ELK日志保留7天-索引生命周期策略
一、简介
ELK日志我们一般都是按天存储,例如索引名为"kafkalog-2022-04-05",因为日志量所占的存储是非常大的,我们不能一直保存,而是要定期清理旧的,这里就以保留7天日志为例。
自动清理7天以前的日志可以用定时任务的方式,这样就需要加入多一个定时任务,可能不同服务记录的索引名又不一样,这样用定时任务配还是没那么方便。
ES给我们提供了一个索引的生命周期策略(lifecycle),就可以对索引指定删除时间,能很好解决这个问题。
索引生命周期分为四个阶段:HOT(热)=>WARM(温)=》COLD(冷)=>DELETE(删除)
二、给索引设生命周期策略(ILM)
1.配置生命周期策略(policy)
这里为ELK日志超过7天的自动删除,所以只需要用到DELETE(删除阶段)
PUT _ilm/policy/auto_delete_policy
{
"policy": {
"phases": {
"delete": {
"min_age": "7d",
"actions": {
"delete": {}
}
}
}
}
}
创建一个自动删除策略(auto_delete_policy)
delete:删除阶段,7天执行删除索引动作
查看策略:GET _ilm/policy/
2.创建索引模板
索引模板可以匹配索引名称,匹配到的索引名称按这个模板创建mapping
PUT _template/elk_template
{
"index_patterns": ["kafka*"],
"settings": {
"index":{
"lifecycle":{
"name":"auto_delete_policy",
"indexing_complete":true
}
} }
}
创建索引模板(elk_tempalte),index.lifecycle.name把上面的自动删除策略绑定到elk索引模板
创建kafka开头的索引时就会应用这个模板。
indexing_complete:true,必须设为true,跳过HOT阶段的Rollover
查看模板:GET /_template/
3.测试效果
logstash配置:
logstash接收kafka的输入,输出到es。
input {
kafka {
type=>"log1"
topics => "kafkalog" #在kafka这个topics提取数据
bootstrap_servers => "127.0.0.1:9092" # kafka的地址
codec => "json" # 在提取kafka主机的日志时,需要写成json格式
}
}
output {
if [type] =="log1"
{
elasticsearch {
hosts => ["127.0.0.1:9200"] #es地址
index => "kafkalog%{+yyyy.MM.dd}" #把日志采集到es的索引名称
# user => "elastic"
# password => "123456"
}
}
}
这里测试时把DELETE的日期又7天"7d"改为1分钟"1m"。
生命周期策略默认10分钟检测一次,为了方便测试,这里设为30s。
PUT /_cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval":"30s"
}
}
把日志写入到es后,查看日志索引的生命周期策略信息。
GET kafka*/_ilm/explain 查看kafka开头索引的生命周期策略
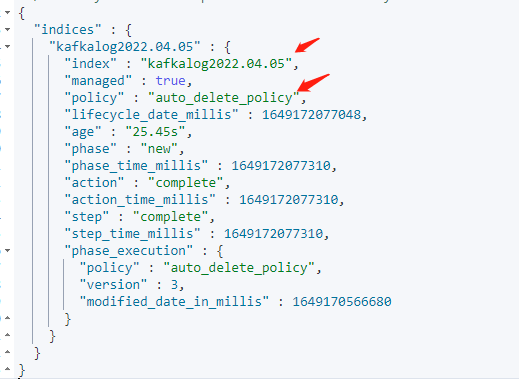
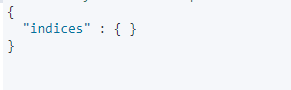
过一会再点查询,索引已经没有了,说明已经生效。
ELK日志保留7天-索引生命周期策略的更多相关文章
- Elasticsearch7.X ILM索引生命周期管理(冷热分离)
Elasticsearch7.X ILM索引生命周期管理(冷热分离) 一.“索引生命周期管理”概述 Elasticsearch索引生命周期管理指:Elasticsearch从设置.创建.打开.关闭.删 ...
- Elasticsearch索引生命周期管理方案
一.前言 在 Elasticsearch 的日常中,有很多如存储 系统日志.行为数据等方面的应用场景,这些场景的特点是数据量非常大,并且随着时间的增长 索引 的数量也会持续增长,然而这些场景基本上只有 ...
