网络爬虫之requests模块,自动办公领域之openpyx模块
一、第三方模块的下载与使用
第三方模块:别人写的模块,一般情况下功能都特别强大
我们如果想使用第三方模块,第一次必须先下载,后面才可以反复使用(等同于内置模块)
下载第三方模块的方式
1. pip工具 注意每个解释器都有pip工具,如果我们的电脑上有多个版本的解释器,那么我们在使用pip的时候一定要注意到底用的是哪一个,否则极其容易出现使用的是A版本解释器,然后用B版本的pip下载模块。
为了避免pip冲突,我们在使用的时候可以添加对应的版本号
| python27 | pip2.7 |
| python36 | pip3.6 |
| python38 | pip3.8 |
- 下载第三方模块的句式:
pip install 模块名
- 下载第三方模块临时切换仓库
pip install 模块名 -i 仓库地址
- 下载第三方模块指定版本(不指定默认是最新版)
pip install 模块名==版本号 -i 仓库地址
2. pycharm提供快捷方式
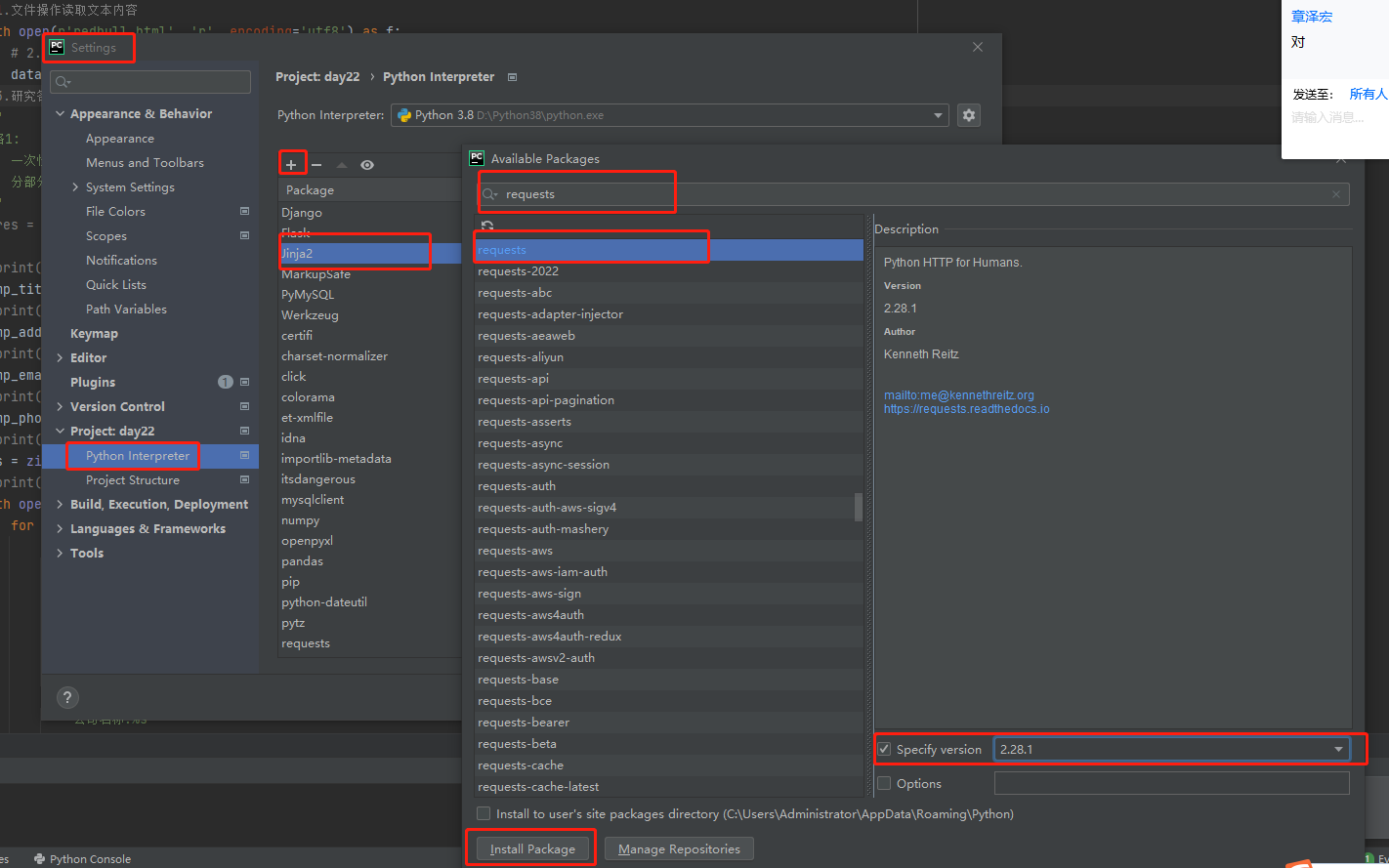
注意:下载第三方模块可能会出现的问题
1. 报错并有警告信息
WARNING: You are using pip version 20.2.1;
原因在于pip版本过低,只需要拷贝后面的命令执行更新操作即可
d:\python38\python.exe -m pip install --upgrade pip
更新完成后再次执行下载第三方模块的命令即可
2.报错并含有Timeout关键字
说明当前计算机网络不稳定,只需要换网或者重新执行几次即可
3. 报错并没有关键字
面向百度搜索
pip下载XXX报错:拷贝错误信息
通常都是需要用户提前准备好一些环境才可以顺利下载
4.下载速度很慢
pip默认下载的仓库地址是国外的 python.org
我们可以切换下载的地址
pip install 模块名 -i 仓库地址
pip的仓库地址有很多 百度查询即可
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
二、网络爬虫模块之requests模块
requests模块能够模拟浏览器发送网络请求
导入模块: import requests
1. 朝指定网址发送请求获取页面数据(等价于:浏览器地址栏输入网址回车访问)
res = requests.get('http://www.redbull.com.cn/about/branch')
print(res.content) # 获取bytes类型的网页数据(二进制)
res.encoding = 'utf8' # 指定编码
print(res.text) # 获取字符串类型的网页数据(默认按照utf8)
2. 网络爬虫实战之爬取链家二手房数据
import re
import requests res = requests.get('https://sh.lianjia.com/ershoufang/pudong/tt9/')
data = res.text home_name_list = re.findall('<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>',data)
home_street_list = re.findall('<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" data-log_index=".*?" data-el="region">.*? </a> - <a href=".*?" target="_blank">(.*?)</a> </div>',data)
home_info_list = re.findall('<div class="houseInfo"><span class="houseIcon"></span>(.*?)</div>',data)
home_attention_list = re.findall('<div class="followInfo"><span class="starIcon"></span>(.*?)</div>',data)
