ELK之Elasticsearch、logstash部署及配置
ElasticSearch是一个搜索引擎,用来搜索、分析、存储日志;
Logstash用来采集日志,把日志解析为json格式交给ElasticSearch;
Kibana是一个数据可视化组件,把处理后的结果通过web界面展示;
Beats在这里是一个轻量级日志采集器,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高.相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计.
1.准备环境以及安装包
hostname:linux-elk1 ip:10.0.0.22
hostname:linux-elk2 ip:10.0.0.33
# 两台机器保持hosts一致,以及关闭防火墙和selinux
cat /etc/hosts
10.0.0.22 linux-elk1
10.0.0.33 linux-elk2
systemctl disable firewalld.service
systemctl disable NetworkManager
echo "*/5 * * * * /usr/sbin/ntpdate time1.aliyun.com &>/dev/null" >>/var/spool/cron/root
systemctl restart crond.service cd /usr/local/src
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.4.0.rpm
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.4.0-x86_64.rpm
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.4.0.rpm ll
total 342448
-rw-r--r-- 1 root root 33211227 May 15 2018 elasticsearch-5.4.0.rpm
-rw-r--r-- 1 root root 167733100 Feb 3 12:13 jdk-8u121-linux-x64.rpm
-rw-r--r-- 1 root root 56266315 May 15 2018 kibana-5.4.0-x86_64.rpm
-rw-r--r-- 1 root root 93448667 May 15 2018 logstash-5.4.0.rpm
# 安装配置elasticsearch
yum -y install jdk-8u121-linux-x64.rpm elasticsearch-5.4.0.rpm
grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster
node.name: elk-node1
path.data: /data/elkdata
path.logs: /data/logs
bootstrap.memory_lock: true
network.host: 10.0.0.22
http.port: 9200
discovery.zen.ping.unicast.hosts: ["10.0.0.22", "10.0.0.33"] mkdir /data/{elkdata,logs}
chown -R elasticsearch.elasticsearch /data # 打开启动脚本中的某行/usr/lib/systemd/system/elasticsearch.service
LimitMEMLOCK=infinity
# 修改最大、最小内存为3g
grep -vE "^$|#" /etc/elasticsearch/jvm.options
-Xms3g
-Xmx3g
...
systemctl restart elasticsearch.service
tail /data/logs/elk-cluster.log # 最后几行有个started时,说明服务已经启动
访问http://10.0.0.22:9200/,出现es信息,说明服务正常
在linux上验证es服务正常的命令:curl http://10.0.0.22:9200/_cluster/health?pretty=true
2.安装es插件head
wget https://nodejs.org/dist/v8.10.0/node-v8.10.0-linux-x64.tar.xz
tar xf node-v8.10.0-linux-x64.tar.xz
mv node-v8.10.0-linux-x64 /usr/local/node
vim /etc/profile
export NODE_HOME=/usr/local/node
export PATH=$PATH:$NODE_HOME/bin
source /etc/profile
which node
/usr/local/node/bin/node
which npm
/usr/local/node/bin/npm npm install -g cnpm --registry=https://registry.npm.taobao.org # 生成了一个cnpm
/usr/local/node/bin/cnpm -> /usr/local/node/lib/node_modules/cnpm/bin/cnpm npm install -g grunt-cli --registry=https://registry.npm.taobao.org # 生成了一个grunt
/usr/local/node/bin/grunt -> /usr/local/node/lib/node_modules/grunt-cli/bin/grunt wget https://github.com/mobz/elasticsearch-head/archive/master.zip
unzip master.zip
cd elasticsearch-head-master/
vim Gruntfile.js
90 connect: {
91 server: {
92 options: {
93 hostname: '10.0.0.22',
94 port: 9100,
95 base: '.',
96 keepalive: true
97 }
98 }
99 } vim _site/app.js
4360行将"http://localhost:9200"改为"http://10.0.0.22:9200";
cnpm install
grunt --version
vim /etc/elasticsearch/elasticsearch.yml # 增加如下两行
http.cors.enabled: true
http.cors.allow-origin: "*" systemctl restart elasticsearch
systemctl enable elasticsearch
grunt server &
在elasticsearch 2.x以前的版本可以通过:
/usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head来安装head插件;
在elasticsearch 5.x以上版本需要通过npm进行安装

docker方式启动插件(前提是装好了es)
yum -y install docker
systemctl start docker && systemctl enable docker
docker run -p 9100:9100 mobz/elasticsearch-head:5
报错:Fatal error: Unable to find local grunt.
