Pandas 分组聚合 :分组、分组对象操作
1、概述
1.1 group语法
df.groupby(self, by=None, axis=0, level=None,
as_index: bool=True, sort: bool=True,
group_keys: bool=True,
squeeze: bool=False,
observed: bool=False, dropna=True)
其中 by 为分组字段,由于是第一个参数可以省略,可以按列表给多个。会返回一个groupby_generic.DataFrameGroupBy对象,如果不给定聚合方法,不会返回 DataFrame。
1.2 DateFrame应用分组
#按team进行分组,并求和
df.groupby('team').sum()
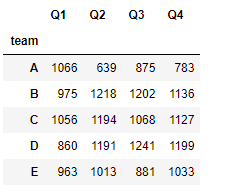
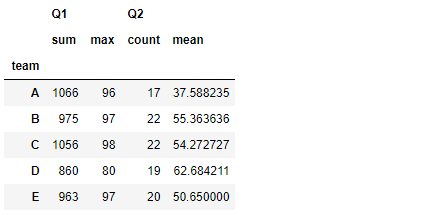
#对不同列进行不同的聚合计算,对分组对象使用agg,传入函数字典
#对分组后的同一列进行不同运算
df.groupby('team').agg({'Q1':['sum','max'],'Q2':['count','mean']})
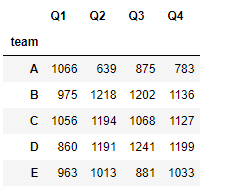
1.3 Series应用分组
如果给groupby的by参数传入一个Series,此series与分组数据的索引对齐后,按series的值进行分组
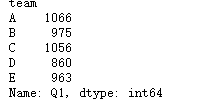
df.groupby(by=df.team).sum()
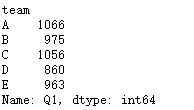
df.Q1.groupby(df.team).sum()
2、分组
df.groupby()会生成一个分组对象,把这个对象的各个字段按照一定的聚合方法输出
下面介绍,分组对象 and 分组对象的方法有哪些
2.1 分组对象
2.2 按标签分组
按某一列/多列进行分组
如果是多列,会按照这几个列的排列组合的去重,进行分组,并且get_group()时要传入元组
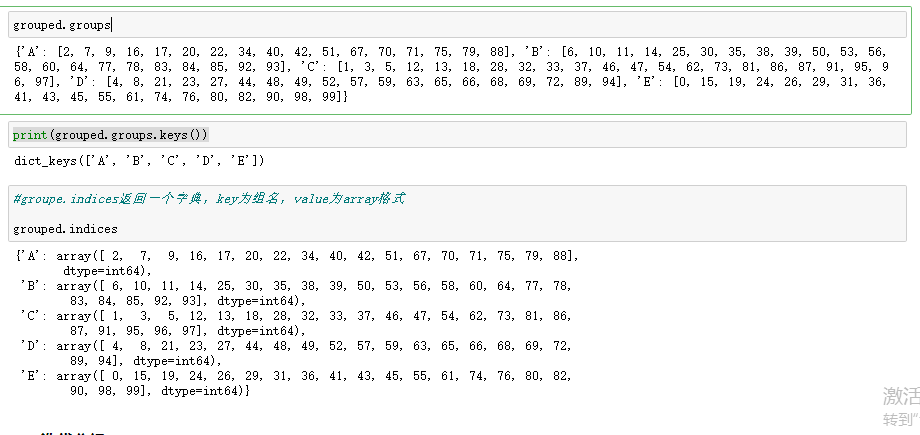
grouped = df.groupby('team')
grouped.get_group('A')
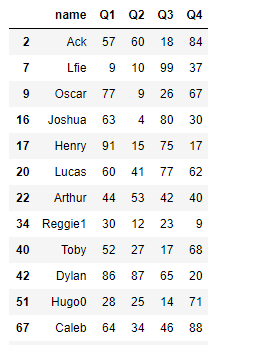
grouped = df.groupby(['team','name'])
grouped.get_group(('A','Ack'))

2.3 表达式
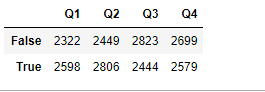
将数据分为ture 和 false两组
grouped = df.groupby(lambda x: x>60)
grouped.sum()
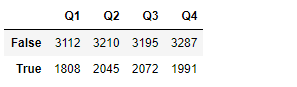
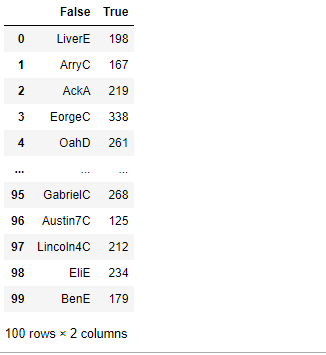
df.groupby(lambda x: 'Q' in x,axis=1).sum() #按列名是否包含字母Q,分成两列 ‘name’和‘team’不包含被分到了一起
# 按索引的奇偶行分组
df.groupby(df.index%2==0).sum()