home_unite_price = re.findall('<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div></div>',data) home_data = zip(home_name_list,home_street_list,home_info_list,home_attention_list,home_unite_price) with open(r'home_data.txt', 'w',encoding='utf8') as f: for data in home_data: print("""
1.房屋名称 : %s
2.房屋街道 : %s
3.房屋详情 : %s
4.房屋关注度 : %s
5.房屋价格 : %s
""" % data) f.write("""
1.房屋名称 : %s
2.房屋街道 : %s
3.房屋详情 : %s
4.房屋关注度 : %s
5.房屋价格 : %s
""" % data)
三、自动化办公领域之openpyxl模块
- excel文件的后缀名问题
03版本之前 .xls
03版本之后 .xlsx
- 操作excel表格的第三方模块
xlwt:往表格中写入数据、xlrd:从表格中读取数据:兼容所有版本的excel文件
openpyxl:最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
pandas:涵盖了上述的模块
openpyxl操作
1. 创建文件与修改文件名称
Workbook() —创建 excel 文件
from openpyxl import Workbook wb = Workbook() # 创建了一个excle表格 wb.save(r'客户信息表.xlsx') # 保存之后表格才会出现
双击打开如图:
在一个excel文件内创建多个工作簿(注意必须把之前创建的表格关掉之后才可以操作,不然会报错)
from openpyxl import Workbook wb = Workbook()
wb1 = wb.create_sheet('客户名单1')
wb2 = wb.create_sheet('客户名单2')
wb3 = wb.create_sheet('客户名单3') wb.save(r'客户信息表.xlsx')
双击打开如图:

还可以修改默认的工作簿位置
from openpyxl import Workbook wb = Workbook()
wb1 = wb.create_sheet('客户名单1')
wb2 = wb.create_sheet('客户名单2')
wb3 = wb.create_sheet('客户名单3')
wb4 = wb.create_sheet('VIP客户', 0) # 参数0表示的是工作薄位置 wb.save(r'客户信息表.xlsx')
二次修改工作薄名称
from openpyxl import Workbook wb = Workbook()
wb1 = wb.create_sheet('客户名单1')
wb2 = wb.create_sheet('客户名单2')
wb3 = wb.create_sheet('客户名单3')
wb4 = wb.create_sheet('VIP客户', 0) wb4.title = '长期客户' # 将‘VIP客户’修改为‘长期客户’ wb.save(r'客户信息表.xlsx')
2. 填写数据
填写数据的方式1:Worksheet[ ]
from openpyxl import Workbook wb = Workbook() # 创建了一个excle表格
wb1 = wb.create_sheet('客户名单1')
wb1['A1'] = 666 # ['A1'] 代表的是该表中的 A1 位置,我们可以将数据直接赋值给它 wb.save(r'客户信息表.xlsx')
填写数据的方式2:Worksheet.cell()
from openpyxl import Workbook wb = Workbook() # 创建了一个excle表格
wb1 = wb.create_sheet('客户名单1')
wb1.cell(row=3, column=1, value='Alex') # 在第3行第1列写入数据 wb.save(r'客户信息表.xlsx')
填写数据的方式3:Worksheet.append() 可以同时写入多个数据
from openpyxl import Workbook wb = Workbook() # 创建了一个excle表格
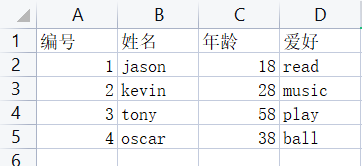
wb1 = wb.create_sheet('客户名单1') wb1.append(['编号', '姓名', '年龄', '爱好']) # 表头字段