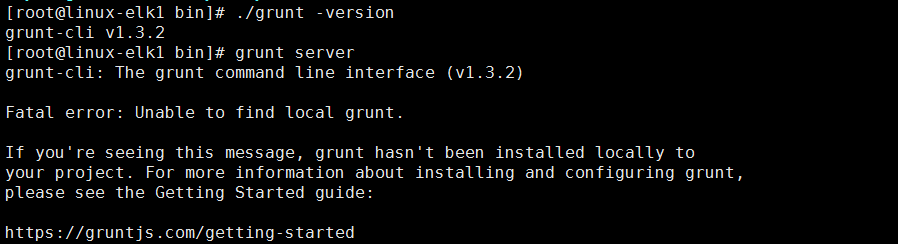
网上大多解决方法是:npm install grunt --save-dev,这是没有装grunt的时候的解决办法,在上面的步骤中已经安装了grunt,只是启动时没有在项目目录中,到项目目录执行该命令grunt server &即可.
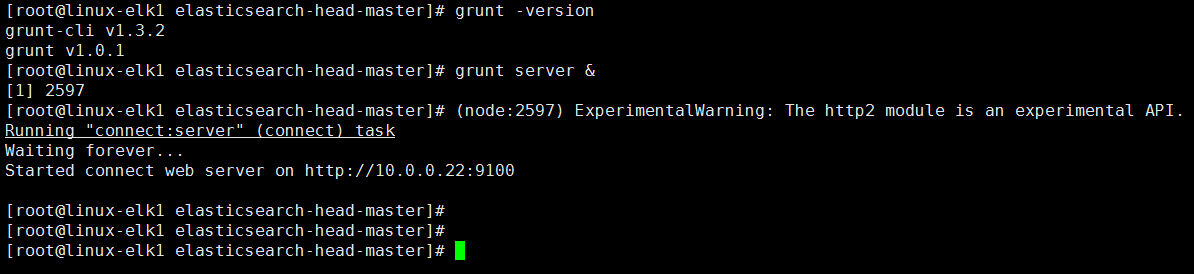
3.logstash部署及基本语法
cd /usr/local/src
yum -y install logstash-5.4.0.rpm
# 使用rubydebug方式前台输出展示以及测试
/usr/share/logstash/bin/logstash -e 'input { stdin {} } output { stdout { codec => rubydebug} }'
The stdin plugin is now waiting for input:
00:37:04.711 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
hello
{
"@timestamp" => 2019-02-03T16:43:48.149Z,
"@version" => "1",
"host" => "linux-elk1",
"message" => "hello"
} # 测试输出到文件
/usr/share/logstash/bin/logstash -e 'input { stdin {} } output { file { path => "/tmp/test-%{+YYYY.MM.dd}.log"} }'
# 开启gzip压缩输出
/usr/share/logstash/bin/logstash -e 'input { stdin {} } output{ file { path => "/tmp/test-%{+YYYY.MM.dd}.log.tar.gz" gzip => true } }'
# 测试输出到elasticsearch
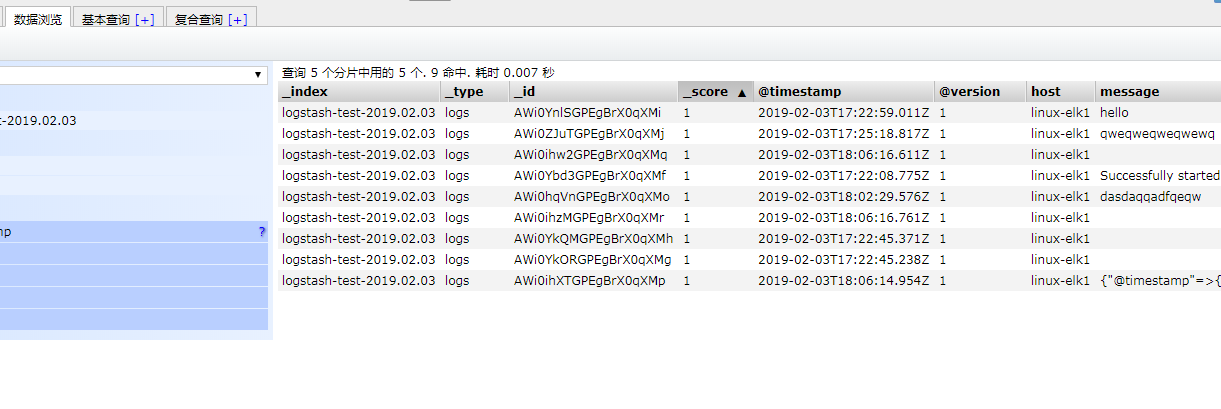
/usr/share/logstash/bin/logstash -e 'input { stdin {} } output { elasticsearch { hosts => ["10.0.0.22:9200"] index => "logstash-test-%{+YYYY.MM.dd}" } }' systemctl enable logstash
systemctl restart logstash
在删除数据时,在该界面删除,切勿在服务器目录上删除,因为集群节点上都有这样的数据,删除某一个,可能会导致elasticsearch无法启动.
