Spark指标项监控
监控配置
spark的监控主要分为Master、Worker、driver、executor监控。Master和Worker的监控在spark集群运行时即可监控,Driver和Excutor的监控需要针对某一个app来进行监控。
如果都要监控,需要根据以下步骤来配置
- 修改$SPARK_HOME/conf/spark-env.sh,添加以下语句:
SPARK_DAEMON_JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
# JMX port to use
export SPARK_DAEMON_JAVA_OPTS="$SPARK_DAEMON_JAVA_OPTS -Dcom.sun.management.jmxremote.port=8712 "
# export SPARK_DAEMON_JAVA_OPTS="$SPARK_DAEMON_JAVA_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT "
语句中有$JMX_PORT,这个的值可以自定义,也可以获取一个随机数作为端口号。
如果端口自定义为一个具体的值,而 spark 的 Master 和其中之一的 Worker 在同一台机器上,会出现端口冲突的情况。
vim $SPARK_HOME/conf/metrics.properties
*.sink.jmx.class=org.apache.spark.metrics.sink.JmxSink
master.source.jvm.class=org.apache.spark.metrics.source.JvmSource
worker.source.jvm.class=org.apache.spark.metrics.source.JvmSource
driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource
vim $SPARK_HOME/conf/spark-defaults.conf,添加以下项为driver和executor设置监控端口,在有程序运行的情况下,此端口会被打开。
spark.metrics.conf /opt/bigdata/spark/conf/metrics.properties
spark.driver.extraJavaOptions -XX:+PrintGCDetails -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.mana
gement.jmxremote.port=8712
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.mana
gement.jmxremote.port=8711
在spark的Master和Worker正常运行以及spark-submit提交了一个程序的情况下,可以从linux中查询出端口号码。

20181105-新配置方法
组件的运行步骤
sbin/start-all.sh
1 sbin/spark-config.sh
2 bin/load-spark-env.sh
3 sbin/start-master.sh
1) sbin/spark-config.sh
2) bin/load-spark-env.sh
3) sbin/spark-damon.sh
1 > sbin/spark-config.sh
2 > bin/load-spark-env.sh
3 > ...正式启动
4 sbin/start-slaves.sh
1) sbin/spark-config.sh
2) bin/load-spark-env.sh
3) sbin/start-slave.sh
1 > sbin/spark-config.sh
2 > bin/load-spark-env.sh
3 > sbin/spark-damon.sh
1 - sbin/spark-config.sh
2 - bin/load-spark-env.sh
3 - ...正式启动
配置步骤
在组件的运行步骤中大量加载 sbin/spark-config.sh 和 bin/load-spark-env.sh 两个脚本,load-spark-env.sh 中主要加载saprk的外部运行环境配置,spark-config.sh 主要加载spark运行的内部环境配置,因此,将需要修改的脚本修改在 spark-config.sh 中,修改步骤如下