2.4 函数分组
:satr:by参数可以调用一个函数,通过函数计算返回一个分组依据
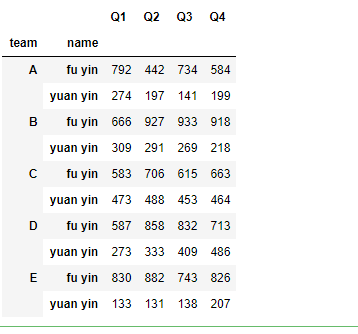
#按姓名首字母为元音or辅音分组
def first_letter(name):
if name[0].lower() in 'aeiou':
return 'yuan yin'
return 'fu yin'
df.set_index('name').groupby(first_letter).sum()

2.5 多种方法混合
by参数传一个list
df.groupby(['team',df.name.apply(first_letter)]).sum()
3、分组对象操作
3.1 选择分组
3.2 迭代分组
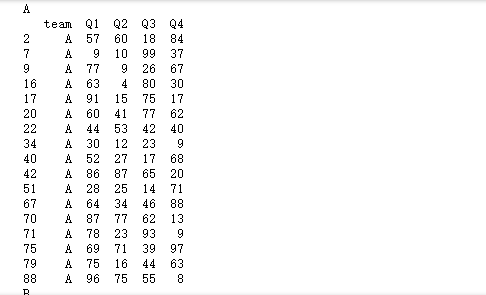
for name, item in grouped:
print(name)
print(item)
3.3 选择列
#选择分组后各组的某一列,像df那样选择即可
grouped.Q1.sum()
#选择多列
grouped['Q1','Q2'].sum()

3.4 应用函数apply
分组对象调用apply,是传入一个df,返回经过函数计算后的df,s,或者标量,再把数据组合
#将Q1的数据*2
grouped.apply(lambda x:x.Q1*2)
'''
```
team
A 2 114
7 18
9 154
16 126
17 182
...
E 80 184
82 8
90 76
98 22
99 42
Name: Q1, Length: 100, dtype: int64
```
'''
#见分组中的一列输出为列表
grouped.apply(lambda x:x.Q1.to_list())
'''
```
team
A [57, 9, 77, 63, 91, 60, 44, 30, 52, 86, 28, 64...
B [61, 17, 9, 80, 89, 57, 9, 97, 2, 66, 18, 21, ...
C [36, 93, 24, 83, 51, 80, 50, 91, 90, 1, 29, 69...
D [65, 64, 79, 80, 62, 15, 24, 57, 50, 79, 5, 14...
E [89, 48, 97, 74, 71, 35, 67, 88, 48, 8, 8, 12,...
dtype: object
```
'''
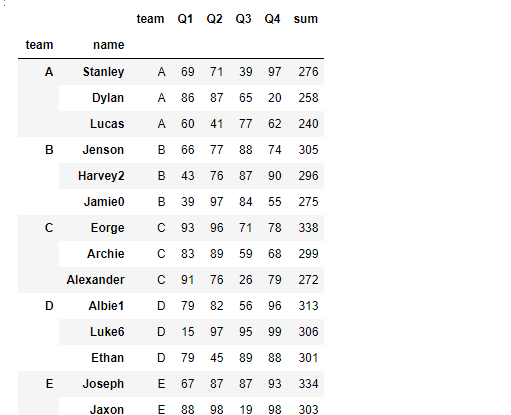
#实现每组成绩前三
def get_head(df):
df['sum']=df.sum(1)
df = df.sort_values('sum',ascending = False)
return df.head(3)
df.set_index('name').groupby('team').apply(get_head)
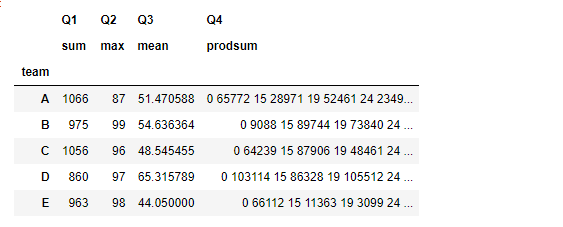
#传入一个series,隐射系列不同的聚合统计方法
def f_mi(x):
d = []
d.append(x['Q1'].sum())
d.append(x['Q2'].max())
d.append(x['Q3'].mean())
d.append(x['Q4']*x['Q4'].sum())
