[测试] 试用Hadoop 2.2中的HDFS NFS
Hadoop 2.2中正式启用了hdfs nfs功能,使得hdfs的通用性迈进了一大步。在公司让小朋友搭建了一下,然后我自己进行了一点简单的试验,有一点收获,记录在此。
理论
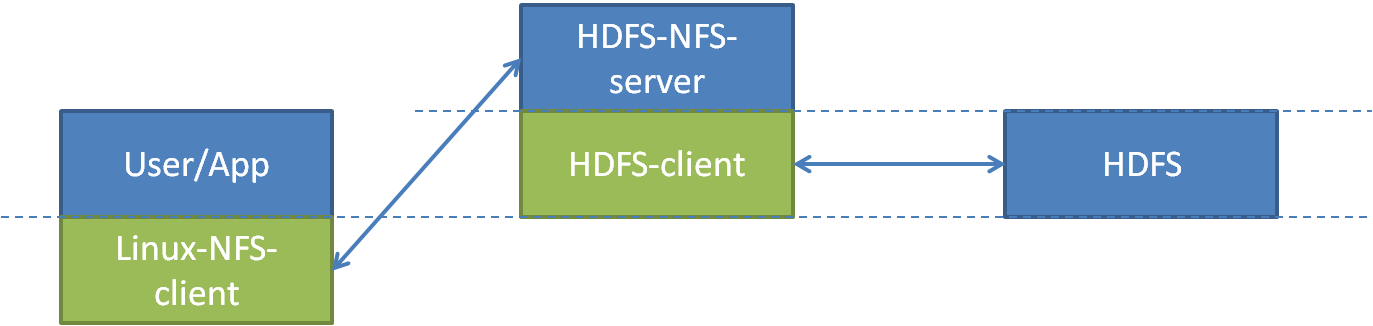
使用hdfs nfs功能的话,数据访问路径如上图:用户或程序通过Linux自带的nfs client访问hdfs nfs服务,然后再由nfs网关作为hdfs的客户端访问hdfs。
这张图中,中间的节点就是nfs代理服务器(hdfs nfs proxy)或nfs网关(hdfs nfs gateway)。蓝色代表该模块是一个进程或服务,绿色代表该模块是一个库。图中还画了两条虚线,下、上线分别表示操作系统级别和分布式操作系统(hadpp)级别的内核态与用户态分界。
部署
在nfs网关上部署hdfs nfs服务所需要的程序包,按hadoop 2.2的部署方式,应该存在这两个文件:
share/hadoop/common/hadoop-nfs-2.2.0.jar
share/hadoop/hdfs/hadoop-hdfs-nfs-2.2.0.jar
配置文件不需要改,使用默认即可;默认的几个配置分别是nfs的服务端口(标准的2049)、mount的监听端口(4242),还有一个dump目录(/tmp/.hdfs-nfs)与写逻辑有关,暂不明原理。
部署完成后,启用服务,需要依次启动portmap和nfs两个服务;
$ hadoop-daemon.sh start portmap $ hadoop-daemon.sh start nfs3
注意,portmap需要用root用户启动(因为portmap标准端口111,小于1024,是超级资源),而nfs服务应该用hdfs的超级用户启动。如果出现冲突,应该将操作系统本身的nfs服务停掉。
启动完成后,检查确认是否可用,其中nfs_server_ip是nfs网关的地址:
$ rpcinfo -p $nfs_server_ip program vers proto port
tcp mountd
udp portmapper
tcp mountd
udp mountd
tcp nfs
tcp portmapper
udp mountd
udp mountd
tcp mountd
$ showmount -e $nfs_server_ip Export list for SY-:
/ *
挂载NFS服务
创建挂载的目录
$ mkdir /mnt/hdfs
安装mount.nfs
$ sudo apt-get install nfs-common
开始挂载
$ mount.nfs $nfs_server_ip:/ /mnt/hdfs
试用及分析
尝试访问/mnt/hdfs,试用了简单的ls、cp、rm等操作,也进行了md5sum,都可以正常使用,而且响应速度明显快于通过FsShell进行操作,这应该是得益于nfs的wcc缓存及hdfs nfs的实现中对连接的缓存;
但hdfs nfs是否是一个完全兼容标准文件系统接口的实现呢,为此我测试了一下最难处理的随机写和复写,代码如下,简单的说,就是做三次写,第一次写在文件头(字符1),第二次写在文件尾(字符2),第三次写在文件中间(字符3):
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h> void usage(char* argv[]) {
fprintf(stdout, "%s <file_length>\n", argv[]);
fprintf(stdout, "NOTE:\n");
fprintf(stdout, " file_length >= 3\n");
} bool open_and_check(FILE** fpp, int op_seq) {
(*fpp) = fopen("testfile", "r+"); if ((*fpp) == NULL) {
fprintf(stderr, "%d.Can not open test file.\n", op_seq);
return false;
} return true;
} int main(int args, char* argv[]) {
if (args != ) {
usage(argv);
return -;
} int length = atoi(argv[]);
if (length < ) {
fprintf(stdout, "file_length must be at least 3\n");
