hadoop vs spark
http://www.zhihu.com/question/26568496#answer-12035815
Hadoop
首先看一下Hadoop解决了什么问题,Hadoop就是解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。
- HDFS,在由普通PC组成的集群上提供高可靠的文件存储,通过将块保存多个副本的办法解决服务器或硬盘坏掉的问题。
- MapReduce,通过简单的Mapper和Reducer的抽象,将并发、分布式(如机器间通信)和故障恢复等计算细节隐藏起来,并在一个由几十台上百太的PC组成的不可靠集群上,提供可靠的数据处理。而Mapper和Reducer的抽象,又是各种各样的复杂数据处理都可以分解为的基本元素。这样,复杂的数据处理可以分解为由多个Mapper和Reducer组成的有向无环图(DAG),然后每个Mapper和Reducer放到Hadoop集群上执行,就可以得出结果。
用MapReduce统计一个文本文件中单词出现的频率的示例WordCount请参见:WordCount - Hadoop Wiki
在MapReduce中,Shuffle是一个非常重要的过程,有了看不见的Shuffle过程,才可以使在MapReduce之上写数据处理的开发者完全感知不到分布式和并发的存在。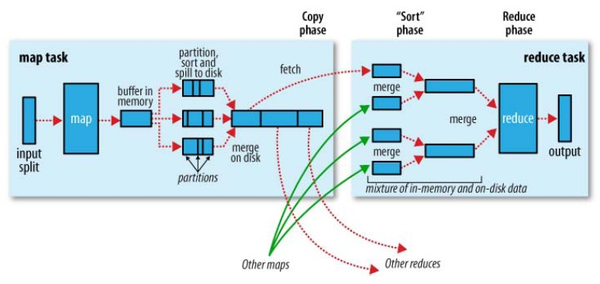 (图片来源: Hadoop Definitive Guide By Tom White)
(图片来源: Hadoop Definitive Guide By Tom White)
但是MapRecue存在以下局限,使用起来比较困难
- 抽象层次低,需要手工编写代码来完成,使用上难以上手。
- 只提供两个操作,Map和Reduce,表达力欠缺。
- 一个Job只有Map和Reduce两个阶段,复杂的计算需要大量的Job完成。
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- 中间结果也放在文件系统中
- ReduceTask需要等待所有MapTask都完成后才可以开始
- 时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
- 对于迭代式数据处理性能比较差
因此出现了很多相关的技术对其中的局限进行改进。
Apache Pig
Apache Pig也是Hadoop框架中的一部分,Pig提供类SQL语言(Pig Latin)通过MapReduce来处理大规模半结构化数据。而Pig Latin是更高级的过程语言,通过将MapReduce中的设计模式抽象为操作,如Filter,GroupBy,Join,OrderBy,由这些操作组成数据处理流程。例如如下程序:
visits = load ‘/data/visits’ as (user, url, time);
gVisits = group visits by url;
visitCounts = foreach gVisits generate url, count(visits);
urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);
visitCounts = join visitCounts by url, urlInfo by url;
gCategories = group visitCounts by category;
topUrls = foreach gCategories generate top(visitCounts,10);
store topUrls into ‘/data/topUrls’;
描述了数据处理的整个过程。