return pd.Series(d,index=[['Q1','Q2','Q3','Q4'],['sum','max','mean','prodsum']])
df.groupby('team').apply(f_mi)
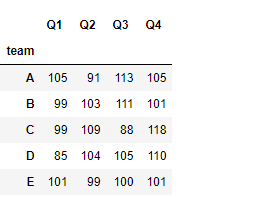
3.5 管道方法pipe
类似于df的管道方法
将同组的所有数据应用在方法中,返回的是经过函数处理的返回数据格式
#每组最大值和最小值之和
grouped.pipe(lambda x:x.max()+x.min())
#下面使用自定义函数,经过计算,返回一个Series
#A/B组平均值的差值
def get_mean(df):
return df.get_group('A').mean()-df.get_group('B').mean()
grouped.pipe(get_mean)
'''
```
Q1 18.387701
Q2 -17.775401
Q3 -3.165775
Q4 -5.577540
dtype: float64
```
'''
3.6 转换方法transform
:satr:transform()类似于agg,但transform会返回与原始数据相同形状的DateFrame
- 会将原来数据的值一一替换成统计后的值
例如:按组计算平均成绩,那么返回的新的df中每个学生的成绩就是它所在组的平均成绩
#将所有数据替换成分组中的平均成绩
grouped.transform('mean')
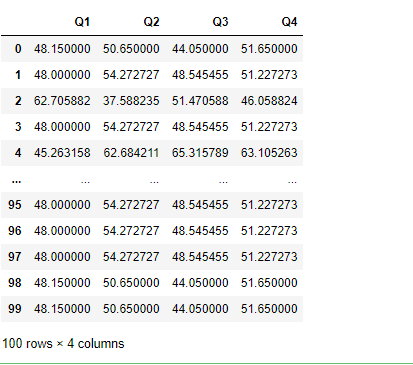
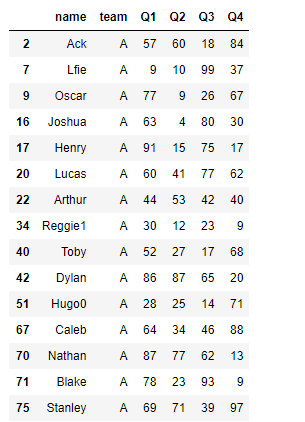
#可以用它进行按组筛选
#Q1成绩大于60的组的所有成员
df[grouped.transform('mean').Q1>60]
3.7 筛选方法filter
使用filter()对组作为整体进行筛选,满足条件,整个组会被显示 传入它调用的函数的默认变量是每个分组的DateFrame,经过计算,最终返回一个布尔值,为真的DateFrame全部显示
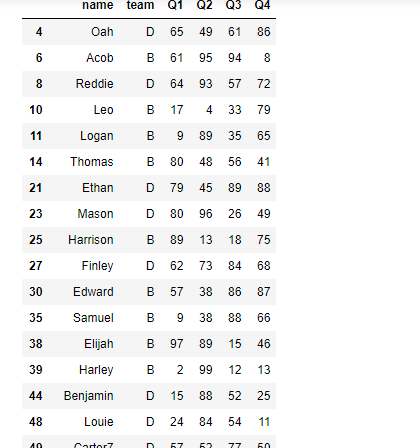
#按团队分组,每组的每个季度成绩为本季度的的平均分
#全年的成绩为这个季度的平均分的平均费
#最终筛选出团队中分数高于51的所有成员
def get_score(df):
score = 51
return df.mean().mean() > score
df.groupby('team').filter(get_score)
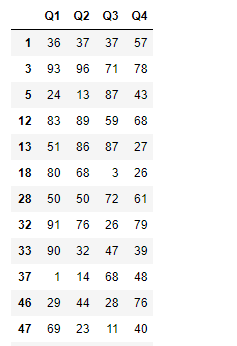
# Q1成绩至少有一个大于97的组
grouped.filter(lambda x:(x.Q1>97).any())
#所有成员平均成绩大于60的组
grouped.filter(lambda x: (x.mean()>30).all())
4、参考文献
《深入浅出Pandas》
Pandas 分组聚合 :分组、分组对象操作的更多相关文章
- Django 08 Django模型基础3(关系表的数据操作、表关联对象的访问、多表查询、聚合、分组、F、Q查询)
Django 08 Django模型基础3(关系表的数据操作.表关联对象的访问.多表查询.聚合.分组.F.Q查询) 一.关系表的数据操作 #为了能方便学习,我们进入项目的idle中去执行我们的操作,通 ...