wb1.append([1, 'jason', 18, 'read'])
wb1.append([2, 'kevin', 28, 'music'])
wb1.append([3, 'tony', 58, 'play'])
wb1.append([4, 'oscar', 38, 'ball']) wb.save(r'客户信息表.xlsx')
3. 填写数学公式
wb1['A1'] = 12
wb1['A2'] = 15
wb1['A3'] = 23
wb1['A4'] = 35
wb1['A5'] = '= sum(A1:A4)' # 85
openpyx实战:
将前面爬取的房屋信息写入Excley文件:
import requests
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/tt9/')
data = res.text home_name_list = re.findall('<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>',data) home_street_list = re.findall('<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" data-log_index=".*?" data-el="region">.*? </a> - <a href=".*?" target="_blank">(.*?)</a> </div>',data) home_info_list = re.findall('<div class="houseInfo"><span class="houseIcon"></span>(.*?)</div>',data) home_attention_list = re.findall('<div class="followInfo"><span class="starIcon"></span>(.*?)</div>',data) home_unite_price = re.findall('<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div></div>',data) home_data = zip(home_name_list,home_street_list,home_info_list,home_attention_list,home_unite_price) from openpyxl import Workbook
wb = Workbook()
wb1 = wb.create_sheet('房屋信息', 0)
wb1.append(['房屋名称','房屋街道','房屋详情','房屋关注度','房屋价格'])
for data in home_data:
wb1.append(data)
wb.save(r'home_info.xlsx')
openpyxl主要用于数据的写入,至于后续的表单操作它并不是很擅长,如果想做需要更高级的模块pandas
4. openpyxl读取数据
from openpyxl import load_workbook
# 1.指定读取的文件
wb = load_workbook(r'客户信息表.xlsx')
# 2.查看内部所有工作簿名称
print(wb.sheetnames) # ['Sheet', '客户名单1']
# 3.指定某个工作簿
wb1 = wb['客户名单1']
# 4.读取工作簿相关操作
print(wb1.max_row) # 获取最大数据行数 5
print(wb1.max_column) # 获取最大数据列数 1
print(wb1['A1'].value) # 读取单元格内容 12
print(wb1['A5'].value) # 如果是公式 读取的公式 # = sum(A1:A4)
按行和列读取数据:
for i in wb1.rows:
print([d.value for d in i]) for j in wb1.columns:
print([d.value for d in j])
网络爬虫之requests模块,自动办公领域之openpyx模块的更多相关文章
- python网络爬虫之使用scrapy自动登录网站
前面曾经介绍过requests实现自动登录的方法.这里介绍下使用scrapy如何实现自动登录.还是以csdn网站为例. Scrapy使用FormRequest来登录并递交数据给服务器.只是带有额外的f ...
