C# 多线程网络爬虫
上次做了一个帮公司妹子做了爬虫,不是很精致,这次公司项目里要用到,于是有做了一番修改,功能添加了网址图片采集,下载,线程处理界面网址图片下载等。
说说思路:首相获取初始网址的所有内容 在初始网址采集图片 去初始网址采集链接 把采集到的链接放入队列 继续采集图片,然后继续采集链接,无限循环
还是上图片大家看一下:
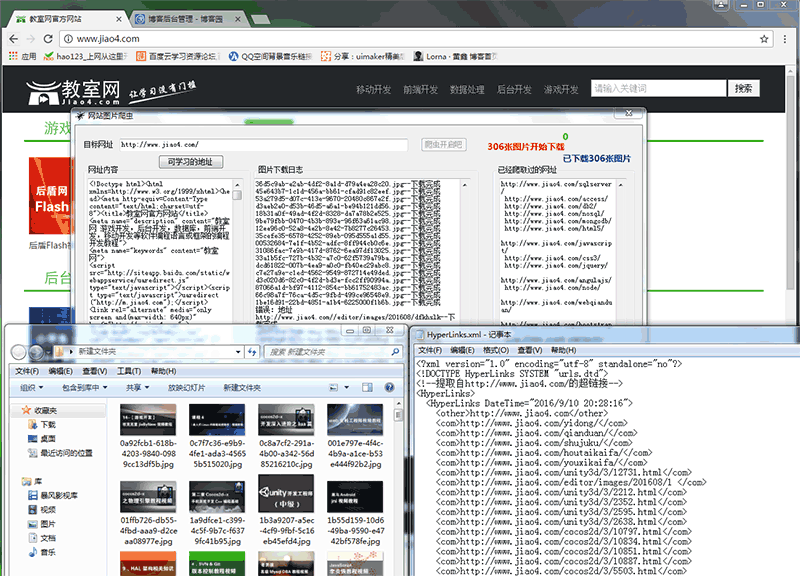
处理网页内容抓取跟网页网址爬取都做了改进,下面还是大家来看看代码,有不足之处,还请之处!
网页内容抓取HtmlCodeRequest,
网页网址爬取GetHttpLinks,用正则去筛选html中的Links
图片抓取GetHtmlImageUrlList,用正则去筛选html中的Img
都写进了一个封装类里面 HttpHelper
/// <summary>
/// 取得HTML中所有图片的 URL。
/// </summary>
/// <param name="sHtmlText">HTML代码</param>
/// <returns>图片的URL列表</returns>
public static string HtmlCodeRequest(string Url)
{
if (string.IsNullOrEmpty(Url))
{
return "";
}
try
{
//创建一个请求
HttpWebRequest httprequst = (HttpWebRequest)WebRequest.Create(Url);
//不建立持久性链接
httprequst.KeepAlive = true;
//设置请求的方法
httprequst.Method = "GET";
//设置标头值
httprequst.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
httprequst.Accept = "*/*";
httprequst.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5");
httprequst.ServicePoint.Expect100Continue = false;
httprequst.Timeout = ;
httprequst.AllowAutoRedirect = true;//是否允许302
ServicePointManager.DefaultConnectionLimit = ;
//获取响应
HttpWebResponse webRes = (HttpWebResponse)httprequst.GetResponse();
//获取响应的文本流
string content = string.Empty;
using (System.IO.Stream stream = webRes.GetResponseStream())
{
using (System.IO.StreamReader reader = new StreamReader(stream, System.Text.Encoding.GetEncoding("utf-8")))
{
content = reader.ReadToEnd();
}
}
//取消请求
httprequst.Abort();
//返回数据内容
return content;
}
catch (Exception)
{ return "";
}
}
/// <summary>
/// 提取页面链接
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
public static List<string> GetHtmlImageUrlList(string url)
{
string html = HttpHelper.HtmlCodeRequest(url);
if (string.IsNullOrEmpty(html))
{
return new List<string>();
}
// 定义正则表达式用来匹配 img 标签
Regex regImg = new Regex(@"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""'<>]*)[^<>]*?/?[\s\t\r\n]*>", RegexOptions.IgnoreCase); // 搜索匹配的字符串
MatchCollection matches = regImg.Matches(html);
List<string> sUrlList = new List<string>(); // 取得匹配项列表
foreach (Match match in matches)
sUrlList.Add(match.Groups["imgUrl"].Value);
return sUrlList;
} /// <summary>
/// 提取页面链接
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
public static List<string> GetHttpLinks(string url)
{
//获取网址内容
string html = HttpHelper.HtmlCodeRequest(url);
if (string.IsNullOrEmpty(html))
{
return new List<string>();
}
//匹配http链接
const string pattern2 = @"http(s)?://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List<string> links = new List<string>();
foreach (Match url2 in m2)
{
if (StringHelper.CheckUrlIsLegal(url2.ToString()) || !StringHelper.IsPureUrl(url2.ToString()) || links.Contains(url2.ToString()))
continue;
links.Add(url2.ToString());
}
//匹配href里面的链接
const string pattern = @"(?i)<a\s[^>]*?href=(['""]?)(?!javascript|__doPostBack)(?<url>[^'""\s*#<>]+)[^>]*>"; ;
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
foreach (Match url1 in m)
{
string href1 = url1.Groups["url"].Value;
if (!href1.Contains("http"))
{
href1 = Global.WebUrl + href1;
}
if (!StringHelper.IsPureUrl(href1) || links.Contains(href1)) continue;
links.Add(href1);
}
return links;
}
这边下载图片有个任务条数限制,限制是200条。如果超过的话线程等待5秒,这里下载图片是异步调用的委托
public string DownLoadimg(string url)
{
if (!string.IsNullOrEmpty(url))
{
try
{
if (!url.Contains("http"))
{
url = Global.WebUrl + url;
}
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Timeout = ;
request.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
//是否允许302
request.AllowAutoRedirect = true;
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
//文件名
string aFirstName = Guid.NewGuid().ToString();
//扩展名
string aLastName = url.Substring(url.LastIndexOf(".") + , (url.Length - url.LastIndexOf(".") - ));
FileStream writer = new FileStream(Global.FloderUrl + aFirstName + "." + aLastName, FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[];
//实际读取的字节数
int c = ;
while ((c = reader.Read(buff, , buff.Length)) > )
{
writer.Write(buff, , c);
}
writer.Close();
writer.Dispose();
reader.Close();
reader.Dispose();
response.Close();
return (aFirstName + "." + aLastName);
}
catch (Exception)
{
return "错误:地址" + url;
}
}
return "错误:地址为空";
}
话不多说,更多的需要大家自己去改进咯!
