[论文] FRCRN:利用频率递归提升特征表征的单通道语音增强
本文介绍了ICASSP2022 DNS Challenge第二名阿里和新加坡南阳理工大学的技术方案,该方案针对卷积循环网络对频率特征的提取高度受限于卷积编解码器(Convolutional Encoder-Decoder, CED)中卷积层有限的感受野的问题,将阿里达摩院之前的FSMN与发展自DCCRN/DCCRN的CRN with CCBAM结合。本文提出了一种频率递归卷积循环网络(frequency recurrence Convolutional Recurrent Network, FRCRN)框架在卷积循环编码器结构的基础上利用前馈顺序记忆网络(feedforward sequential memory network, FSMN)以提高沿频率特征的表征能力。具体而言,在CRED的每个卷积层之后利用FSMN沿频率维度对三维特征图(feature map)进行频率递归以建模范围更广的频率相关性并加强语音输入的特征表示;在编码器和解码器之间也插入了两个堆叠的FSMN层以进行时序建模。FRCRN在复数域预测复值理想比掩模(cIRM),并利用时频域和时域损失优化,在ICASSP2022 DNS Challenge中取得第二名。
论文题目:FRCRN: Boosting feature representation using frequency recurrence for monaural speech enhancement
作者:Shengkui Zhao, Bin Ma (阿里巴巴), Karn N. Watcharasupat, Woon-Seng Gan (新加坡南洋理工大学)
背景动机