return -;
} fclose(fopen("testfile", "w+")); FILE* fp;
int op_seq = ; if (!open_and_check(&fp, op_seq))
return op_seq;
putc(''+op_seq, fp); // '1'
fclose(fp);
op_seq++; if (!open_and_check(&fp, op_seq))
return op_seq;
fseek(fp, length, SEEK_SET);
putc(''+op_seq, fp); // '2'
fclose(fp);
op_seq++; if (!open_and_check(&fp, op_seq))
return op_seq;
fseek(fp, length/, SEEK_SET);
putc(''+op_seq, fp); // '3'
fclose(fp);
//op_seq++; return ;
}
test_rrw.c
注:参数n是第二次写之前做的偏移量,因而实际文件长度会是n+1
1. 首先用一个小文件做测试,如下:
root@xxx:/mnt/hdfs/tmp# ./a.out
root@xxx:/mnt/hdfs/tmp# ls -l testfile
-rw-r--r-- root root Nov : testfile
root@xxx:/mnt/hdfs/tmp# cat testfile
结果都符合预期;
2. 如果再重复执行一次呢?
root@xxx:/mnt/hdfs/tmp# ./a.out
Segmentation fault (core dumped)
从hdfs nfs网关的日志中可以找到出错的原因:
2013-11-27 18:11:53,695 ERROR org.apache.hadoop.hdfs.nfs.nfs3.RpcProgramNfs3: Setting file size is not supported when setattr, fileId: 20779
不支持重置文件大小,也就是不支持truncate,至少还“正确地”返回了失败;
3. 改变文件大小测试一下
root@SY-:/mnt/hdfs/tmp# ./a.out && ls -lh --full-time testfile && sleep && ls -lh --full-time testfile
-rw-r--r-- root root 2.1K -- ::40.572000000 + testfile
-rw-r--r-- root root -- ::40.572000000 + testfile
root@SY-:/mnt/hdfs/tmp# rm testfile
root@SY-:/mnt/hdfs/tmp# ./a.out && ls -lh --full-time testfile && sleep && ls -lh --full-time testfile
-rw-r--r-- root root 4.0K -- ::17.606000000 + testfile
-rw-r--r-- root root 4.0K -- ::17.606000000 + testfile
可以发现从4K开始,向上的文件已经无法正常完成这个测试了,文件会隐性的丢失数据。这应该与hdfs nfs对随机写和复写的实现有关,我没有具体研究代码。
从这个简单测试可以得出结论,hdfs nfs可以进行简单的文件读写、使用常用的shell命令操作,但决不可以直接当本地文件系统、通过程序进行访问。
[测试] 试用Hadoop 2.2中的HDFS NFS的更多相关文章
- Hadoop在eclipse中的配置
在安装完linux下的hadoop框架,实现完所现有的wordCount程序,能够完美输出结果之后,我们开始来搭建在window下的eclipse的环境,进行相关程序的编写. 在网上有很多未编译版本, ...
- Hadoop第4周练习—HDFS读写文件操作
1 运行环境说明... 3 :编译并运行<权威指南>中的例3.2. 3 内容... 3 2.3.1 创建代码目录... 4 2.3.2 建立例子文件上传到hdfs中... 4 ...
- Hadoop学习笔记一(HDFS架构)
介绍 Hadoop分布式文件系统(HDFS)设计的运行环境是商用的硬件系统.他和现存的其他分布式文件系统存在很多相似点.不过HDFS和其他分布式文件系统的区别才是他的最大亮点,HDFS具有高容错的特性 ...
