AbstractRoutingDataSource动态选择数据源
当我们项目变大后,有时候需要多个数据源,接下来我们讲一种能等动态切换数据源的例子。
盗一下图:
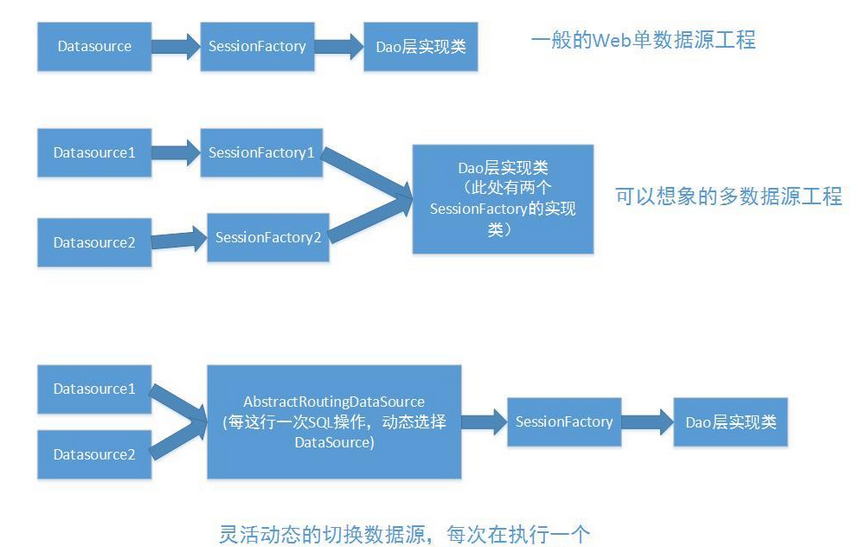
- 单数据源的场景(一般的Web项目工程这样配置进行处理,就已经比较能够满足我们的业务需求)
- 多数据源多SessionFactory这样的场景,估计作为刚刚开始想象想处理在使用框架的情况下处理业务,配置多个SessionFactory,然后在Dao层中对于特定的请求,通过特定的SessionFactory即可处理实现这样的业务需求
- 使用AbstractRoutingDataSource 的实现类,进行灵活的切换,可以通过AOP或者手动编程设置当前的DataSource,不用修改我们编写的对于继承HibernateSupportDao的实现类的修改,这样的编写方式比较好
我们这次讲的是第三种,第二种也可以实现,相对来说也比较简单。
第一步:写AbstractRoutingDataSource的实现类
package com.inspur.tax.common.utils; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource; /**
* @ClassName ThreadLocalRountingDataSource
* @Author caozx
* @Description //TODO $
* @Date $ $
**/
public class ThreadLocalRountingDataSource extends AbstractRoutingDataSource { @Override
protected Object determineCurrentLookupKey() {
// 获取数据源
return DataSourceTypeManager.getDataSource();
}
}
第二步:设置动态选择的Datasource,这里用到了ThreadLocal。
package com.inspur.tax.common.utils; /**
* @ClassName DataSourceTypeManager
* @Author caozx
* @Description //TODO $
* @Date $ $
**/
public class DataSourceTypeManager {
/**
* 注意:数据源标识保存在线程变量中,避免多线程操作数据源时互相干扰
*/
private static final ThreadLocal<String> THREAD_DATA_SOURCE = new ThreadLocal<String>(); public static String getDataSource() {
return THREAD_DATA_SOURCE.get();
} public static void setDataSource(String dataSource) {
THREAD_DATA_SOURCE.set(dataSource);
} public static void clear() {
THREAD_DATA_SOURCE.remove();
}
}
第三步:在Spring核心容器中配置配置数据源
<?xml version="1.0" encoding="UTF-8"?>
<!-- wbw 2016.8.22 -->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc-3.2.xsd"> <bean id="dataSource_mysql" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close"> <property name="url" value="${dataSource.mysql.url}" />
<property name="username" value="${dataSource.mysql.username}" />
<property name="password" value="${dataSource.mysql.password}" /> <!-- 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j
防御sql注入的filter:wall -->
<property name="filters" value="stat" /> <!-- 最大连接池数量(缺省值:8) -->
<property name="maxActive" value="20" />
<!-- 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时(缺省值:0) -->
<property name="initialSize" value="1" />
<!-- 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 -->
<property name="maxWait" value="60000" />
<!-- 最小连接池数量 -->
<property name="minIdle" value="1" /> <!-- 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接
2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 (缺省值:1分钟) -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 连接保持空闲而不被驱逐的最长时间(缺省值:30分钟) -->
<property name="minEvictableIdleTimeMillis" value="300000" /> <!-- 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。(缺省值:false) -->
<property name="testWhileIdle" value="true" />
<!-- 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。(缺省值:true) -->
<property name="testOnBorrow" value="false" />
<!-- 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能(缺省值:false) -->
<property name="testOnReturn" value="false" /> <!-- 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 -->
<property name="validationQuery" value="SELECT 1" /> <!-- 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。(缺省值:fasle) -->
<property name="poolPreparedStatements" value="false" />
<!-- 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100(缺省值:-1) -->
<property name="maxOpenPreparedStatements" value="-1" /> <!-- 在上面的配置中,通常你需要配置url、username、password,maxActive这三项 -->
</bean> <bean id="dataSource_oracle" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close"> <property name="url" value="${dataSource.oracle.url}" />
<property name="username" value="${dataSource.oracle.username}" />
<property name="password" value="${dataSource.oracle.password}" /> <!-- 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j
防御sql注入的filter:wall -->
<property name="filters" value="stat" /> <!-- 最大连接池数量(缺省值:8) -->
<property name="maxActive" value="20" />
<!-- 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时(缺省值:0) -->
<property name="initialSize" value="1" />
<!-- 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 -->
<property name="maxWait" value="60000" />
<!-- 最小连接池数量 -->
<property name="minIdle" value="1" /> <!-- 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接