CRN结构尤其是DCCRN在语音增强领域取得了优异的性能,但是卷积核有限的感受野限制了对频率维度的长范围建模。本文受DCCRN+中频率相关性建模研究的启发,提出了FRCRN以提高沿频率轴的特征表示。FRCRN在每个卷积之后加入一个用于频率递归的且相比LSTM参数量更小的FSMN层对特征图的沿频率轴建模,卷积层和频率递归层构成卷积递归(convolutional recurrent, CR)块。通过在编码器和解码器中叠加多个CR块来形成CRED,从而不仅能捕捉局地的时间谱结构,还能捕捉长范围的频率相关性。不像之DCCRN+只专注于建模时序关系,本工作专注于改进编码器-解码器结构的整体特征表征。整个模块如DCCRN+一样采用复值网络并估计复值理想比值掩码(cIRM),利用时频域和时域损失函数进行联合优化。
模型架构
模型处理的整体流程如下图,带噪信号经过STFT后送入网络,估计得到的cIRM与带噪复谱按复数规则相乘得到增强复谱,反变换得到增强语音。FRCRN主要由CRED和时序建模模块组成,其中CRED包括对称的编码器模块和解码器模块,两个模块都包含多个CR模块。时序建模模块由两个堆叠的复值FSMN (CFSMN)层组成,带CCBAM的跳跃连接(skip connection)连接编码器和解码器以促进信息流动。
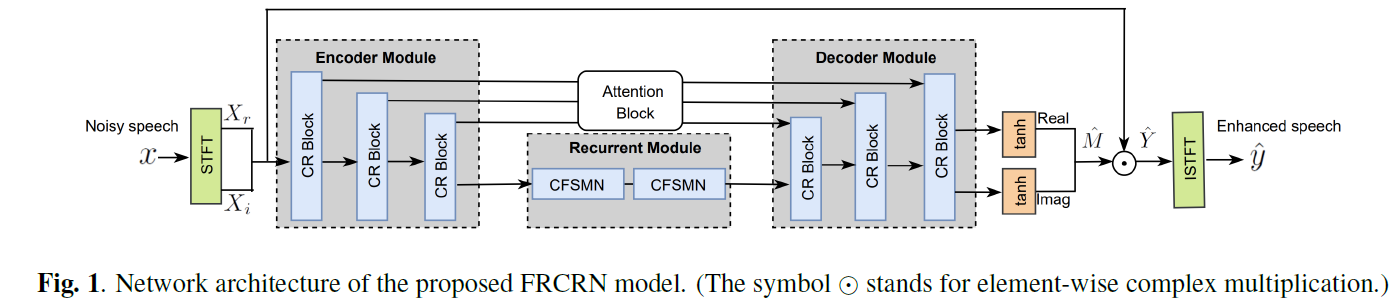
CR模块:由复值二维卷积层、复值BN、LeakyReLU和CFSMN层构成。复值二维卷积和复值BN操作可参看DCUNet或DCCRN论文。其中卷积层的kernel size在时间维和频率维上分别为(2,7),stide为(1,2),时间维通过补零保证因果性,频率维不补零,输出通道数均为128。
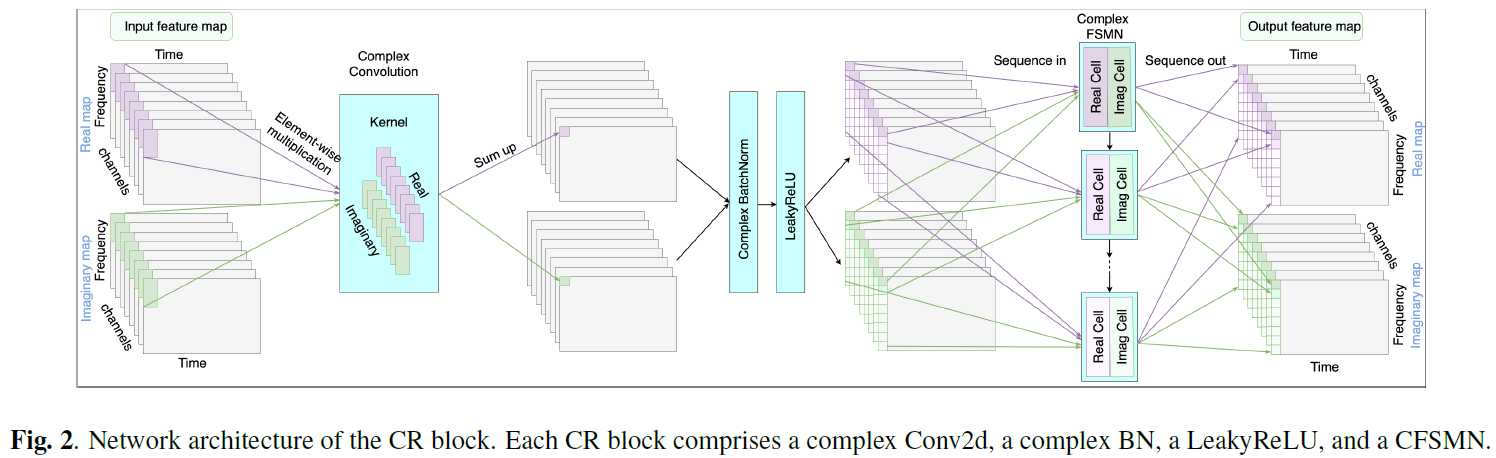
CFSMN可以暂且当成LSTM理解,CR中的CFSMN就是将频率特征维当作torch中的seq_len维度,通道维度当成torch中的input_size维度。其操作如下(和原文略有不同是因为已将文中参数带入公式):