C# 多线程网络爬虫的更多相关文章
- crawler4j:轻量级多线程网络爬虫实例
crawler4j是Java实现的开源网络爬虫.提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫. 下面实例结合jsoup(中文版API),javacvs 爬取自如租房网(http://sh ...
- crawler4j:轻量级多线程网络爬虫
crawler4j是Java实现的开源网络爬虫.提供了简单易用的接口,可以在几分钟内创建一个多线程网络爬虫. 安装 使用Maven 使用最新版本的crawler4j,在pom.xml中添加如下片段: ...
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- 网络爬虫(java)
陆陆续续做了有一个月,期间因为各种技术问题被多次暂停,最关键的一次主要是因为存储容器使用的普通二叉树,在节点权重相同的情况下导致树高增高,在进行遍历的时候效率大大降低,甚至在使用递归的时候导致栈 ...
- 开源的49款Java 网络爬虫软件
参考地址 搜索引擎 Nutch Nutch 是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. Nutch的创始人是Doug Cutting, ...
- [搜片神器]之DHT网络爬虫的C++程序初步开源
回应大家的要求,特地整理了一开始自己整合的代码,这样最简单,最直接的可以分析流程,至于文章里面提供的程序界面更多,需要大家自己开发. 谢谢园子朋友的支持,已经找到个VPS进行测试,国外的服务器: ht ...
- 网络爬虫系统Heritrix的结构分析 (个人读书报告)
摘要 随着网络时代的日新月异,人们对搜索引擎,网页的内容,大数据处理等问题有了更多的要求.如何从海量的互联网信息中选取最符合要求的信息成为了新的热点.在这种情况下,网络爬虫框架heritrix出现 ...
- 一个简单的多线程Python爬虫(一)
一个简单的多线程Python爬虫 最近想要抓取拉勾网的数据,最开始是使用Scrapy的,但是遇到了下面两个问题: 前端页面是用JS模板引擎生成的 接口主要是用POST提交参数的 目前不会处理使用JS模 ...
- 网络爬虫的C++程序
[搜片神器]之DHT网络爬虫的C++程序初步开源 回应大家的要求,特地整理了一开始自己整合的代码,这样最简单,最直接的可以分析流程,至于文章里面提供的程序界面更多,需要大家自己开发. 谢谢园子朋友的支 ...
随机推荐
- structs spring hibernate 三者之间有什么关系?
现在开发流行MVC模式,structs在C(控制器)中使用:hibernate在M(模型)中被使用:至于 spring ,最大的作用在于,structs.hibernate的对象,由于在各个层之间相互 ...
- grunt下cssmin的配置参数
每个目标的具体设置,需要参考该模板的文档minify目标的参数具体含义如下: expand:如果设为true,就表示下面文件名的占位符(即*号)都要扩展成具体的文件名. cwd:需要处理的文件(inp ...
- IT 基础设施
http://www.cnblogs.com/wintersun/p/4355267.html
- linux 查看局域网内ip
$ sudo apt-get install nmap $ nmap -sP 192.168.1.1/24 windows 下直接arp -a就能看到.
- 虚函数(virtual)为啥不能是static
静态成员函数,可以不通过对象来调用,即没有隐藏的this指针. virtual函数一定要通过对象来调用,即有隐藏的this指针. static成员没有this指针是关键!static function ...
- OpenCV在Android平台上的应用
今年8月份, OpenCV 2.3.1发布了. 虽然从2.2开始, OpenCV就号称支持Android平台, 但真正能让OpenCV在Android上运行起来还是在2.3.1版本上. 在这个版本上, ...
- (3)TXT转为XML
<?xml version="1.0" encoding="utf-8"?> <bocb2e> <head /> <t ...
- Atheros AR9485 ubuntu 10.04 驱动安装及networking disable问题解决
Laptop: ACER Aspire 5733-6629 Wireless:Lite-on HB125, CHIPS: Atheros AR9485 Ubuntu: 10.04LTS (2.6.32 ...
- RAPIDXML 中文手册,根据官方文档完整翻译!
简介:这个号称是最快的DOM模型XML分析器,在使用它之前我都是用TinyXML的,因为它小巧和容易上手,但真正在项目中使用时才发现如果分析一个比较大的XML时TinyXML还是表现一般,所以我们决定 ...
- PL/SQL Developer自动补全SQL技巧
s = SELECT t.* FROM t w = WHERE b = BETWEEN AND l = LIKE '%%' o = ORDER BY insw = IN (SELECT a FROM ...