PairRDD中算子combineByKey图解
1、combineByKey
combine 为结合意思。
作用: 将RDD[(K,V)] => RDD[(K,C)] 表示V的类型可以转成C两者可以不同类型。
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,numPartitions:Int ):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,partitioner:Partitioner,mapSideCombine:Boolean=true,serializer:Serializer= null):RDD[(K,C)]
第一个函数和第二个函数默认使用的是HashPartitioner、serialize为null。
这个算子还是比较复杂,解释下:
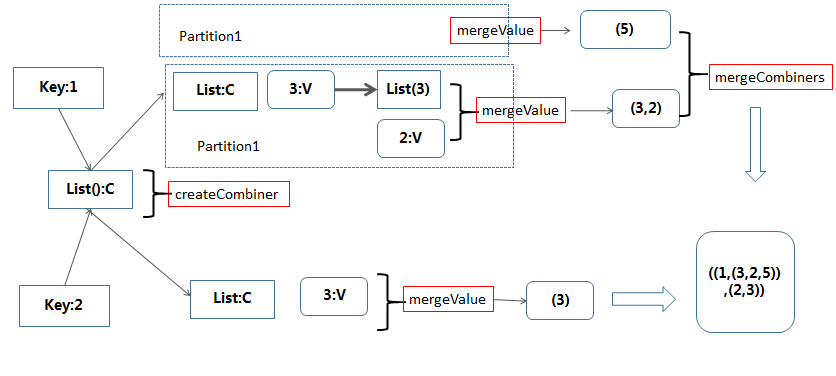
1)createCombiner:在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey第一次遇到值为k的Key(类型K),那么将对这个(k,v)调用 createCombiner函数,它的作用是将v转换为c(类型是C,聚合对象的类型,c作为局和对象的初始值)
2)mergeValue: 在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey不是第一次(或者第二次,第三次…)遇到值为k的Key(类型K),那么将对这个 (k,v)调用mergeValue函数,它的作用是将v累加到聚合对象(类型C)中,mergeValue的类型是(C,V)=>C,参数中的C遍历到此处的聚合对象,然后对v 进行聚合得到新的聚合对象值。
3)mergeCombiners:因为combineByKey是在分布式环境下执行,RDD的每个分区单独进行combineByKey操作,
最后需要对各个分区的结果进行最后的聚合,它的函数类型是(C,C)=>C,每个参数是分区聚合得到的聚合对象
例子:
scala> val data = sc.parallelize(List(("1","3"),("1","2"),("1","5"),("2","3")))
scala> val natPairRdd = data.combineByKey(List(_), (c: List[String], v: String) => v::c, (c1: List[String], c2: List[String]) => c1 ::: c2)
scala> natPairRdd.collect
res0: Array[(String, List[String])] = Array((1,List(3, 2, 5)), (2,List(3)))
PairRDD中算子combineByKey图解的更多相关文章
- PairRDD中算子aggregateByKey图解
PairRDD 有几个比较麻烦的算子,常理解了后面又忘记了,自己按照自己的理解记录好,以备查阅 1.aggregateByKey aggregate 是聚合意思,直观理解就是按照Key进行聚合. 转化 ...
- PairRDD中算子reduceByKey图解
reduceByKey 函数原型: def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) =& ...
- PairRDD中算子foldByKey图解
foldByKey 函数原型: def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] def foldByKey(zeroVal ...
- pairRDD中算子reduceByKeyLocally
原型: def reduceByKeyLocally(func: (V, V) => V): Map[K, V] 该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个 ...
- 带你学习MindSpore中算子使用方法
摘要:本文分享下MindSpore中算子的使用和遇到问题时的解决方法. 本文分享自华为云社区<[MindSpore易点通]算子使用问题与解决方法>,作者:chengxiaoli. 简介 算 ...
- 【Spark篇】---SparkStreaming中算子中OutPutOperator类算子
一.前述 SparkStreaming中的算子分为两类,一类是Transformation类算子,一类是OutPutOperator类算子. Transformation类算子updateStateB ...
- spark中的combineByKey函数的用法
一.函数的源码 /** * Simplified version of combineByKeyWithClassTag that hash-partitions the resulting RDD ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
- ES5和ES6中的继承 图解
Javascript中的继承一直是个比较麻烦的问题,prototype.constructor.__proto__在构造函数,实例和原型之间有的 复杂的关系,不仔细捋下很难记得牢固.ES6中又新增了c ...
随机推荐
- react 引入 json
1.对 json 里面的数据进行增删改查
- 开源 免费 java CMS - FreeCMS1.9 移动APP管理 网站配置
项目地址:http://www.freeteam.cn/ 网站配置 管理员能够在这里设置当前管理网站是否同意移动app訪问,是否默认移动APP网站.首页的布局,首页数据最多载入页数. 从左側管理菜单点 ...
- 山东省赛-博弈-Game
id=1582" target="_blank" style="font-size:18px">点击打开题目链接 非常明显的一道博弈题目,可 ...
- maven 找不到或无法加载主类
maven 找不到或无法加载主类 CreateTime--2018年4月19日22:58:14 Author:Marydon 1.情景还原: 在maven管理的web项目中,单独运行Java类报错 ...
- html+css+js实现网页拼图游戏
代码地址如下:http://www.demodashi.com/demo/14449.html 项目描述 使用 html+js+css 实现一个网页拼图游戏,可支持简单,中等,困难三种难度. 演示效果 ...
- 转载:在PHP语言中使用JSON和将json还原成数组
一.json_encode() 1 2 3 4 <?php $arr = array ('a'=>1,'b'=>2,'c'=>3,'d'=>4,'e'=>5); e ...
- IE和火狐兼容常见问题
文章转自http://www.cnblogs.com/asqq/archive/2013/03/09/3194994.html 1,document.form.item/document.ID IE中 ...
- ssh之为什么要放弃ssh?
本文经转载, 源出处不详.https://www.cnblogs.com/hackxiyu/p/6849085.html 最近听一些朋友说,招聘面试的很多人简历都差不多,大部分人的简历上面都写了熟悉s ...
- 一道SQL题
原题:大池子博客 给定一个access_time表,它记录了用户每个月访问网站的次数,包括三个域:用户.时间.次数.注意表中可能包含用户在1月份的多条记录. 要求查询用户.月份.月累计.总共累计四项的 ...
- SPFA 上手题 数 枚:
1, HDU 1548 A strange lift :http://acm.hdu.edu.cn/showproblem.php?pid=1548 这道题可以灰常巧妙的转换为一道最短路题目,对第i层 ...