Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似
Series数据选择方法
Series对象与一维Numpy数组 和标准的Python字典 在许多方面 都一样。
1)将Series看作字典
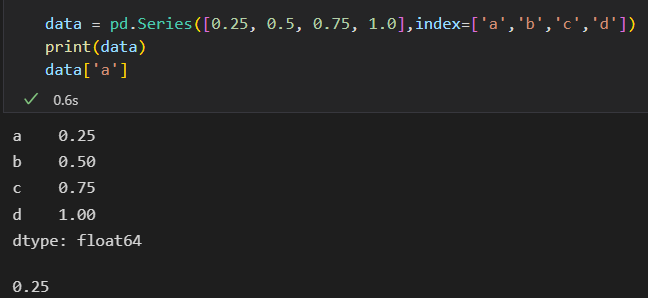
可以使用Python字典的表达式和方法来检查 键 和索引 值
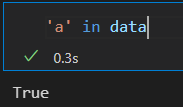
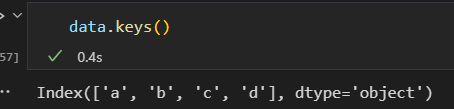
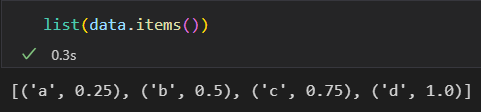
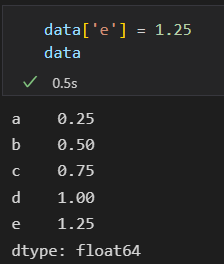
Series 可以新增,可以扩展。
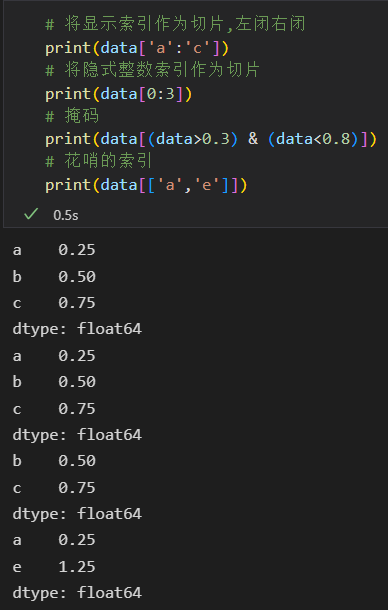
2)将Series看作一维数组
Series不仅有着和字典一样的接口,而且还具备和Numpy数组一样的数组 数据选择 包括 索引、掩码、花哨的索引等操作。
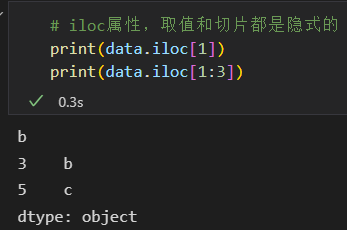
3)索引器:loc、iloc、ix
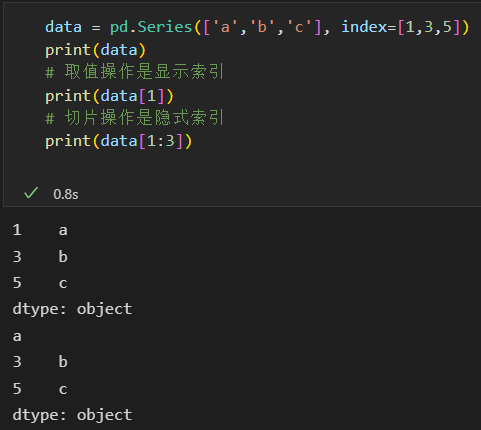
如果Series是显示整数索引,取值操作是显示索引,切片操作是隐式索引。
这样子就很容易混淆,索引Pandas提供了一些索引器(indexer)属性作为取值方法
loc 显示
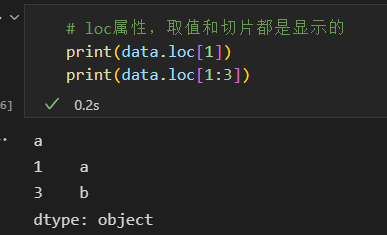
iloc 隐式
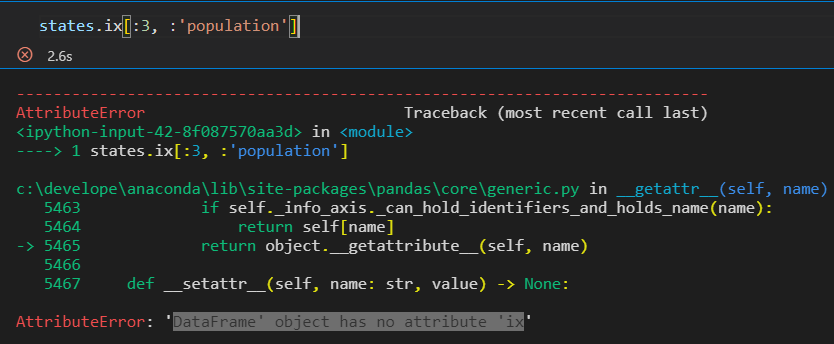
ix 是loc 和 iloc的混合形式,在Series对象中,ix等价与Python列表的取值方式。
ix主要用于DataFrame.