Step1(置换操作,对每帧并行处理): \(U_{r/i} \in \mathcal{R}^{C \times T \times F} -> U_{r/i} \in \mathcal{R}^{T \times F \times C}\)
Step2(对当前帧): \(S_{r/i} = U_{r/i}[t,:,:] \in \mathcal{R}^{F \times C} =\{s_{f_1}, \cdots, s_{F}\}\)
Step3(FSMN层,共有两组,分别为\(FSMN_r\)和\(FSMN_i\)):
\(h_{f_i} = ReLU(W_{f_i} s_{f_i} + b_{f_i})\)
\(p_{f_i} = V_{f_i} h_{f_i} + v_{f_i}\)
\(s_{f_i} = s_{f_i} + p_{f_i} + \sum_{\tau=0}^{20}{a_{\tau} \cdot p_{f_i-\tau}}\)
Step4(复值操作):\(S = (FSMN_r(S_r)-FSMN_i(S_i)) + j(FSMN_r(S_i)+FSMN_i(S_r))\)
时序建模:将编码器输出的实(虚)部特征图频率特征维度和通道特征维度拉直成一维,而后对时间维进行CFSMN
CCBAM(个人补充):该模块参考了图像中的SENet并拓展到复制网络,即分别对通道维和语谱维做attention。通道维注意力机制是对特征做均值池化和最大值池化后经过两个线性层通过Sigmoid函数得到注意力得分;空间维注意力机制是对特征做完以上两种池化后通过Sigmoid得到注意力得分。示意图如下:
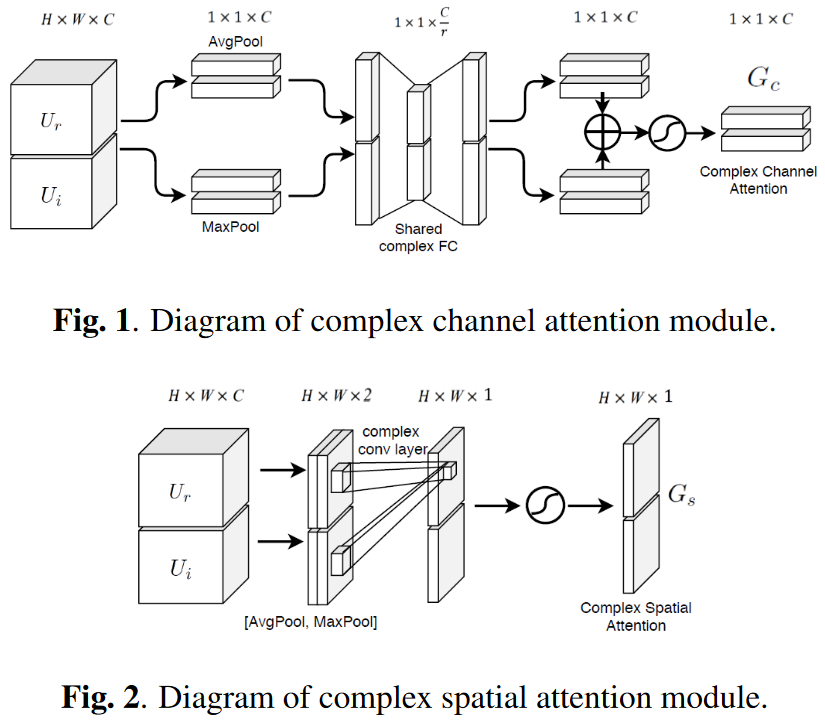
But,这里有个疑问是,如果只是这样简单地使用池化操作,在通道维注意力机制时是怎么保证模型因果的