而Pig Latin又是通过编译为MapReduce,在Hadoop集群上执行的。上述程序被编译成MapReduce时,会产生如下图所示的Map和Reduce: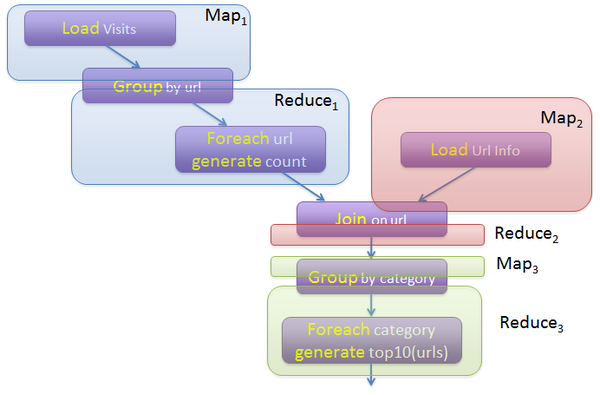
(图片来源:http://cs.nyu.edu/courses/Fall12/CSCI-GA.2434-001/sigmod08-pig-latin.ppt)
Apache Pig解决了MapReduce存在的大量手写代码,语义隐藏,提供操作种类少的问题。类似的项目还有Cascading,JAQL等。
Apache Tez
Apache Tez,Tez是HortonWorks的Stinger Initiative的的一部分。作为执行引擎,Tez也提供了有向无环图(DAG),DAG由顶点(Vertex)和边(Edge)组成,Edge是对数据的移动的抽象,提供了One-To-One,BroadCast,和Scatter-Gather三种类型,只有Scatter-Gather才需要进行Shuffle。
Tez的优化主要体现在: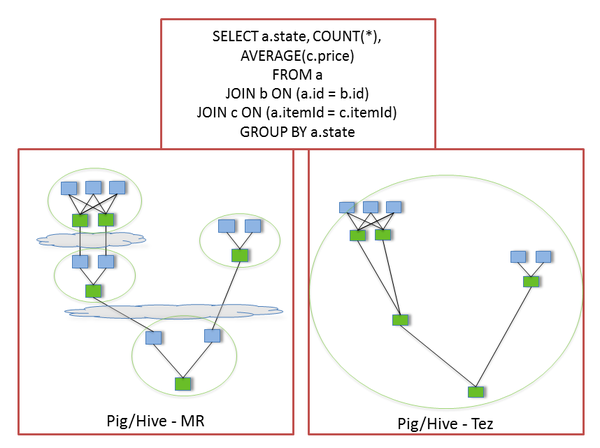
(图片来源:http://www.slideshare.net/hortonworks/apache-tez-accelerating-hadoop-query-processing)
- 去除了连续两个任务之间的写操作
- 去除了每个工作流中多余的Map阶段
通过提供DAG语义和操作,提供了整体的逻辑,通过减少不必要的操作,Tez提升了执行性能。
Apache Spark
Apache Spark也是一个大数据处理的引擎,主要特点是提供了一个集群的分布式内存抽象,以支持需要工作集的应用。
这个抽象就是RDD(Resilient Distributed Dataset),RDD就是一个不可变的带分区的记录集合。Spark提供了RDD上的两类操作,转换和动作。转换是用来定义一个新的RDD,包括map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues等,动作是返回一个结果,包括collect, reduce, count, save, lookupKey。
Spark支持故障恢复的方式也不同,提供两种方式,Linage,通过数据的血缘关系,再执行一遍前面的处理,Checkpoint,将数据集存储到持久存储中。
Spark的API非常简单易用,使用Spark,WordCount的示例如下所示:
val spark = new SparkContext(master, appName, [sparkHome], [jars])
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
其中的file是根据HDFS上的文件创建的RDD,后面的flatMap,map,reduceByKe都创建出一个新的RDD,一个简短的程序就能够执行很多个转换和动作。在Spark中,所有RDD的转换都是是惰性求值的。Spark的任务是由相互依赖的多个RDD组成的有向无环图,每个RDD又包含多个分区,当在RDD上执行动作时,Spark才对任务进行调度。
Spark对于有向无环图对任务进行调度,确定阶段,分区,流水线,任务和缓存,进行优化,并在Spark集群上运行任务。RDD之间的依赖分为宽依赖(依赖多个分区)和窄依赖(只依赖一个分区),在确定阶段时,需要根据宽依赖划分阶段。根据分区划分任务。
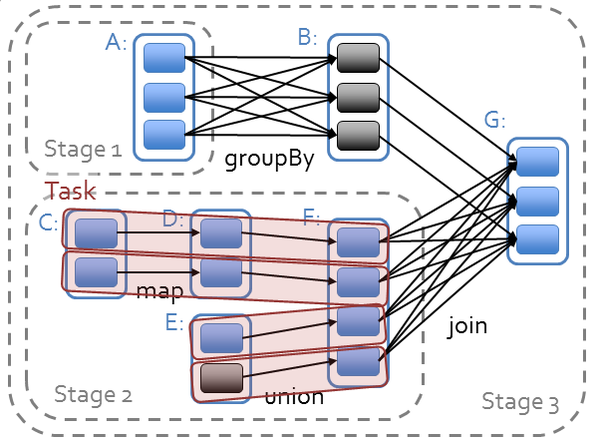 (图片来源:https://databricks-training.s3.amazonaws.com/slides/advanced-spark-training.pdf)