- pandas聚合和分组运算——GroupBy技术(1)
数据聚合与分组运算——GroupBy技术(1),有需要的朋友可以参考下. pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个 ...
- Pandas系列(九)-分组聚合详解
目录 1. 将对象分割成组 1.1 关闭排序 1.2 选择列 1.3 遍历分组 1.4 选择一个组 2. 聚合 2.1 一次应用多个聚合操作 2.2 对DataFrame列应用不同的聚合操作 3. t ...
- Pandas 分组聚合
# 导入相关库 import numpy as np import pandas as pd 创建数据 index = pd.Index(data=["Tom", "Bo ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
- pandas聚合和分组运算之groupby
pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对数据集进行切片.切块.摘要等操作.根据一个或多个键(可以是函数.数组或DataFrame列名)拆分pandas对象.计算分 ...
- Pandas时间序列和分组聚合
#时间序列import pandas as pd import numpy as np # 生成一段时间范围 ''' 该函数主要用于生成一个固定频率的时间索引,在调用构造方法时,必须指定start.e ...
- Django orm进阶查询(聚合、分组、F查询、Q查询)、常见字段、查询优化及事务操作
Django orm进阶查询(聚合.分组.F查询.Q查询).常见字段.查询优化及事务操作 聚合查询 记住用到关键字aggregate然后还有几个常用的聚合函数就好了 from django.db.mo ...
- Django---Django的ORM的一对多操作(外键操作),ORM的多对多操作(关系管理对象),ORM的分组聚合,ORM的F字段查询和Q字段条件查询,Django的事务操作,额外(Django的终端打印SQL语句,脚本调试)
Django---Django的ORM的一对多操作(外键操作),ORM的多对多操作(关系管理对象),ORM的分组聚合,ORM的F字段查询和Q字段条件查询,Django的事务操作,额外(Django的终 ...
随机推荐
- java连接oracle数据库(转)
在做导游通项目所用到 package org.javawo.test; import java.sql.Connection; import java.sql.DriverManager; /** * ...
- 夏日葵电商:连锁零售店小程序o2o系统解决方案
公众平台"附近小程序"功能上线后,一个主体账号可以同时绑定N+个门店,这对连锁零售店铺来说是重磅福利呀,无论你是通过搜索还是线下扫码进入小程序,线上与线下都完全贯通了,线上多种入口 ...
- java中如何知道一个字符串中有多少个字,把每个字打印出来,举例
9.6 About string,"I am ateacher",这个字符串中有多少个字,且分别把每个字打印出来. public class Test { static i ...
- Java中使用最频繁及最通用的Java工具类
在Java中,工具类定义了一组公共方法,Java中使用最频繁及最通用的Java工具类. 一. org.apache.commons.io.IOUtils closeQuietly:关闭一个IO流.so ...
- 浅谈ES6中的Async函数
转载地址:https://www.cnblogs.com/sghy/p/7987640.html 定义:Async函数是一个异步操作函数,本质上,Async函数是Generator函数的语法糖.asy ...
- 升级DLL plugin 到AutoDllPlugin
为了使打包构建速度加快使用的DLLPlugin,但是我们还是需要手动把dll文件引入文件, HTMLwebpackplugin 结合autoDLLplugin可以自动引入打包文件, 十份地方便
- windows下的volatility取证分析与讲解
volatility(win64) 1.下载 volatility 下载地址:(我下载的版本2.6,并把名字稍微改了一下) Release Downloads | Volatility Foundat ...
- vue项目中连接MySQL时,报错ER_ACCESS_DENIED_ERROR: Access denied for user 'root'@'localhost' (using password:YES)
一.前言 我们前端很多时候在写vue项目的时候,会把后端的数据拿到本地来跑,在连接MySQL数据库的时候,可能出现一些问题,如: ER_ACCESS_DENIED_ERROR: Access deni ...
- JAVASE for 笔记
//0到100中奇数偶数的和package com.huang.boke.flowPath;public class Fordeme { public static void main(String[ ...
- mysql HikariCP连接池配置
#连接池配置 #最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-size spring.datasource.hikari.minimum ...