1. 修改 spark-config.sh ,添加脚本
if [ "${JMX_PORT}" ]; then
export SPARK_DAEMON_JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=${JMX_PORT}"
fi
2. 修改 start-master.sh ,添加脚本
export JMX_PORT=xxxx
3. 修改 start-slave.sh ,添加脚本
export JMX_PORT=xxxx
测试结果:已在测试集群验证成功
20181107-新配置方法
配置步骤
修改 $SPARK_HOME/sbin/start-master.sh 以及 start-slave.sh (所有机器)
export SPARK_DAEMON_JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port
=xxxx"
指标项整理
OS监控指标
此指标项适用于Master、Worker所在机器的监控。
| objectName | 指标项 | 说明 |
|---|---|---|
| java.lang:type=OperatingSystem | SystemCpuLoad | 系统CPU使用率 |
| java.lang:type=OperatingSystem | ProcessCpuLoad | 进程CPU使用率 |
| java.lang:type=OperatingSystem | FreePhysicalMemorySize | 空闲物理内存 |
JVM监控指标
此指标项适用于Master、Worker、app的Driver和Executor的监控。
| objectName | 指标项 | 说明 |
|---|---|---|
| metrics:name=jvm.total.used | Value | JVM的内存使用大小 |
| metrics:name=jvm.PS-Scavenge.count | Value | GC次数 |
Master监控指标
| objectName | 指标项 | 说明 |
|---|---|---|
| metrics:name=master.aliveWorkers | Value | 可使用的Woker数量 |
| metrics:name=master.apps | Value | spark的app数量 |
| metrics:name=master.waitingApps | Value | 等待的app数量 |
Worker监控指标
| objectName | 指标项 | 说明 |
|---|---|---|
| metrics:name=worker.memFree_MB | Value | worker的空闲内存 |
| metrics:name=worker.coresFree | Value | worker空闲的core数量 |
| metrics:name=worker.executors | Value | worker的正在使用的executor的数量 |
| metrics:name=worker.memUsed_MB | Value | worker的已使用的内存 |
| metrics:name=worker.coresUsed | Value | worker的已使用的core的数量 |
Driver和Executor的监控
从Driver和Executor的端口中,根据app的ID获取到与这个app的所有指标,如下图所示:
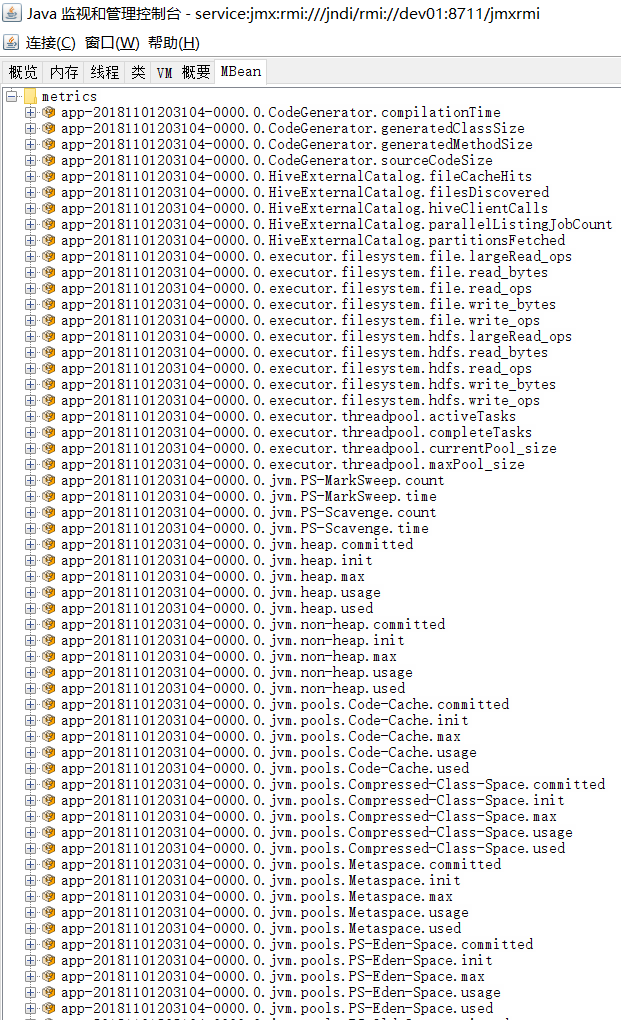
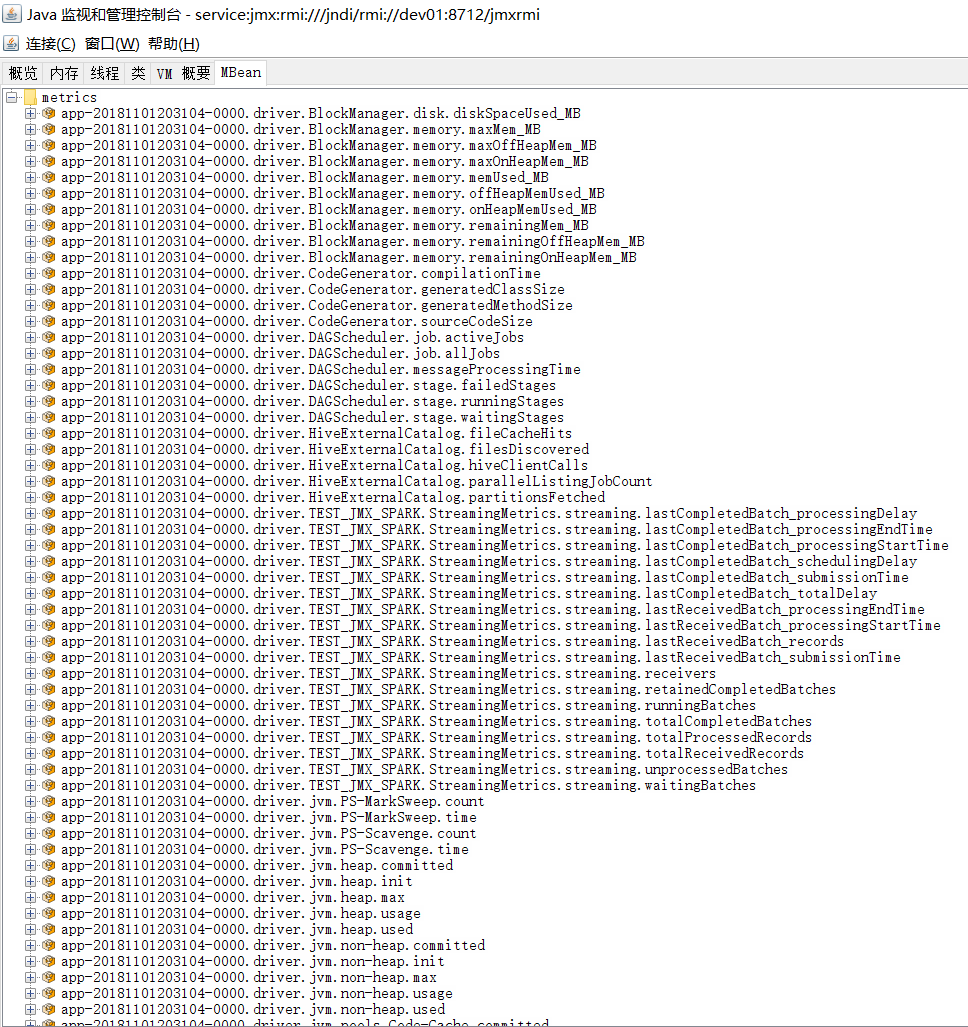
| 类型 | objectName | 指标项 | 说明 |
|---|---|---|---|
| Driver | <app-ID>.driver.XXX | Value | app-ID的spark程序的driver情况 |
| Excutor | <app-ID>.0.XXX | Value | app-ID的spark程序的executorID为0的情况 |
ps: XXX 的具体名称与以上 非Master和Worker 的指标项名称一致。
Spark指标项监控的更多相关文章
- Flume监控指标项
配置监控 1.修改flume-env.sh export JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmx ...