损失函数:
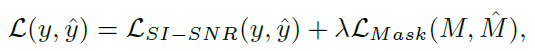
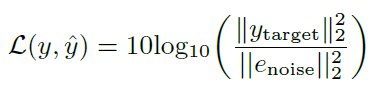
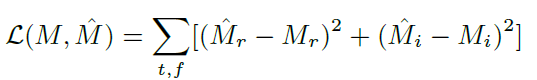
模型参数:编解码器中各有6个CR模块,时序建模中有两个CFSMN。帧长20ms帧移10ms,STFT点数为1920,按1-641,641-1282,1282-1921的频点索引将整个STFT谱分为三组并沿通道为拼接,即网络输入通道数为3。网络输出的cIRM为对于为1921。
数据与结果
共生成3000小时的数据用于训练和开发,其中30%带混响。信噪比在0~15dB之间随机选取
参数量10.27M,计算量12.30GMACS每秒
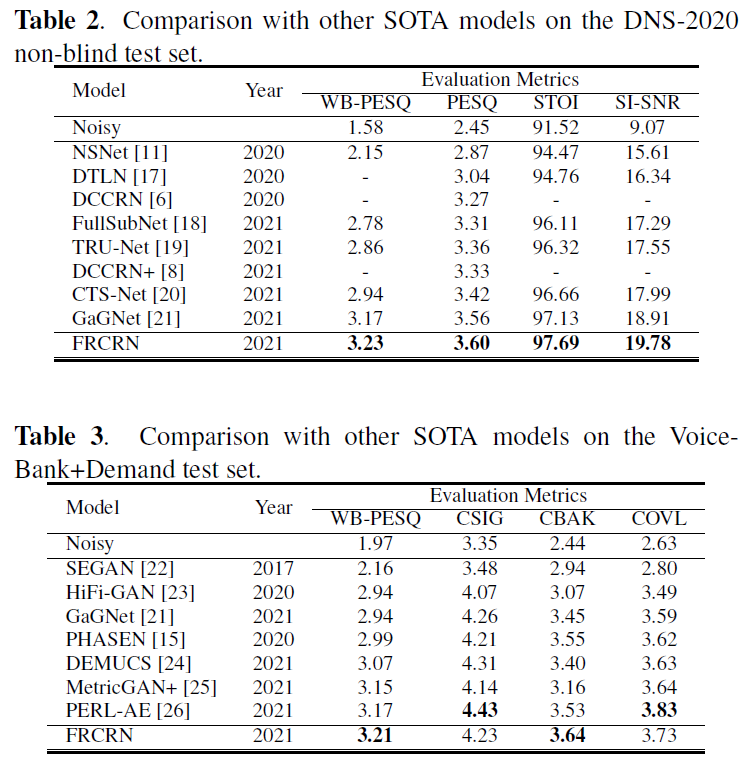
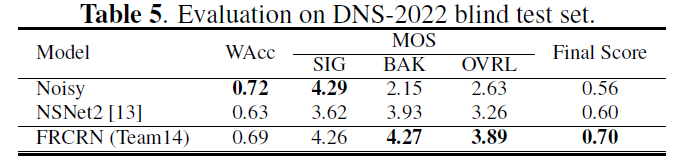
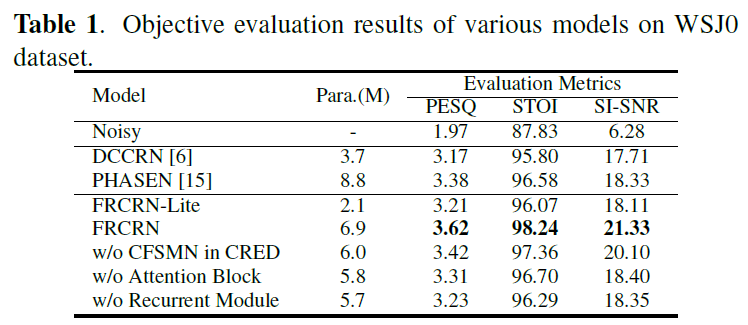
在DNS2020和VB-Demand中表现优异,DNS排名第二
消融实验说明了CFSMN频率递归、CCBAM和时序建模的有效性
[论文] FRCRN:利用频率递归提升特征表征的单通道语音增强的更多相关文章
- Dual Path Networks(DPN)——一种结合了ResNet和DenseNet优势的新型卷积网络结构。深度残差网络通过残差旁支通路再利用特征,但残差通道不善于探索新特征。密集连接网络通过密集连接通路探索新特征,但有高冗余度。
如何评价Dual Path Networks(DPN)? 论文链接:https://arxiv.org/pdf/1707.01629v1.pdf在ImagNet-1k数据集上,浅DPN超过了最好的Re ...