- 网络爬虫之requests模块的使用+Github自动登入认证
本篇博客将带领大家梳理爬虫中的requests模块,并结合Github的自动登入验证具体讲解requests模块的参数. 一.引入: 我们先来看如下的例子,初步体验下requests模块的使用: ...
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 04,Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 06.Python网络爬虫之requests模块(2)
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python网络爬虫之requests模块(2)
session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 有些时候,我们在使用爬 ...
- Python网络爬虫之requests模块
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python3网络爬虫之requests动态爬虫:拉钩网
操作环境: Windows10.Python3.6.Pycharm.谷歌浏览器目标网址: https://www.lagou.com/jobs/list_Python/p-city_0?px=defa ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
随机推荐
- 使用Docker方式部署Mongodb多副本集(replSet)
linux主机ip:192.168.0.253 1. 创建网络与容器 docker pull mongo docker network create mongo-rs docker run --nam ...
- Beats:在 Beats 中实现动态 pipeline
转载自:https://blog.csdn.net/UbuntuTouch/article/details/107127197 在我们今天的练习中,我们将使用 Metricbeat 来同时监控 kib ...
- aardio + PowerShell 可视化快速开发独立 EXE 桌面程序
aardio 可以方便地调用 PowerShell ,PowerShell 中也可以自由调用 aardio 对象与函数.不用带上体积很大的System.Management.Automation.dl ...
- 关于Jenkins-Item-Office 365 Connector-下的多选框的参数定义
在Jenkins的Item中Office 365 Connector下,我们有时会使用到,多选框(复选框),目的是可选择多个多个条目赋值给指定的变量 然后在Build Triggers中可以进行引用, ...
- Hive之安装
Hive安装 1. 依赖hadoop(另有hadoop安装文档) 执行程序运行在yarn上面,需要启动start-yarn.sh 2. 先安装MySQL MySQL安装详见数据库MySQL之安装:ht ...
- Windows docker环境安装
前期准备 1.hyper-v功能 win10家庭版没有提供hyper-v的问题可通过如下脚本解决,保存为bat并运行重启电脑即可. pushd "%~dp0" dir /b %Sy ...
- 2022最新版超详细的Maven下载配置教程、IDEA中集成maven(包含图解过程)、以及导入项目时jar包下载不成功的问题解决
文章目录 1.maven下载 2.maven环境变量的配置 3.查看maven是否配置成功 4.配置文件的修改 5.IDEA集成maven 6.导入项目时jar包下载不成功的问题解决 maven教程: ...
- NLP之基于Transformer的句子翻译
Transformer 目录 Transformer 1.理论 1.1 Model Structure 1.2 Multi-Head Attention & Scaled Dot-Produc ...
- vue中动态引入图片为什么要是require, 你不知道的那些事
相信用过vue的小伙伴,肯定被面试官问过这样一个问题:在vue中动态的引入图片为什么要使用require 有些小伙伴,可能会轻蔑一笑:呵,就这,因为动态添加src被当做静态资源处理了,没有进行编译,所 ...
- PyGame做了一个扫雷
1 # 这是一个示例 Python 脚本. 2 3 # 按 ⌃R 执行或将其替换为您的代码. 4 # 按 双击 ⇧ 在所有地方搜索类.文件.工具窗口.操作和设置. 5 import sys 6 imp ...