MySQL架构与引擎初识
一、MySQL逻辑架构

1、连接层:
最上层是一些客户端和连接服务,所包含的服务并不是MySQL所独有的技术。它们都是服务于C/S程序或者是这些程序所需要的 :连接处理,身份验证,安全性等等。
2、服务层:
主要完成大多数的核心服务功能,如SQL 接口,并完成缓存的查询,SQL 的分析和优化及部分内置函数的执行。所有跨存储引擎的功能也在这一层上实现,如存储过程、触发器,视图等。在该层,服务器会解析并创建相应的内部数据结构(解析树),并完成相应的优化如重写查询、决定表的读取的顺序,选择合适的索引等,最后生成对应的执行操作。如果是select 语句,服务器还会先检查查询缓存(Query Cache),如果能够在其中找到对应的查询,服务器就不必再执行查询解析、优化和执行整个过程,而是直接返回查询缓存中的结果集。如果缓存空间足够大,这样在解决大量读操作的环境中能够很好的提升系统的性能。
3、引擎层:
在存储引擎层,存储引擎真正的负责了MySql 中数据的存储和提取,服务器通过API 与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎不会去解析SQL(InnoDB是一个例外,它会解析外键定义,因为MySQL服务器本身没有实现该功能),不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
4、存储层:
数据存储层,主要将数据存储在运行于裸设备上的文件系统上,并完成与存储引擎的交互。
二、存储引擎
1、查看当前mysql支持的引擎
#查看当前mysql支持的引擎
SHOW ENGINES;

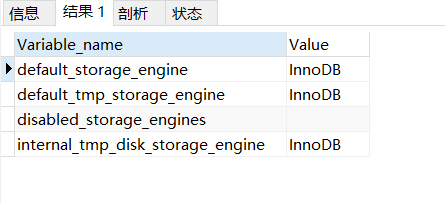
2、查看当前mysql默认的存储引擎
#查看当前mysql默认的存储引擎
SHOW VARIABLES LIKE '%storage_engine%';
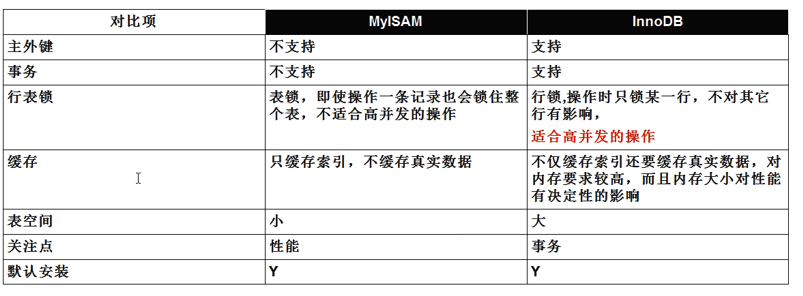
3、InnoDB引擎是mysql5.7的默认引擎,支持事务、行级锁定和外键。还有一个使用率较高的是MyISAM,两者对比如下:
MySQL架构与引擎初识的更多相关文章
- MySQL InnoDB存储引擎体系架构 —— 索引高级
转载地址:https://mp.weixin.qq.com/s/HNnzAgUtBoDhhJpsA0fjKQ 世界上只两件东西能震撼人们的心灵:一件是我们心中崇高的道德标准:另一件是我们头顶上灿烂的星 ...
- mysql架构与存储引擎 (Myisam与Innodb)
mysql抽象架构:可以分为SQL Layer和Storage Engine Layer mysql的engine层是基于表的,不是基于库的,创建表的语句可以指定engine Mysql的架构 Mys ...
- MySQL架构原理之存储引擎InnoDB数据文件
MySQL架构原理之体系架构 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中简单介绍了MySQL的系统文件层,其中包含了数据文件.那么InnoDB的数据文件是如何分类并存储的呢? 一. ...