- ELK 索引生命周期管理
kibana 索引配置 管理索引 点击设置 --- Elasticsearch 的 Index management 可以查看 elk 生成的所有索引 (设置,Elasticsearch ,管理) 配 ...
- Elastic 使用索引生命周期管理实现热温冷架构
Elastic: 使用索引生命周期管理实现热温冷架构 索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能.ILM 是 Elast ...
- 这么简单的ES索引生命周期管理,不了解一下吗~
对于日志或指标(metric)类时序性强的ES索引,因为数据量大,并且写入和查询大多都是近期时间内的数据.我们可以采用hot-warm-cold架构将索引数据切分成hot/warm/cold的索引.h ...
- Elasticsearch 索引生命周期管理 ILM 实战指南
文章转载自:https://mp.weixin.qq.com/s/7VQd5sKt_PH56PFnCrUOHQ 1.什么是索引生命周期 在基于日志.指标.实时时间序列的大型系统中,集群的索引也具备类似 ...
- Logstash & 索引生命周期管理(ILM)
Grok语法 Grok是通过模式匹配的方式来识别日志中的数据,可以把Grok插件简单理解为升级版本的正则表达式.它拥有更多的模式,默认,Logstash拥有120个模式.如果这些模式不满足我们解析日志 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- ElasticSearch——索引生命周期管理
从ES6.6开始,Elasticsearch提供索引生命周期管理功能,索引生命周期管理可以通过API或者kibana界面配置,详情参考[index-lifecycle-management] 本文仅通 ...
随机推荐
- 20192204李龙威 2019-2020-2 《Python程序设计》实验一报告
20192204 2019-2020-2 <Python程序设计>实验一报告 课程:<Python程序设计> 班级: 1922 姓名: 李龙威 学号:20192204 实验教师 ...
- BSOJ6387题解
算是刷新了我对树上问题的认知 首先第一问随便做一个 \(O(nk)\) 的 DP 就可以草过去,考虑第二问. 我们将问题分为两个部分:走儿子边的答案和走父亲边的答案.最后拼接一下就好了. 设 \(fd ...
- es6 快速入门 系列 —— 对象
其他章节请看: es6 快速入门 系列 对象 试图解决的问题 写法繁杂 属性初始值需要重复写 function createPeople(name, age){ // name 和 age 都写了 2 ...
- nf-Press —— 在线文档也可以加载组件和编写代码
如果帮助文档可以加载组件,那么在介绍的同时就可以运行演示demo,是不是很酷? 如果可以在线修改运行代码,那么是不是更容易理解? 上一篇 https://www.cnblogs.com/jyk/p/1 ...
- Django基础八之认证模块---auth
Django基础八之认证模块---auth 目录 Django基础八之认证模块---auth 1. auth介绍 2. autho常用操作 2.1 创建用户 2.2 验证用户 2.3 验证用户是否登录 ...
- Windows下载安装RabbitMQ教程-------报错卸载重新安装 (要卸载干净 -看下文)
Could not update enabled plugins file at c:\Users\忙聸鹿忙聳掳忙聰戮\AppData\Roaming\RabbitMQ\enabled_plugins ...
- Java案例——反转字符串
/*案例:将用户输入的字符串反转并输出 分析:1.使用Scanner 类获取用户输入的字符串 2.定义一个方法将字符串反着遍历并拼接 3.定义变量接受并输出* */public class Strin ...
- mysql优化参数 (汇总)
1 如下为128G内存32线程处理器的mariadb配置参数优化: [client]#password= your_passwordport= 3306 socket= /tmp/mysql.sock ...
- redis不重启,切换到RDB备份到AOF备份
redis不重启,切换RDB备份到AOF备份 确保redis版本在2.2以上 查看redis版本 redis-server -v 实验环境准备 本文是在redis4.0中,通过config set命令 ...
- Django1.11 添加markdown语法支持
pip install markdown 在view.py 的视图界面:导入,圈起来的那两个包 对post进行处理, models.py 详情如下 测试,效果如图