Python代码设计原则之一是“显示优于隐式”。 代码更容易维护 可读性更高。
DataFrame 数据选择方法
DataFrame像 二维或结构化数组,又像一个共享索引的若干Series对象的字典。
1)将DataFrame看作字典
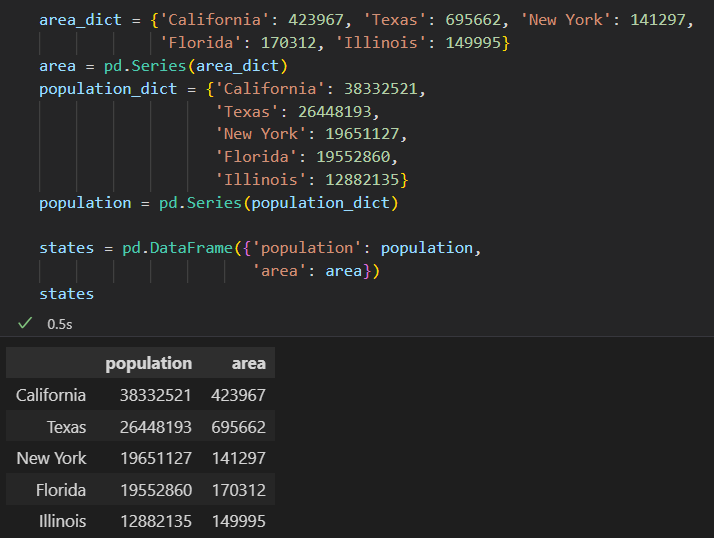
俩个Series分别构成DataFram的一列。可以通过列名进行字典形式的取值获取数据
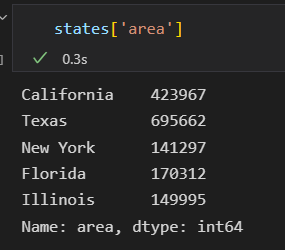
data['key'] 建议使用这个。
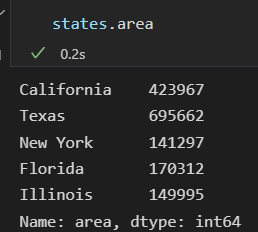
data.key
可以使用字典形式 调整对象,增加一列。
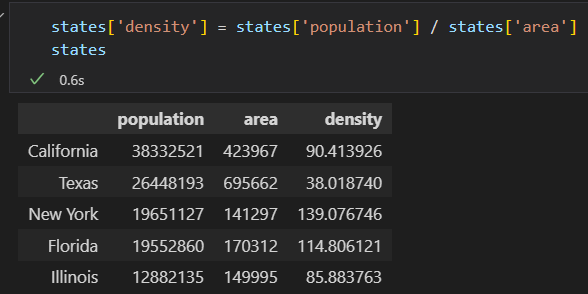
2)将DataFrame看作二维数组
DataFrame看出是一个增强版的二维数组。用values属性查看数组数据
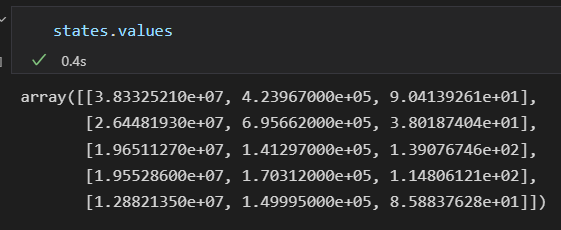
可以把许多对数组的操作用在DataFrame上
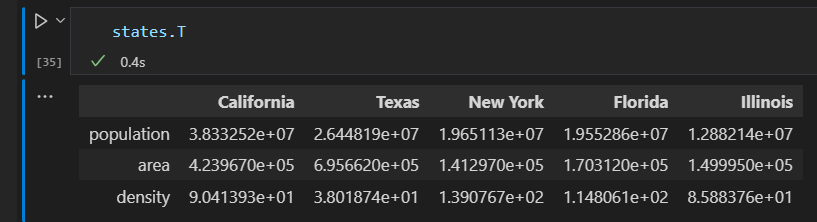
行列转置
获取一行数据。
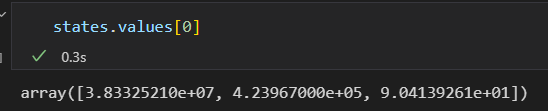
获取一列数据,需要向DataFrame传递单个列索引
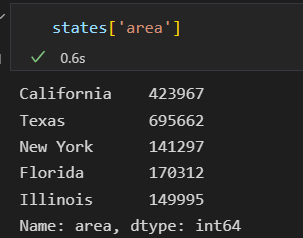
因此,进行数组形式的取值时, 需要使用索引器了。 隐式索引。 DataFrame的行列标签自动保留在结果中。

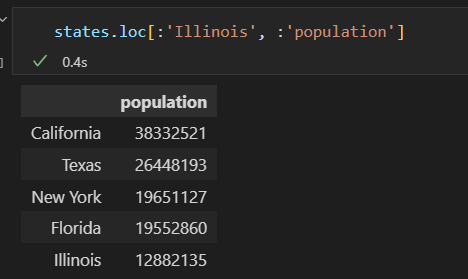
loc
ix 混合效果,新版本好像不支持了,被丢弃了。挺好。
Python数据科学手册-Pandas:数据取值与选择的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
随机推荐
- idea如何实现Servlet接口
idea如何实现Servlet接口 project structure ---> Libraries ---> 点击加号+ ----> 找到安装tomcat的目录,再找lib下的se ...
- 5-4 Seata 分布式事务管理
下载Seata https://github.com/seata/seata/releases https://github.com/seata/seata/releases/download/v1. ...