- MySQL的BlackHole引擎在主从架构中的作用
MySQL在5.x系列提供了Blackhole引擎–“黑洞”. 其作用正如其名字一样:任何写入到此引擎的数据均会被丢弃掉, 不做实际存储:Select语句的内容永远是空. 和Linux中的 /dev/ ...
- MySQL架构原理之存储引擎InnoDB_Undo Log
Undo:意为撤销或取消,以撤销操作为目的,返回某个指定状态的操作. Undo Log:数据库事务开始之前会将要修改的记录存放到Undo日志里,当事务回滚时或者数据库崩溃时可以利用Undo日志撤销为提 ...
- 步步深入:MySQL架构总览->查询执行流程->SQL解析顺序
前言: 一直是想知道一条SQL语句是怎么被执行的,它执行的顺序是怎样的,然后查看总结各方资料,就有了下面这一篇博文了. 本文将从MySQL总体架构--->查询执行流程--->语句执行顺序来 ...
- 【转】MySQL 数据库存储引擎
原文地址:http://blog.jobbole.com/94385/ 简单介绍 存储引擎就是指表的类型.数据库的存储引擎决定了表在计算机中的存储方式.存储引擎的概念是MySQl的特点,而且是一个插入 ...
- 高性能MySQL笔记:第1章 MySQL架构
MySQL 最重要.最与众不同的特性是他的存储引擎架构,这种架构的设计将查询处理(Query Precessing)及其系统任务(Server Task)和数据的存储/提取相分离. 1.1 MyS ...
- mysql innodb存储引擎介绍
innodb存储引擎1.存储:数据目录.有配置参数为“ innodb_data_home_dir ” .“ innodb_data_file_path ” 和 “innodb_log_group_ho ...
随机推荐
- Fragment初探
Fragment允许将Activity拆分成多个完全独立封装的可重用的组件,每个组件有它自己的生命周期和UI布局.Fragment最大的优点是为不同屏幕大小创建灵活的UI.每个Fragment都是独立 ...
- 浅谈搜索引擎SEO(HTML/CSS)
SEO:搜索引擎优化(免费): SEM:搜索引擎营销(付费). 它们两者的区别是: 1.SEM高投入,SEO低投入: 2.SEM短.效益块,SEO长期投入.增长慢: 3.新广告法颁布之后SEM广告位减 ...
- MVC框架以及实例
MVC框架 MVC(model,view,controller),一种将业务逻辑.数据.界面分离的方法组织代码的框架.在改进界面及用户交互的同时,不需要重写业务逻辑.MVC将传统的输入.处理和输出分离 ...
- Python 发送邮件案例
文件形式的邮件 #!/usr/bin/env python #coding: utf-8 import smtplib from email.mime.text import MIMEText fro ...
- SQL Server ->> 使用Azure Active Directory Authentication连接到Azure SQL Database
SQL Server 2016以后支持Azure AD集成验证,这当中有些数据驱动必须在高版本才可以使用,支持的包括sqlcmd,SSDT,JDBC,ODBC,SSMS等. 对于SSIS来讲,我们需要 ...
- Linux traceroute命令详解
traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径.当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样, ...
- [EffectiveC++]item13:Use objects to manage resources(RAII)
baidu百科 RAII 百科名片 RAII,也称为“资源获取就是初始化”,是c++等编程语言常用的管理资源.避免内存泄露的方法.它保证在任何情况下,使用对象时先构造对象,最后析构对象. 目录 RAI ...
- [BZOJ 2730][HNOI 2012] 矿场搭建
2730: [HNOI2012]矿场搭建 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 2113 Solved: 979[Submit][Statu ...
- Entity Framework 指定架构无效 错误:1052
IIS发布网站:如果不发布放到IIS没有问题,发布后IIS部署 打开网站却提示指定架构无效 1052 找到很多解决的问题 1添加wenconfig 2.更改entity名的 其实我认为最简单的就是先找 ...
- 常用算法的C++实现
常用算法的C++实现 // // DZAppDelegate.m // AlgorithmTest // // Created by dzpqzb on 13-8-4. // Copyright (c ...