- Apache Hadoop 2.9.2 的HDFS High Available模式部署
Apache Hadoop 2.9.2 的HDFS High Available 模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道,当NameNode进程挂掉后,可 ...
- Hadoop生态集群之HDFS
一.HDFS是什么 HDFS是hadoop集群中的一个分布式的我文件存储系统.他将多台集群组建成一个集群,进行海量数据的存储.为超大数据集的应用处理带来了很多便利. 和其他的分布式文件存储系统相比他有 ...
- 第九章 搭建Hadoop 2.2.0版本HDFS的HA配置
Hadoop中的NameNode好比是人的心脏,非常重要,绝对不可以停止工作.在hadoop1时代,只有一个NameNode.如果该NameNode数据丢失或者不能工作,那么整个集群就不能恢复了.这是 ...
- Hadoop学习---Ubuntu中hadoop完全分布式安装教程
软件版本 Hadoop版本号:hadoop-2.6.0-cdh5.7.0: VMWare版本号:VMware 9或10 Linux系统:CentOS 6.4-6.5 或Ubuntu版本号:ubuntu ...
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
- HBase 中读 HDFS 调优
HDFS Read调优 在基于 HDFS 存储的 HBase 中,主要有两种调优方式: 绕过RPC的选项,称为short circuit reads 开启让HDFS推测性地从多个datanode读数据 ...
随机推荐
- P6 EPPM 安装与配置指南 16 R1 2016.4
关于安装和 配置P6 EPPM 本指南告诉你如何自动 安装和配置您的应用程序. 在您开始之前,阅读 先决条件 P6 EPPM配置 (7页). 安装P6 EPPM 您将使用 安装程序 (窗口) . ...
- C#实战Microsoft Messaging Queue(MSMQ)消息队列(干货)
前言 在使用MSMQ之前,我们需要自行安装消息队列组件!(具体安装方法大家自己搜一下吧) 采用MSMQ带来的好处是:由于是异步通信,无论是发送方还是接收方都不用等待对方返回成功消息,就可以执行余下的代 ...
- 收集数据至泛型Dictionary
开发时,我们经常使用到泛型,不管是List<T>,还是Dictionary<T,V>,下面Insus.NET在测试一些功能,当使用到一些临时数据集时,有好几种方法把数据收集至D ...
- [moka同学摘录]在Centos 6.5下成功安装和配置了vim7.4
来源:https://my.oschina.net/gzyh/blog/266097 资源下载地址: 链接:http://pan.baidu.com/s/1kVuaV5P 密码:xkq9 摘要: ...
- java中的代码块执行顺序
/* 代码块:在Java中,使用{}括起来的代码被称为代码块. 根据其位置和声明的不同,可以分为 局部代码块:局部位置,用于限定变量的生命周期. 构造代码块:在类中的成员位置,用{}括起来的代码.每次 ...
- 在Hadoop平台跑python脚本
1.开发IDE,我使用的是PyCharm. 2.运行原理 使用python写MapReduce的“诀窍”是利用Hadoop流的API,通过STDIN(标准输入).STDOUT(标准输出)在 ...
- 【GOF23设计模式】命令模式
来源:http://www.bjsxt.com/ 一.[GOF23设计模式]_命令模式.数据库事务机制底层架构实现.撤销和回复 package com.test.command; public cla ...
- JS控制HTML元素的显示和隐藏
JS控制HTML元素的显示和隐藏 利用来JS控制页面控件显示和隐藏有两种方法,两种方法分别利用HTML的style中的两个属性,两种方法的不同之处在于控件隐藏后是否还在页面上占空位. 方法一: 1 2 ...
- 学习总结——DOM
DOM(Document Object Model),即文档对象模型.DOM是针对HTML和XML文档的一个API,它描绘了一个层次化的节点树,允许开发人员添加.移除和修改页面的某一部分.在定义方面, ...
- Hosts文件小结
今天又遇到Hosts,小结一下: Hosts文件是什么? Hosts文件从表象上来看是一个没有扩展名的系统文件.其基本作用就是将一些常用的网址域名与其对应的IP地址建立一个关联"数据库&qu ...