下载nltk数据包报错
安装nltk需要两步:安装nltk和安装nltk_data数据包
安装nltk
安装nltk很简单,可以直接在pycharm环境中安装,flie —> settings—> Python Interpreter —> 点击+ —> 搜索nltk —> intall Package
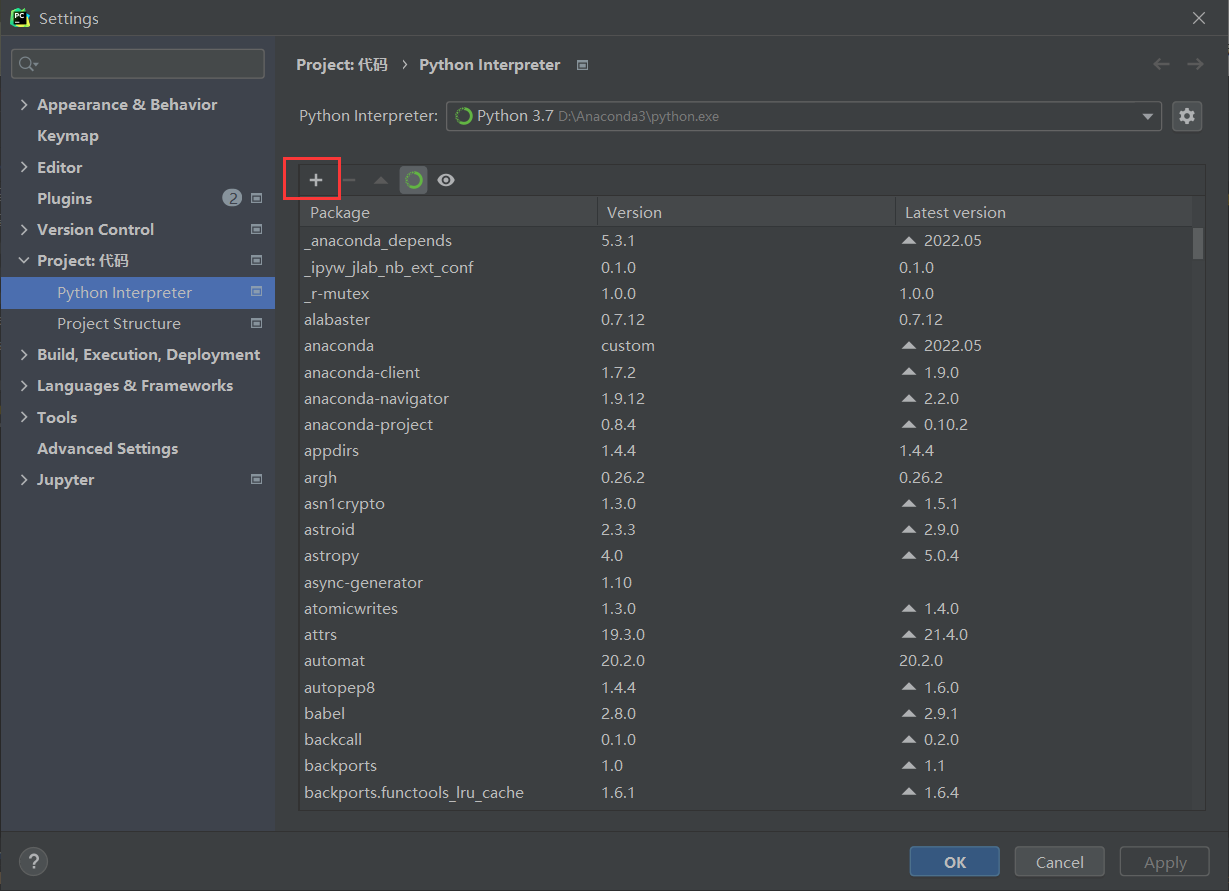
接下来需要安装nltk_data数据包才能使用nltk
手动安装nltk
最简单的办法:在pychram里使用下面两行代码安装:
1 import nltk
2 nltk.download()
但通常这样安装都会提示:getaddrinfo failed
这是因为这里自动弹出的server index里提供的网址找不到对应的IP
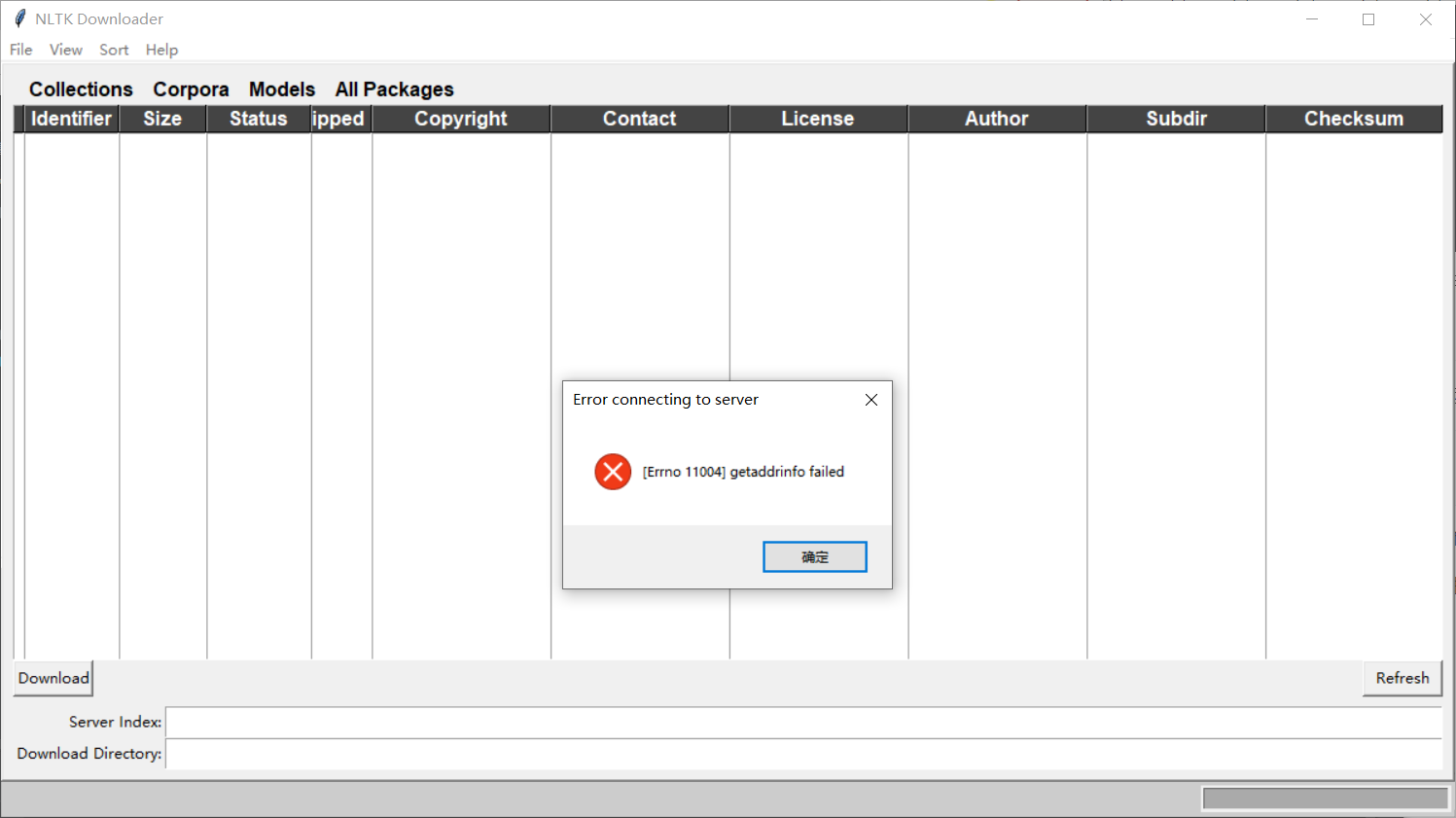
可见,直接代码安装不行
因为其他方法我都试过了,都没有成功,这里推荐我试了之后成功的方法
先进入这个网站:https://github.com/nltk/nltk_data/tree/gh-pages
依次点击Code—>Download Zip下载压缩包
接着执行以下代码:
