其他车间都必须停工.背后的含义就是,单个 ...
- MVP 实战
那么我们下面就要将这个类中的代码改写为 MVP 的写法,回顾上面提及的 MVP 架构的思想,它是将 View 层与 Model 层彻底隔离,意味着 View 和 Model 都不再持对方的引用,它们通 ...
- java 中创建线程有哪几种方式?
Java中创建线程主要有三种方式: 一.继承Thread类创建线程类 (1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务.因此把run()方法称为执行 ...
- Laravel5.5执行 npm run dev时报错,提示cross-env找不到(not found)的解决办法
Laravel 5.4 Mix & Laravel5.5执行 npm run dev时报错,提示cross-env找不到(not found)的解决办法 首先进入package.json文 ...
- VMware 虚拟化编程(15) — VMware 虚拟机的恢复方案设计
目录 目录 前文列表 将已存在的虚拟机恢复到指定时间点 恢复为新建虚拟机 灾难恢复 恢复细节 恢复增量备份数据 以 RDM 的方式创建虚拟磁盘 创建虚拟机 Sample of VirtualMachi ...
- 阶段1 语言基础+高级_1-3-Java语言高级_1-常用API_1_第1节 Scanner类_4-练习一_键盘输入两个数
导包语句其实不用我们自己去写, 选中后回车会自动的导入包 java.util 如果没有导入进来也可以,光标在关键字那里,ALT+回车 也会自动导入包 运行看一下结果:程序其实还有可以优化的地方 先输入 ...
- Android的Surface的创建
ViewRootImpl管理着整个view tree. 对于ViewRootImpl.setView(),我们可以简单的把它当做一个UI渲染操作的入口. http://androidxref.com/ ...
- 【ABAP系列】SAP 获取工单和工序的状态
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP 获取工单和工序的状态 ...