PairRDD中算子aggregateByKey图解
PairRDD 有几个比较麻烦的算子,常理解了后面又忘记了,自己按照自己的理解记录好,以备查阅
1、aggregateByKey
aggregate 是聚合意思,直观理解就是按照Key进行聚合。
转化: RDD[(K,V)] ==> RDD[(K,U)]
可以看出是返回值的类型不需要和原来的RDD的Value类型一致的。
在聚合过程中提供一个中立的初始值。
原型:
def aggregateByKey[U:ClassTag](zeroValue:U, partitioner:Partitioner)(seqOp:(U,V) =>U, comOp:(U,U) =>U):RDD[(K,U)]
def aggregateByKey[U:ClassTag](zeroValue:U, numPartitions:Int)(seqOp:(U,V) =>U, comOp:(U,U) =>U):RDD[(K,U)]
def aggregateByKey[U:ClassTag](zeroValue:U)(seqOp:(U,V) =>U, comOp:(U,U) =>U):RDD[(K,U)]
1、 第一个可以自己定义分区Partitioner; 2、第二个设置了分区数,最终定义了和HashPartitioner; 3、第三个会判断当前RDD是否定义分区函数,如果定义了则用当前的分区函数,没定义,则使用HashPartitioner
例子:
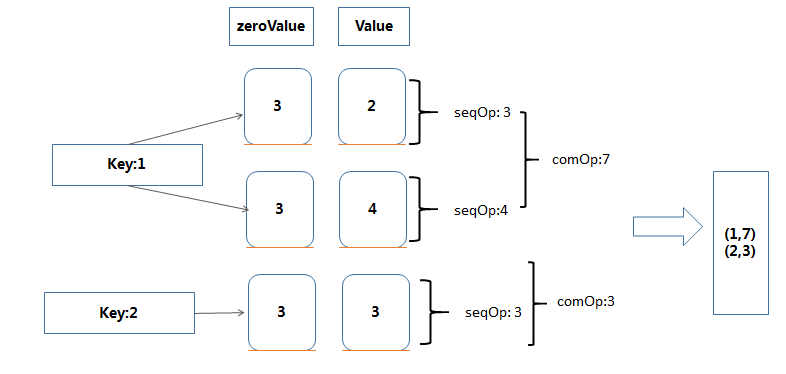
>val data = sc.parallelize(List((1,2),(1,4),(2,3)))
> data.aggregateByKey(3)((x,y)=>math.max(x,y) ,(z,m)=>z+m)
>Array((1,7)(2,3))
PairRDD中算子aggregateByKey图解的更多相关文章
- PairRDD中算子combineByKey图解
1.combineByKey combine 为结合意思. 作用: 将RDD[(K,V)] => RDD[(K,C)] 表示V的类型可以转成C两者可以不同类型. def combineBy ...
- PairRDD中算子reduceByKey图解
reduceByKey 函数原型: def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) =& ...
- PairRDD中算子foldByKey图解
foldByKey 函数原型: def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] def foldByKey(zeroVal ...
- pairRDD中算子reduceByKeyLocally
原型: def reduceByKeyLocally(func: (V, V) => V): Map[K, V] 该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个 ...
- spark-聚合算子aggregatebykey
spark-聚合算子aggregatebykey Aggregate the values of each key, using given combine functions and a neutr ...
- 带你学习MindSpore中算子使用方法
摘要:本文分享下MindSpore中算子的使用和遇到问题时的解决方法. 本文分享自华为云社区<[MindSpore易点通]算子使用问题与解决方法>,作者:chengxiaoli. 简介 算 ...
- 对spark算子aggregateByKey的理解
案例 aggregateByKey算子其实相当于是针对不同“key”数据做一个map+reduce规约的操作. 举一个简单的在生产环境中的一段代码 有一些整理好的日志字段,经过处理得到了RDD类型为( ...
- 【Spark篇】---SparkStreaming中算子中OutPutOperator类算子
一.前述 SparkStreaming中的算子分为两类,一类是Transformation类算子,一类是OutPutOperator类算子. Transformation类算子updateStateB ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
随机推荐
- updatepanel 和 visibility 有一定冲突
如果出现异常可以将 visibility换成 display
- 在启动vsftpd,有时会报错
在启动vsftpd,有时会报错:C:>ftp 192.168.0.101Connected to 192.168.0.101.220 (vsFTPd 2.0.5)User (192.168.0. ...
- Linux-Linux下安装redis报错"undefined reference to__sync_add_and_fetch_4"解决办法
如果出现这种错误可以在make的时候加上CFLAGS="-march=i686" 即 make CFLAGS="-march=i686" ----------- ...
- Erlang中atom的实现
Erlang的原子(atom)在匹配中有着重要作用,它兼顾了可读性和运行效率. 通过atom,可以实现很多灵活高效的应用. atom可以看作是给字符串生成了一个ID,内部使用的是ID值,必要时可以取出 ...
- java测试Unicode编码以及数组的运用(初学篇)
/*第二章第四小题*/ /* * (1)编写一个应用程序,给出汉字“你” ,“我”,“他”在Unicode 表中的位置 * (2)编写一个java应用程序,输出全部的希腊字母 */ public cl ...
- WordPress网站搬家的问题
老邢的博客搬家全过程(wordpress搬家知识总结) 网站搬家过程中的几个问题 WordPress网站搬家的方法 WORDPRESS.ORG - zh-cn:WordPress 博客搬家 ...
- Java虚拟机学习 - 对象访问 (2)
对象访问会涉及到Java栈.Java堆.方法区这三个内存区域. 如下面这句代码: Object objectRef = new Object(); 假设这句代码出现在方法体中,"Object ...
- python学习笔记013——模块中的私有属性
1 私有属性的使用方式 在python中,没有类似private之类的关键字来声明私有方法或属性.若要声明其私有属性,语法规则为: 属性前加双下划线,属性后不加(双)下划线,如将属性name私有化,则 ...
- 选择问题 and 字谜游戏问题
#include <stdio.h> #include <stdlib.h> // 第一题 // 找出N个数的第k个最大者 // 方法1:排序(冒泡),降序找出第k个值 // ...
- ActiveReports 报表控件官方中文新手教程 (1)-安装、激活以及产品资源
本系列文章主要是面向初次接触 ActiveReports 产品的用户,能够帮助您在三天之内轻松的掌握ActiveReports控件的基本用法,包含安装.激活.创建报表.绑定数据源以及公布等内容. ...