1 import nltk
2 from nltk_book import *
因为此时还没有安装nltk_data安装包,它会提示找不到数据,并且提示他找数据时的默认路径:
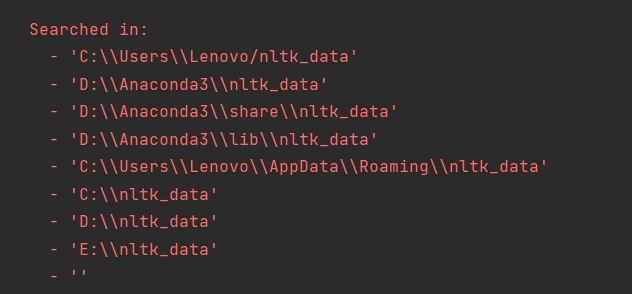
所以我们把nltk_data安装包里packages里的这些文件解压到上述任意路径,重命名为nltk_data即可,我解压到D:\Anaconda3
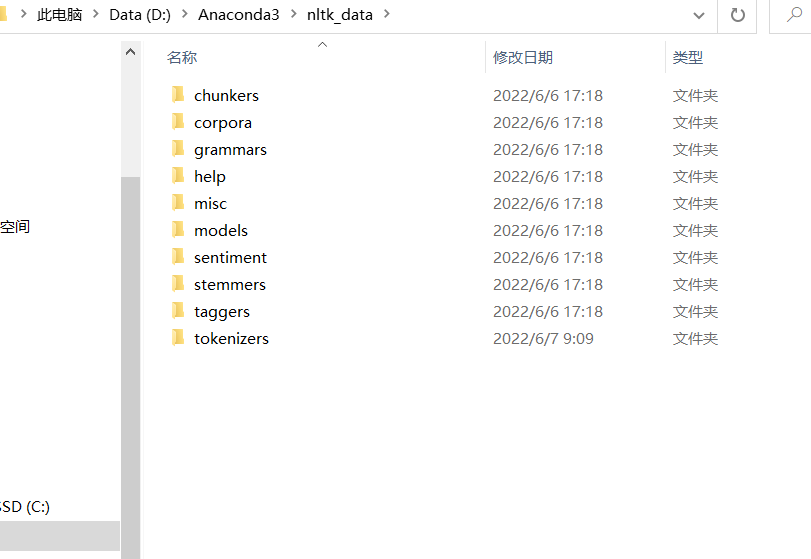
注意:下载下来的压缩包中,除了packages还有其他文件,这里只需要把packages中的文件就行。我之前就是因为直接把下载下来的压缩包全部解压到Aconda3中,导致后面验证的时候还是一直报错找不到数据!!!
完后以上步骤,执行下面代码试验一下有没有安装成功
1 import nltk
2 from nltk.book import *
出现以下内容,即成功!
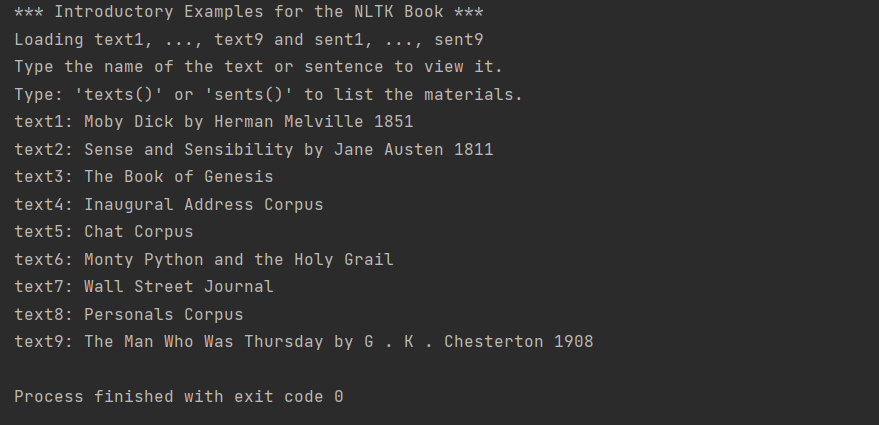
注意:在Github上下载的这个压缩数据包,里面的一些子文件夹下还有压缩内容,例如,如果调用nltk进行句子分割,会用到这个函数: word_tokenize():
1 import nltk
2
3 sen = 'hello, how are you?'
4 res = nltk.word_tokenize(sen)
5 print(res)
会提示 Resource punkt not found. Please use the NLTK Downloader to obtain the resource: 即punkt数据未找到:
类似这样的错误,其实如果找到查找的路径,也就是上面我们放数据包的地方,是可以在tokenizers文件夹下找到这个punkt的,原因就在于没有解压,那么,把punkt.zip解压到文件夹中,再运行分割句子的代码就没问题了。如果有其他的一些数据也是这样的,如果遇到显示没有找到某个数据包,不妨试一试。(如果打开其他的文件夹,发现里面也有未解压的那些文件,我们可以手动将其解压)
下载nltk数据包报错的更多相关文章
- maven 导包报错
作为初学者本应当是持之以恒的但是很长时间没有冒泡了这次冒个泡写maven项目的时候遇到了很多的bug,今天给大家分享一下解决的办法(常见的错误就是导不进来自己想要的包)要么就是导包报错以下是解决方法 ...