2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 (缺省值:1分钟) -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 连接保持空闲而不被驱逐的最长时间(缺省值:30分钟) -->
<property name="minEvictableIdleTimeMillis" value="300000" /> <!-- 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。(缺省值:false) -->
<property name="testWhileIdle" value="true" />
<!-- 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。(缺省值:true) -->
<property name="testOnBorrow" value="false" />
<!-- 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能(缺省值:false) -->
<property name="testOnReturn" value="false" /> <!-- 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 -->
<property name="validationQuery" value="SELECT 1 FROM DUAL" /> <!-- 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。(缺省值:fasle) -->
<property name="poolPreparedStatements" value="true" />
<!-- 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100(缺省值:-1) -->
<property name="maxOpenPreparedStatements" value="100" /> <!-- 在上面的配置中,通常你需要配置url、username、password,maxActive这三项 -->
</bean> <bean id="dataSource" class="com.inspur.tax.common.utils.ThreadLocalRountingDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<entry key="master" value-ref="dataSource_oracle"/>
<entry key="slave" value-ref="dataSource_mysql"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="dataSource_oracle"></property>
</bean>
</beans>
第四步:直接在调用dao层之前使用:
@Override
public Map<String, String> getYyssqk(String qxswjguandm) {
DataSourceTypeManager.setDataSource("slave");
System.out.println(DataSourceTypeManager.getDataSource());
Map<String,Object> params = new HashMap<String, Object>();
params.put("qxswjguandm", qxswjguandm);
Map<String, String> qnMap = sskjjMapper.getYyssqk(params);
params.remove("tb");
Map<String, String> bnMap = sskjjMapper.getYyssqk(params);
DecimalFormat df = new DecimalFormat(",##0.00");
if(Double.parseDouble(qnMap.get("LJ_YYSR"))==0){
注意代码中的红色部分,这就切换到了slave所对应的数据源。注意在代码最后进行清除,重新设置到默认的数据源。
DataSourceTypeManager.clear()
进行到这里就实现了动态选择数据源,是不是很简单,有没有觉得有点问题呢?没错,每次选择都得执行代码DataSourceTypeManager.setDataSource("slave"),我们可以用aop的注解的方式哟,直接在方法上添加注解(对于方法体内来回切换的那种就老老实实手写吧)。
第五步:写注解
package com.inspur.tax.common.utils; import java.lang.annotation.*; @Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DynamicSwitchDataSource {
String value() default "";
}
第六步:写切面类,前置通知和后置通知
package com.inspur.tax.common.utils; import java.lang.reflect.Method; import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* @ClassName DataSourceAspect
* @Author caozx
* @Description //TODO $
* @Date $ $
**/
@Aspect
public class DataSourceAspect { private final static Logger log = LoggerFactory.getLogger(DataSourceAspect.class); @Pointcut("@annotation(com.inspur.tax.common.utils.DynamicSwitchDataSource)")
private void pointCut(){} @Before("pointCut()")
public void beforeMethod(JoinPoint jp){
try {
//获取抽象方法(接口的或抽象类的方法)
Method method = ((MethodSignature) jp.getSignature()).getMethod(); //这个是接口方法的注解,没有所以为null
//DynamicSwitchDataSource annotationClass = method.getAnnotation(DynamicSwitchDataSource.class); //获取当前类的对象
Class<?> clazz = jp.getTarget().getClass();
//获取实现类的方法
method = clazz.getMethod(method.getName(), method.getParameterTypes());
//获取方法上的注解
DynamicSwitchDataSource annotationClass = method.getAnnotation(DynamicSwitchDataSource.class);
if (annotationClass == null) {
//获取类上面的注解
annotationClass = jp.getTarget().getClass().getAnnotation(DynamicSwitchDataSource.class);
if (annotationClass == null) return;
}
//获取注解上的数据源的值的信息
String dataSourceKey = annotationClass.value();
if (dataSourceKey != null) { //给当前的执行SQL的操作设置特殊的数据源的信息
DataSourceTypeManager.setDataSource(dataSourceKey);
}
log.info("AOP动态切换数据源");
}catch (Exception e){
log.info(e.getMessage());
}
} @After("pointCut()")
public void after(JoinPoint jp){
DataSourceTypeManager.clear();
log.info("后置通知");
}
}
第七步:调用
@Override
@DynamicSwitchDataSource("master")
public Map<String, String> getYyssqk(String qxswjguandm) {
System.out.println(DataSourceTypeManager.getDataSource());
Map<String,Object> params = new HashMap<String, Object>();
params.put("qxswjguandm", qxswjguandm);
AbstractRoutingDataSource动态选择数据源的更多相关文章
- 【开发笔记】- AbstractRoutingDataSource动态数据源切换,AOP实现动态数据源切换
AbstractRoutingDataSource动态数据源切换 上周末,室友通宵达旦的敲代码处理他的多数据源的问题,搞的非常的紧张,也和我聊了聊天,大概的了解了他的业务的需求.一般的情况下我们都是使 ...