- hbase 监控指标项
名词解释 JMX:Java Management Extensions,用于用于Java程序扩展监控和管理项 GC:Garbage Collection,垃圾收集,垃圾回收机制 指标项来源 主机名 u ...
- Hbase监控指标项
名词解释 JMX:Java Management Extensions,用于用于Java程序扩展监控和管理项 GC:Garbage Collection,垃圾收集,垃圾回收机制 指标项来源 主机名 u ...
- kafka监控指标项
监控配置 kafka基本分为broker.producer.consumer三个子项,每一项的启动都需要用到 $KAFKA_HOME/bin/kafka-run-class.sh 脚本,在该脚本中 ...
- Hadoop监控指标项
配置 修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh # 在配置namenode和datanode时都会有用到JMX_OPTS的代码,是为了减少重复提取出的公共代码 e ...
- 【0.2】【MySQL】常用监控指标及监控方法(转)
[MySQL]常用监控指标及监控方法 转自:https://www.cnblogs.com/wwcom123/p/10759494.html 对之前生产中使用过的MySQL数据库监控指标做个小结. ...
- 【Graphite】使用dropwizard.metrics向Graphite中写入指标项数据
graphite 定时向Graphite中写入指标项数据,指标项模拟个数3000个 使用的类库 官方文档 dropwizard的github地址 Metric官方文档 metrics.dropwi ...
- SOAPUI 压力测试的指标项说明
soapUI Pro指标项说明: Test Step Sets the startup delay for each thread (in milliseconds), setting to ...
- 【MySQL】常用监控指标及监控方法
对之前生产中使用过的MySQL数据库监控指标做个小结. 指标分类 指标名称 指标说明 性能类指标 QPS 数据库每秒处理的请求数量 TPS 数据库每秒处理的事务数量 并发数 数据库实例当前并行处理的 ...
随机推荐
- HTML(上)
目录 HTML(上) 浏览器 HTML 什么是HTML HTML的作用 编写HTML的规范 HTML结构 HTML常用标签 HTML标签速记 HTML(上) 浏览器 浏览器也是一个客户端 #这是一个服 ...
- python-redis-订阅和发布
发布:redishelper.py import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host ...
- myBatis+Spring+SpringMVC框架面试题整理
myBatis+Spring+SpringMVC框架面试题整理(一) 2018年09月06日 13:36:01 新新许愿树 阅读数 14034更多 分类专栏: SSM 版权声明:本文为博主原创文章 ...
- es分数_score衰减函数
1.按日期衰变 GET news/doc/_search { "query" : { "function_score": { "query" ...
- 01 Linux常用基本命令(一)
1.远程连接服务器 Xshell为例: ssh 用户名@IP地址 (ssh root@192.168.119.139) 查看服务器的IP地址: ifconfig (ip addr) 2.命令 1.ls ...
- node + express搭建api项目
express框架 描述 express是一个保持最小规模的灵活的 Node.js Web 应用程序开发框架,为 Web 和移动应用程序提供一组强大的功能. 安装 // 1.使用npm淘宝镜像--cn ...
- linux系统awk命令
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息awk处理过程:?依次对每一行进行处理,然后输出awk命令形式:awk [-F|-f ...
- 文件I/O简述
什么是I/O 宏观上讲,I/O是信息处理系统(例如计算机)与外部世界(可能是人或其他信息处理系统)之间的通信.输入(Input)是系统接收的信号或数据,输出(Output)是从其发送的信号或数据.另一 ...
- composer入门教程
初始化项目 使用composer初始化工作目录,在项目的根目录命令行输入 composer init 安装项目 在composer.json文件所在目录命令行下执行如下命令 php composer. ...
- 【转载】Stanford CoreNLP Typed Dependencies
总结自Stanford typed dependencies manual 原文链接:http://www.jianshu.com/p/5c461cf096c4 依存关系描述句子中词与词之间的各种语法 ...