Elasticsearch环境准备-参考博客:http://blog.51cto.com/jinlong/2054787
logstash部署及基本语法-参考博客:http://blog.51cto.com/jinlong/2055024
ELK之Elasticsearch、logstash部署及配置的更多相关文章
- ELK(ElasticSearch+Logstash+Kibana)配置中的一些坑基于7.6版本
三个组件都是采用Docker镜像安装,过程简单不做赘述,直接使用Docker官方镜像运行容器即可,注意三个组件版本必须一致. 运行容器时最好将三个组件的核心配置文件与主机做映射,方便直接在主机修改不用 ...
- ELK 架构之 Logstash 和 Filebeat 配置使用(采集过滤)
相关文章: ELK 架构之 Elasticsearch 和 Kibana 安装配置 ELK 架构之 Logstash 和 Filebeat 安装配置 ELK 使用步骤:Spring Boot 日志输出 ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
- ELK( ElasticSearch+ Logstash+ Kibana)分布式日志系统部署文档
开始在公司实施的小应用,慢慢完善之~~~~~~~~文档制作 了好作运维同事之间的前期普及.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 软件下载地址: https://www.e ...
- Centos7下使用ELK(Elasticsearch + Logstash + Kibana)搭建日志集中分析平台
日志监控和分析在保障业务稳定运行时,起到了很重要的作用,不过一般情况下日志都分散在各个生产服务器,且开发人员无法登陆生产服务器,这时候就需要一个集中式的日志收集装置,对日志中的关键字进行监控,触发异常 ...
- ELK篇---------elasticsearch集群安装配置
说明: 本次ELK的基础配置如下: 虚拟机:vmware 11 系统:centos7.2 两台 IP:172.16.1.15/16 一.下载es wget https://download.elas ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
- ELK6.0部署:Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 1.ELK简介 ELK是Elasticsearch+Logstash+Kibana的简称 ElasticSearch是一个基于Lucene的分布式全文搜索引擎,提供 RESTful API进 ...
- 【Big Data - ELK】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticSearch,一款基于Apache Lucene的开源分布式搜索引擎)中便于查找和分析,在研究 ...
随机推荐
- nonrepetitive DNA|repetitive DNA|moderaly repetitive DNA|highly repetitive DNA|selfish gene|junk DNA
5.5 真核生物基因组包含非重复DNA序列和重复DNA序列 依据重复序列的频数,可将真核生物DNA做如下分类: 1次即非重复DNA(nonrepetitive DNA,相应的也会更长,随着基因组扩大( ...
- jpeg和jpg的区别是什么
JPG是JPEG的简写,jpg是后缀名,jpeg既可作为后缀名,又能代表文件格式:JPG——JPEG文件格式. 我们在系统自带的画图程序里保存文件,在保存类型:JPEG(*.JPG,*.JPEG,*. ...
- Apache Commons Configuration的应用
Apache Commons Configuration的应用 Commons Configuration是一个java应用程序的配置管理工具.可以从properties或者xml文件中加载软件的配置 ...
- Linux rm删除文件未释放空间问题分析
问题描述: 在自己的虚拟机上做实验时出现空间不足情况,检查发现之前的kafka集群测试日志在几天写了 25G,于是进入 /data/kafka01/logs 目录执行 “rm -rf *” 删除所有测 ...
- Ubuntu 18.04修改默认源
安装Ubuntu 18.04后,使用国外源太慢了,修改为国内源会快很多. 修改阿里源为Ubuntu 18.04默认的源 备份/etc/apt/sources.list #备份 cp /etc/apt/ ...
- perl学习之裸字
use strict包含3个部分.其中之一(use strict "subs")负责禁止乱用的裸字. 这是什么意思呢? 如果没有这个限制,下面的代码也可以打印出"hell ...
- 安装tesserocr的步骤和报错RuntimeError: Failed to init API, possibly an invalid tessdata path解决办法
1,首先下载合适的tesseract-ocr的版本 2,然后安装到这一步注意要勾选这一项来安装OCR识别支持的语言包,这样OCR就可以识别多国语言,然后就可以一直点击下一步完成安装. 3,安装tess ...
- 剑指Offer(书):链表的倒数第K个节点
题目:输入一个链表,输出该链表中倒数第k个结点. 分析:要注意三点:链表为空:链表个数小于k:k的值<=0; public ListNode FindKthToTail(ListNode hea ...
- skkyk:题解 洛谷P3865 【【模板】ST表】
我不会ST表 智推推到这个题 发现标签中居然有线段树..? 于是贸然来了一发线段树 众所周知,线段树的查询是log(n)的 题目中"请注意最大数据时限只有0.8s,数据强度不低,请务必保证你 ...
- loj2274 「JXOI2017」加法
二分一下,然后从左到右扫描,扫到左端点就把区间 push 到堆里. 每次有点不符合二分的值时,就贪心地选择右端点最远的 add. #include <algorithm> #include ...