- AbstractRoutingDataSource动态数据源切换,AOP实现动态数据源切换
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/u012881904/article/de ...
- AbstractRoutingDataSource动态数据源切换
操作数据一般都是在DAO层进行处理,可以选择直接使用JDBC进行编程(http://blog.csdn.net/yanzi1225627/article/details/26950615/) 或者是使 ...
- springboot动态多数据源
参考文章:https://www.cnblogs.com/hehehaha/p/6147096.html 前言 目标是springboot工程支持多个MySQL数据源,在代码层面上,同一个SQL(Ma ...
- 基于AbstractRoutingDataSource实现动态切换数据源
基于AbstractRoutingDataSource实现动态切换数据源 /** * DataSource注解接口 */ @Target({ElementType.TYPE, ElementTyp ...
- Spring3 整合MyBatis3 配置多数据源 动态选择SqlSessionFactory
一.摘要 上两篇文章分别介绍了Spring3.3 整合 Hibernate3.MyBatis3.2 配置多数据源/动态切换数据源 方法 和 Spring3 整合Hibernate3.5 动态切换Ses ...
- Spring3.3 整合 Hibernate3、MyBatis3.2 配置多数据源/动态切换数据源 方法
一.开篇 这里整合分别采用了Hibernate和MyBatis两大持久层框架,Hibernate主要完成增删改功能和一些单一的对象查询功能,MyBatis主要负责查询功能.所以在出来数据库方言的时候基 ...
- hibernate动态切换数据源
起因: 公司的当前产品,主要是两个项目集成的,一个是java项目,还有一个是php项目,两个项目用的是不同的数据源,但都是mysql数据库,因为java这边的开发工作已经基本完成了,而php那边任务还 ...
- spring 动态创建数据源
项目需求如下,公司对外提供服务,公司本身有个主库,另外公司会为每个新客户创建一个数据库,客户的数据库地址,用户名,密码,都保存在主数据库中.由于不断有新的客户加入,所以要求,项目根据主数据库中的信息, ...
随机推荐
- 【解题报告】洛谷 P2571 [SCOI2010]传送带
[解题报告]洛谷 P2571 [SCOI2010]传送带今天无聊,很久没有做过题目了,但是又不想做什么太难的题目,所以就用洛谷随机跳题,跳到了一道题目,感觉好像不是太难. [CSDN链接](https ...
- TFRecordReader "OutOfRangeError (see above for traceback): RandomShuffleQueue '_1_shuffle_batch/random_shuffle_queue' is closed and has insufficient elements (requested 1, current size 0)" 问题原因总结;
1. tf.decode_raw(features['image_raw'],tf.uint8) 解码时,数据类型有没有错?tf.float32 和tf.uint8有没有弄混??? 2. tf.tra ...
- js之字典操作
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 第九节:web爬虫之urllib(五)
第四个模块 robotparser: 主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以爬的,其实用的比较少.
- 【模板】51nod 1006 最长公共子序列Lcs
[题解] dp转移的时候记录一下,然后倒着推出答案即可. #include<cstdio> #include<cstring> #include<algorithm> ...
- 封装的一些常见的JS DOM操作和数据处理的函数.
//用 class 获取元素 function getElementsByClass(className,context) { context = context || document; if(do ...
- 最长上升子序列的回溯 ZOJ 2432
题目大意: 找一组最长上升公共子序列,并把任意一组满足的情况输出出来 最长公共上升子序列不清楚可以先看这篇文章 http://www.cnblogs.com/CSU3901130321/p/41826 ...
- MTK平台系统稳定性分析
目录 1:简介 2:怎么抓取和分析log 3:怎么确定问题点 简介 系统稳定性目前主要是解决系统死机重启. 分为两部分:Android /kernel Kernel 分析需要的文件和工具: Mtklo ...
- Sql语句中关于如何在like '%?%'中给?赋值
做模糊查询用户的时候,如果 String sql="select * from users where name like %?%"; String[] param={userna ...
- rest frame work纪念版代码
models.py from django.db import models from pygments.lexers import get_all_lexers from pygments.styl ...