PairRDD中算子combineByKey图解
1、combineByKey
combine 为结合意思。
作用: 将RDD[(K,V)] => RDD[(K,C)] 表示V的类型可以转成C两者可以不同类型。
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,numPartitions:Int ):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,partitioner:Partitioner,mapSideCombine:Boolean=true,serializer:Serializer= null):RDD[(K,C)]
第一个函数和第二个函数默认使用的是HashPartitioner、serialize为null。
这个算子还是比较复杂,解释下:
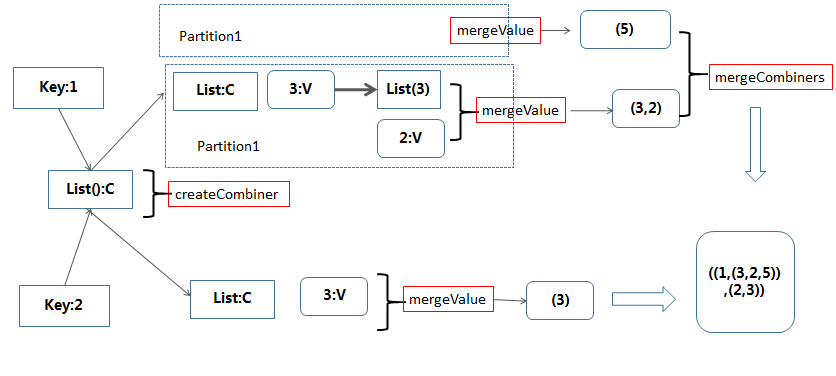
1)createCombiner:在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey第一次遇到值为k的Key(类型K),那么将对这个(k,v)调用 createCombiner函数,它的作用是将v转换为c(类型是C,聚合对象的类型,c作为局和对象的初始值)
2)mergeValue: 在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey不是第一次(或者第二次,第三次…)遇到值为k的Key(类型K),那么将对这个 (k,v)调用mergeValue函数,它的作用是将v累加到聚合对象(类型C)中,mergeValue的类型是(C,V)=>C,参数中的C遍历到此处的聚合对象,然后对v 进行聚合得到新的聚合对象值。
3)mergeCombiners:因为combineByKey是在分布式环境下执行,RDD的每个分区单独进行combineByKey操作,
最后需要对各个分区的结果进行最后的聚合,它的函数类型是(C,C)=>C,每个参数是分区聚合得到的聚合对象
例子:
scala> val data = sc.parallelize(List(("1","3"),("1","2"),("1","5"),("2","3")))
scala> val natPairRdd = data.combineByKey(List(_), (c: List[String], v: String) => v::c, (c1: List[String], c2: List[String]) => c1 ::: c2)
scala> natPairRdd.collect
res0: Array[(String, List[String])] = Array((1,List(3, 2, 5)), (2,List(3)))
PairRDD中算子combineByKey图解的更多相关文章
- PairRDD中算子aggregateByKey图解
PairRDD 有几个比较麻烦的算子,常理解了后面又忘记了,自己按照自己的理解记录好,以备查阅 1.aggregateByKey aggregate 是聚合意思,直观理解就是按照Key进行聚合. 转化 ...
- PairRDD中算子reduceByKey图解
reduceByKey 函数原型: def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) =& ...
- PairRDD中算子foldByKey图解
foldByKey 函数原型: def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] def foldByKey(zeroVal ...
- pairRDD中算子reduceByKeyLocally
原型: def reduceByKeyLocally(func: (V, V) => V): Map[K, V] 该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个 ...
- 带你学习MindSpore中算子使用方法
摘要:本文分享下MindSpore中算子的使用和遇到问题时的解决方法. 本文分享自华为云社区<[MindSpore易点通]算子使用问题与解决方法>,作者:chengxiaoli. 简介 算 ...
- 【Spark篇】---SparkStreaming中算子中OutPutOperator类算子
一.前述 SparkStreaming中的算子分为两类,一类是Transformation类算子,一类是OutPutOperator类算子. Transformation类算子updateStateB ...
- spark中的combineByKey函数的用法
一.函数的源码 /** * Simplified version of combineByKeyWithClassTag that hash-partitions the resulting RDD ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
- ES5和ES6中的继承 图解
Javascript中的继承一直是个比较麻烦的问题,prototype.constructor.__proto__在构造函数,实例和原型之间有的 复杂的关系,不仔细捋下很难记得牢固.ES6中又新增了c ...
随机推荐
- Test Double
我不知道Test Double翻译成中文是什么,测试替身?Test Double就像是陈龙大哥电影里的替身,起到以假乱真的作用.在单元测试时,使用Test Double减少对被测对象的依赖,使得测试更 ...
- table设置表格有滚动条
table 设置表格有滚动条. 少说多做,代码中有注释: <!DOCTYPE HTML> <html> <head> <meta http-equiv=&qu ...
- 文本框input:text
文本框 CreateTime--2017年4月24日10:40:40 Author:Marydon 一.文本框 (一)标签 <input type="text"/> ...
- 【Spark】RDD操作具体解释3——键值型Transformation算子
Transformation处理的数据为Key-Value形式的算子大致能够分为:输入分区与输出分区一对一.聚集.连接操作. 输入分区与输出分区一对一 mapValues mapValues:针对(K ...
- Web文件管理、私有云存储管理工具 DzzOffice
DzzOffice-大桌子办公系统本身是一款图形化,简单易用的网盘管理软件.可以实现将企业的局域网服务器.企业私有云存储.企业租用的公有云存储(如阿里云OSS).企业员工的私有云存储(如百度网盘.Dr ...
- java操作hdfs到数据库或者缓存
使用hadoop工具将数据分析出来以后,须要做入库处理或者存到缓存中.不然就没了意义 一下是使用javaAPI操作hdfs存入缓存的代码: <span style="font-fami ...
- HDUOJ-----1166敌兵布阵
敌兵布阵 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- HDUOJ------1711Number Sequence
Number Sequence Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- ASP.NET中UrlEncode应该用Uri.EscapeDataString()
今天,茄子_2008反馈他博客中的“C++”标签失效.检查了一下代码,生成链接时用的是HttpUtility.UrlEncode(url),从链接地址获取标签时用的是HttpUtility.UrlDe ...
- python学习笔记——创建事件对象Event
1 Event对象的基本概述 用 multiprocessing.Event 实现线程间通信,使用multiprocessing.Event可以使一个线程等待其他线程的通知,我们把这个Event传递到 ...