- Java 技术栈中间件优雅停机方案设计与实现全景图
欢迎关注公众号:bin的技术小屋,阅读公众号原文 本系列 Netty 源码解析文章基于 4.1.56.Final 版本 本文概要 在上篇文章 我为 Netty 贡献源码 | 且看 Netty 如何应对 ...
- &&与||的优先级比较
&&与||的优先级比较类似于一种思维体操,更多的是造成矛盾,使得两者因为先后顺序的不同而造成的不同结果,当然有时候需要注意c语言中的短路运算. 方法1. 代码如下: 点击查看代码 #i ...
- 自建docker仓库
一.仓库安装 1.系统:CentOS7.9,采用yum安装方式 [root@master ~]# yum install docker-distribution -y ... ... [root@ma ...
- centos 8及以上安装mysql 8.0
本文适用于centos 8及以上安装mysql 8.0,整体耗时20分钟内,不需要FQ 1.环境先搞好 systemctl stop firewalld //关闭防火墙 systemctl disab ...
- java 向上,向下取整详解
向上取整函数:Math.ceil(double a); 向下取整函数:Math.floor(double a); 需要注意的是:取整是对小数的取整,由于java自动转型机制,两个整数的运算结果依然是整 ...
- 使用Docker-compose来封装celery4.1+rabbitmq3.7服务,实现微服务架构
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_115 大家都知道,Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,在之前的一篇文章中:python3.7+Torn ...
- ansible一键安装GreatSQL并构建MGR集群
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 利用ansible一键安装GreatSQL并完成MGR部署. 本次介绍如何利用ansible一键安装GreatSQL并完成 ...
- GreatSQL MGR FAQ
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 目录 0. GreatSQL简介 1. GreatSQL的特色有哪些 2. Gr ...