- 解决windows下rstudio安装playwith包报错问题
一.playwith包简介 playwith包提供了一个GTK+图形用户界面(GUI),使得用户可以编辑R图形并与其交互.playwith()函数允许用户识别和标注点.查看一个观测所有的变量值.缩放和 ...
- flask+sqlite3+echarts2+ajax数据可视化报错:UnicodeDecodeError: 'utf8' codec can't decode byte解决方法
flask+sqlite3+echarts2+ajax数据可视化报错: UnicodeDecodeError: 'utf8' codec can't decode byte 解决方法: 将 py文件和 ...
- 关于Spring运用过程中jar包报错问题
使用Spring进行web开发时,第一步就是导入jar包,今天使用SPring Task开发定时器时,导入了好多次jar包,都是报错,不知道是因为jar包版本不同还是因为需要依赖的jar包没加入,反正 ...
- 编译APR包报错 rm: cannot remove `libtoolT': No such file or directory
centos 6 编译APR包报错 在当前apr 目录 : #Vi configure +31880 ,注释掉此行 再次编译即可.
- eclispe集成Scalas环境后,导入外部Spark包报错:object apache is not a member of package org
在Eclipse中集成scala环境后,发现导入的Spark包报错,提示是:object apache is not a member of package org,网上说了一大推,其实问题很简单: ...
- 数据导入报错:Got a packet bigger than‘max_allowed_packet’bytes的问题
数据导入报错:Got a packet bigger than‘max_allowed_packet’bytes的问题 2个解决方法: 1.临时修改:mysql>set global max_a ...
- PyCharm导入tensorflow包报错的问题
[注]PyCharm导入tensorflow包报错的问题 若是你也遇到这个问题,说明你也没有理解tensorflow到底在哪里. 当安装了anaconda3.6后,在PyCharm中设置interpr ...
- 数据导入报错 Got a packet bigger than‘max_allowed_packet’bytes
数据导入报错:Got a packet bigger than‘max_allowed_packet’bytes的问题 2个解决方法: 1.临时修改:mysql>set global max_a ...
随机推荐
- echarts饼图禁止鼠标悬浮区块突出
禁止悬浮突出,在series内添加hoverAnimation:false即可 代码如下: option = { color:['#3498db','#EEEEEE'], series: [ { na ...
- RPC及Dubbo和ZooKeeper的安装
RPC及Dubbo和ZooKeeper的安装 RPC 通信有两种方式:HTTP(无状态协议,通信协议),RPC(远程过程调用) 它两的本质没有区别,只是功能有点不一样 官方解释: RPC是指远程过程调 ...
- 微信小程序组件封装及调用-原生
封装一个弹窗组件 1.新建component文件夹存放我们的组件,里边存放的就是我们所用的组件,我们今天要做的事弹出框,新建文件夹popup存放我们的组件模板,点击右键选择新建component,就会 ...
- 2021-01-25 cf #697 Div3 C题(超时,换思路减少复杂度)
题目链接:https://codeforces.com/contest/1475/problem/C 题意要求:需组成的2对,男的序号不能重,女的序号不能重 比如这例 输入: 行1--测试个数 行1` ...
- 2021.08.06 P4392 Sound静音问题(ST表)
2021.08.06 P4392 Sound静音问题(ST表) [P4392 BOI2007]Sound 静音问题 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题意: 序列a,求 ...
- SQL语言详解
SQL 1. 概述 Structured Query Language 结构化查询语言 结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言, ...
- bat脚本删除一周前的文件
bat脚本删除7天前的文件 @echo off forfiles /p D:\logstash-1.4.2\bin\ /m *.log -d -7 /C "cmd /c del /f @pa ...
- 【笔记】PyTorch快速入门:基础部分合集
PyTorch快速入门 Tensors Tensors贯穿PyTorch始终 和多维数组很相似,一个特点是可以硬件加速 Tensors的初始化 有很多方式 直接给值 data = [[1,2],[3, ...
- Docker系列教程03-Docker私有仓库搭建(registry)
简介 仓库(Repository)是集中存放镜像的地方,又分为公共镜像和私有仓库. 当我们执行docker pull xxx的时候,它实际上是从registry.docker.com这个地址去查找,这 ...
- CentOS 8及以上版本配置IP的方法,你 get 了吗
接上篇文章讲了 Ubuntu 18及以上版本的配置方法,本文再来讲讲 CentOS 8 及以上版本配置 IP 的方法. Centos/Redhat(8.x) 配置 IP 方法 说明:CentOS 8 ...