K近邻算法(k-nearest neighbor, kNN)
K近邻算法(K-nearest neighbor, KNN)
KNN是一种分类和回归方法。
- KNN简介
- KNN模型3要素
- KNN优缺点
- KNN应用
- 参考文献
KNN简介
KNN思想
给定一个训练集
T={(x1,y1),(x2,y2),...,(xN,yN)}
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
}
,对新输入的实例
x
x
,在训练集中找到与实例 xx 最近的k个实例,根据k个实例中大多数类所属的类作为实例
x
x
<script type="math/tex" id="MathJax-Element-4">x</script> 所属的类。
KNN算法

KNN模型3要素
K值得选择、距离度量方法选择、分类决策规则选择
-
应用中,一般选择较小的k值,交叉验证可以选择最优的k值。
k值减小,模型变复杂,容易过拟合(原因:选择较小k值时,近似误差减小,估计误差增大)。 -
近似误差:即对现有训练集的训练误差,更关注“训练”。
估计误差:即对测试集的测试误差,更关注“测试”。 -
欧氏距离
曼哈顿距离
切比雪夫距离
等等 - 最常用的是,大多数原则:即由输入实例的k个近邻样本中大多数的类别确定输入实例的类。
K值得选择
距离度量方法选择
分类决策规则选择
KNN优缺点
- 简单、精度高
- 计算时间、空间复杂度高
优点
缺点
KNN应用
使用knn算法识别手写数字数据集,链接:https://pan.baidu.com/s/1rgiGBLTMiybCCSUnzR1lYw 密码:yse7
# -*-coding:utf-8-*-
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # shape[0]读取矩阵第一维的长度
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # numpy.tile(A,B)函数重复A, B次
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
#print(type(distances))
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32*i + j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('digits/trainingDigits') # 加载训练集
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] # 提取文件名
classNumStr = int(fileStr.split('_')[0]) # 提取类别标签
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr)
testFileList = listdir('digits/testDigits') # 加载测试集
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print ("\nthe total number of errors is: %d" % errorCount)
print ("\nthe total error rate is: %f" % (errorCount/float(mTest)))
if __name__ == '__main__':
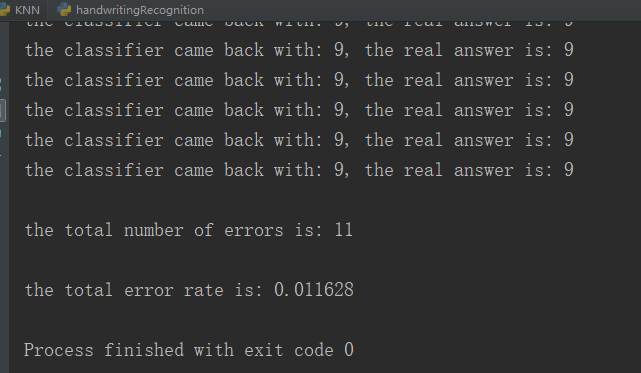
handwritingClassTest()程序运行结果:
参考文献
[1]李航. 统计学习方法[M]. 清华大学出版社, 2012.
[2]Peter Harrington. 机器学习实战[M]. 人民邮电出版社, 2013.
K近邻算法(k-nearest neighbor, kNN)的更多相关文章
- k近邻算法(k-nearest neighbor,k-NN)
kNN是一种基本分类与回归方法.k-NN的输入为实例的特征向量,对应于特征空间中的点:输出为实例的类别,可以取多类.k近邻实际上利用训练数据集对特征向量空间进行划分,并作为其分类的"模型&q ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
随机推荐
- 内网部署YApi
官网地址:https://hellosean1025.github.io/yapi/devops/index.html 环境要求 nodejs(7.6+) mongodb(2.6+),安装看这篇文章: ...
- Beats:在Docker里运行Filebeat
- Kubernetes生态架构图
图片来源于:https://gitbook.curiouser.top/ 一.kubernetes 集群架构图 二.Openshift or Kubernetes 集群架构图 三.常见的 CI/CD ...
- Exporter介绍
Exporter是什么 广义上讲所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter.而Exporter的一个实例称为target,如下所示,Prometheus通过轮 ...
- JDK19新特性使用详解
前提 JDK19于2022-09-20发布GA版本,本文将会详细介绍JDK19新特性的使用. 新特性列表 新特性列表如下: JPE-405:Record模式(预览功能) JPE-422:JDK移植到L ...
- 对list集合中元素按照某个属性进行排序
test 为集合中的元素类型(其中包含i属性) Collections.sort(list,(test o1, test o2) -> { if (o1.getI() != o2.getI()) ...
- 云的安全组和网络ACL
云的安全组和网络ACL 1.流量控制: 安全组是云服务器.数据库等实例级别的流量控制 ACL是子网级别的流量控制 2.规则: 安全组和网络ACL都支持允许规则和拒绝规则 3.状态: 安全组有状态( ...
- 构建Springboot项目、实现简单的输出功能、将项目打包成可以执行的JAR包(详细图解过程)
1.构建SpringBoot项目 大致流程 1.新建工程 2.选择环境配置.jdk版本 3.选择 依赖(可省略.后续要手动在pom文件写) 4.项目名 1.1 图解建立过程 1.2 项目结构 友情提示 ...
- 【JavaSE】JDK 环境配置
下载 JDK 网站网址:oracle 安装 JDK 双击运行安装包 配置环境变量
- ML-朴素贝叶斯算法
贝叶斯定理 w是由待测数据的所有属性组成的向量.p(c|x)表示,在数据为x时,属于c类的概率. \[p(c|w)=\frac{p(w|c)p(c)}{p(w)} \] 如果数据的目标变量最后有两个结 ...