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- 【HEVC帧间预测论文】P1.1 基于运动特征的HEVC快速帧间预测算法
基于运动特征的 HEVC 快速帧间预测算法/Fast Inter-Frame Prediction Algorithm for HEVC Based on Motion Features <HE ...
- 如何利用动态URL提升SEO及处理业务逻辑
如果你正在建设一个新网站或者对现有网站重新设计,我们认为应该将网站的 URL 转换为用户友好的 URL,或搜索引擎友好的 URL,这类 URL 也称为语义 URL(Semantic URL).哪些UR ...
- 利用Delphi-cross-socket 库提升kbmmw 跨平台开发
以前我写过了,通过httpsys 提升windows 下,delphi 多层应用.随着delphi 10.2 对linux 的支持,很多人也想在linux 下 发布kbmmw 服务器,但是官方仅通过i ...
- 根据ID和parentID利用Java递归获取全路径名称
如下图所示,本文参考资源:https://jie-bosshr.iteye.com/blog/1996607 感谢大佬的无私奉献. 思路: 定义一个方法getParentName参数为int类型的c ...
- 利用 Label 小小的提升一下用户体验
label ,Html 标签里面很普通的一个,可是她却有一个很独特的作用,我不知道我是忘了她还是不曾记得她,下面简单介绍一下她. 一.定义和用法 <label> 标签为 input 元素定 ...
- python利用eval方法提升dataframe运算性能
eval方法可以直接利用c语言的速度,而不用分配中间数组,不需要中间内存的占用. 如果包含多个步骤,每个步骤都要分配一块内存 import numpy as npimport pandas as pd ...
- 在Angular中利用trackBy来提升性能
在Angular的模板中遍历一个集合(collection)的时候你会这样写: <ul> <li *ngFor="let item of collection"& ...
随机推荐
- SpringBoot集成SpringBootDataElasticSearch
先放出依赖: <parent> <groupId>org.springframework.boot</groupId> <artifactId>spri ...
- spring-boot关于spring全注解IOC
什么是IOC容器: Spring IoC 容器是一个管理Bean 的容器,在S pring 的定义中,它要求所有的IoC 容器都需要实现接口BeanFactory ,它是一个顶级容器接口 IoC 是一 ...
- Flask 简单使用,这一篇就够了!
#Flask 安装依赖包及作用 - jinja2 模板语言 (flask依赖包) - markupsafe 防止css攻击 (flask依赖包) - werkzeug --wkz 类似于django中 ...
- Java入门之基础程序设计
1.Java语言特点了解 1. java语言: 有些语言提供了可移植性.垃圾收集等机制,但是没有提供一个大型的库.如果想要有酷炫的绘图功能.网络连接功能或者数据库存取功能,就必须动手编写代码.Ja ...
- buuctf 荷兰带宽数据泄露
荷兰带宽数据泄露 下载附件得一个conf.bin文件,这个文件是路由信息文件,题目并没有任何提示,我们先来测试一下最简单的,找username或password然后当作flag交上去,我们使用Rout ...
- 单总线协议DS1820代码
单总线协议DS1820代码 一.DS18B20初始化 (1).数据线拉到低电平"0". (2).延时480微妙(该时间的时间范围可以从480到960微妙). (3).数据线拉到高电 ...
- 顺利通过EMC实验(4)
- CCF201512-2消除类游戏
问题描述 消除类游戏是深受大众欢迎的一种游戏,游戏在一个包含有n行m列的游戏棋盘上进行,棋盘的每一行每一列的方格上放着一个有颜色的棋子,当一行或一列上有连续三个或更多的相同颜色的棋子时,这些棋子都被消 ...
- h5页面跳转小程序
2020年以前, 只能通过 web-view内嵌h5跳转小程序,现在 可以直接跳了!!!!!! 官方文档:https://developers.weixin.qq.com/doc/offiacco ...
- 彻底理解synchronized
1. synchronized简介 在学习知识前,我们先来看一个现象: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public ...