(图片来源:https://databricks-training.s3.amazonaws.com/slides/advanced-spark-training.pdf)
Spark为迭代式数据处理提供更好的支持。每次迭代的数据可以保存在内存中,而不是写入文件。
Spark的性能相比Hadoop有很大提升,2014年1月,Spark完成了一个Daytona Gray类别的Sort Benchmark测试,排序完全是在磁盘上进行的,与Hadoop之前的测试的对比结果如表格所示: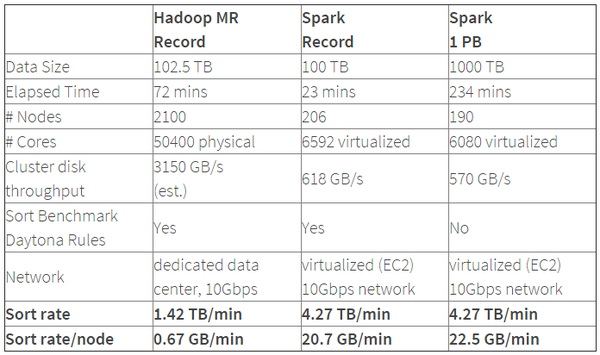 (表格来源: Spark officially sets a new record in large-scale sorting)
(表格来源: Spark officially sets a new record in large-scale sorting)
从表格中可以看出排序100TB的数据(1万亿条数据),Spark只用了Hadoop所用1/10的计算资源,耗时只有Hadoop的1/3。
Spakr的优势不仅体现在性能提升上的,Spark框架为批处理(Spark Core),交互式(Spark SQL),流式(Spark Streaming),机器学习(MLlib),图计算(GraphX)提供一个统一的平台,这相对于使用Hadoop有很大优势。
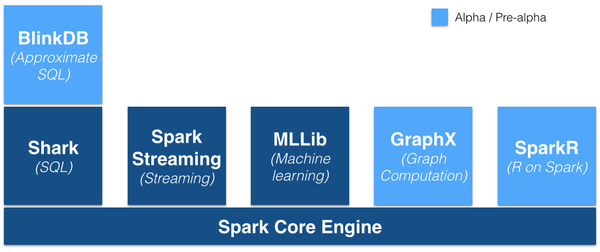 (图片来源:https://gigaom.com/2014/06/28/4-reasons-why-spark-could-jolt-hadoop-into-hyperdrive/)
(图片来源:https://gigaom.com/2014/06/28/4-reasons-why-spark-could-jolt-hadoop-into-hyperdrive/)
那么Spark解决了Hadoop的哪些问题呢?
- 抽象层次低,需要手工编写代码来完成,使用上难以上手。
- =>基于RDD的抽象,很多代码已经在RDD转换和动作中实现。
- 只提供两个操作,Map和Reduce,表达力欠缺。
- =>提供很多转换和动作,如Join,GroupBy这种常用的操作
- 一个Job只有Map和Reduce两个阶段,复杂的计算需要大量的Job完成。
- =>逻辑上的多个RDD的转换,在调度式可以生成多个阶段。
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- =>在Scala中,通过匿名函数和高阶函数,RDD的转换支持流式API,可以提供处理逻辑的整体视图。
- 中间结果也放在文件系统中
- =>中间结果放在内存中。
- ReduceTask需要等待所有MapTask都完成后才可以开始
- =>待定
- 时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
- =>通过将流拆成小的batch提供Discretized Stream处理流数据。
- 对于迭代式数据处理性能比较差
- =>通过在内存中缓存数据,提高迭代式计算的性能。
hadoop vs spark的更多相关文章
- Ubuntu14.04或16.04下Hadoop及Spark的开发配置
对于Hadoop和Spark的开发,最常用的还是Eclipse以及Intellij IDEA. 其中,Eclipse是免费开源的,基于Eclipse集成更多框架配置的还有MyEclipse.Intel ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- Hadoop与Spark比较
先看这篇文章:http://www.huochai.mobi/p/d/3967708/?share_tid=86bc0ba46c64&fmid=0 直接比较Hadoop和Spark有难度,因为 ...
- 2分钟读懂Hadoop和Spark的异同
谈到大数据框架,现在最火的就是Hadoop和Spark,但我们往往对它们的理解只是提留在字面上,并没有对它们进行深入的思考,倒底现在业界都在使用哪种技术?二者间究竟有哪些异同?它们各自解决了哪些问题? ...
- 在MacOs上配置Hadoop和Spark环境
在MacOs上配置hadoop和spark环境 Setting up Hadoop with Spark on MacOs Instructions 准备环境 如果没有brew,先google怎样安装 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- bigdata之hadoop and spark
目前正在学习Hadoop和spark之类的东西,一个月把Hadoop的基础东西过了一遍,但是感觉好动都没跟上老师的课程,哪位前辈了解这方面的东西希望给指点迷津.接下来我们还要学习spark和nosql ...
- PageRank在Hadoop和spark下的实现以及对比
关于PageRank的地位,不必多说. 主要思想:对于每个网页,用户都有可能点击网页上的某个链接,例如 A:B,C,D B:A,D C:AD:B,C 由这个我们可以得到网页的转移矩阵 A ...
- 安装Hadoop及Spark(Ubuntu 16.04)
安装Hadoop及Spark(Ubuntu 16.04) 安装JDK 下载jdk(以jdk-8u91-linux-x64.tar.gz为例) 新建文件夹 sudo mkdir /usr/lib/jvm ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
随机推荐
- flappy pig小游戏源码分析(3)——解剖util
这一节我们继续高歌猛进,如果对源码中有无论无何都理解不通的问题,欢迎和我交流,让我也学习一下,我的qq是372402487. 还是按照惯例看看我们的目录结构. 我们在前两节中已经分析了game.js, ...
- 从代码都发布遇到的问题总结(C#调用非托管dll文件,部署项目) 转
http://www.cnblogs.com/Purple_Xiapei/archive/2012/06/30/2570928.html
- eclipse下使用tomcat启动maven项目
最近学习使用maven,建立了一个maven项目使用eclipse下tomcat启动时报错: 严重: ContainerBase.addChild: start: org.apache.catalin ...
- Activity的lanuchmode
假设: 假设栈有A-B-C-D,四个activity.其中D Activity在栈顶 standard: 此时跳转到D Activity,跳转后栈的情况是A-B-C-D-D singleTop: 此时 ...
- 安森美电量计采用内部电阻跟踪电流--电压HG-CVR
http://www.dianyuan.com/article/34608.html LC709203F应用:用于便携式设备单节锂电池的智能电量计http://files.cnblogs.com/fi ...
- 起底多线程同步锁(iOS)
iOS/MacOS为多线程.共享内存(变量)提供了多种的同步解决方案(即同步锁),对于这些方案的比较,大都讨论了锁的用法以及锁操作的开销,然后就开销表现排个序.春哥以为,最优方案的选用还是看应用场景, ...
- Resharp非常实用的快捷键
Alt+Home 定位到父类.父接口 Alt + End 定位到子类 Ctrl+T 快速在整个解决方案下搜索 类型.方法.文件夹 Alt+Ctrl+Spance 给出提示框 Shift+F ...
- UVa 10465 Homer Simpson (枚举)
10465 - Homer Simpson Time limit: 3.000 seconds http://uva.onlinejudge.org/index.php?option=com_onli ...
- Swift基本语法及与OC比较之二
//MARK:-----------------控制流----------------- //MARK: 1.for - in 循环 ,不用声明Value类型 //for value in 1...6 ...
- Activity的生命周期,BACK键和HOME键生命周期
Activity的生命周期模型在Google提供的官方文档上有比较详细的一个图示 public class HelloActivity extends Activity { public static ...