pandas基础--基本功能
pandas含有是数据分析工作变得更快更简单的高级数据结构和操作工具,是基于numpy构建的。
本章节的代码引入pandas约定为:import pandas as pd,另外import numpy as np也会用到。
官方介绍:pandas - Python Data Analysis Library (pydata.org)
5 基本功能
本节介绍操作Series和DataFrame中的数据的基本手段。
5.1 重新索引
重新索引reindex,其作用是创建一个适应新索引的新对象。调用reindex将会根据新索引进行重排,如果某个索引值当前不存在,就引入缺失值。
1 >>> obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c'])
2 >>> obj
3 d 4.5
4 b 7.2
5 a -5.3
6 c 3.6
7 dtype: float64
8 >>> obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e'])
9 >>> obj2
10 a -5.3
11 b 7.2
12 c 3.6
13 d 4.5
14 e NaN
15 dtype: float64
16 >>> obj.reindex(['a', 'b', 'c', 'd', 'e'], fill_value=0)
17 a -5.3
18 b 7.2
19 c 3.6
20 d 4.5
21 e 0.0
22 dtype: float64
23 >>>
对于时间序列这样的有序数据,重新索引时可能需要做一些插值处理,method选项即可达到此目的。
1 >>> obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
2 >>> obj3.reindex(range(6), method='ffill')
3 0 blue
4 1 blue
5 2 purple
6 3 purple
7 4 yellow
8 5 yellow
9 dtype: object
下表是可用的method选项。
| 方法 | 说明 |
|---|---|
| ffill或pad | 前向填充(或搬运)值 |
| bfill或backfill | 后向填充(或搬运)值 |
对于DataFrame,reindex可以修改(行)索引、列,或两个都修改,如果仅传入一个序列,则会重新索引行。
1 >>> frame = pd.DataFrame(np.arange(9).reshape((3, 3)), index=['a', 'c', 'd'], columns=['Ohio', 'Texas', 'California'])
3 >>> frame
4 Ohio Texas California
5 a 0 1 2
6 c 3 4 5
7 d 6 7 8
8 >>> frame2 = frame.reindex(['a', 'b', 'c', 'd']) #重新索引行
9 >>> frame2
10 Ohio Texas California
11 a 0.0 1.0 2.0
12 b NaN NaN NaN
13 c 3.0 4.0 5.0
14 d 6.0 7.0 8.0
15 >>> states = ['Texas', 'Utah', 'California']
16 >>> frame.reindex(columns=states) #使用columns关键字重新索引列
17 Texas Utah California
18 a 1 NaN 2
19 c 4 NaN 5
20 d 7 NaN 8
21 >>> frame.reindex(index=['a', 'b', 'c', 'd'], method='ffill')
22 Ohio Texas California
23 a 0 1 2
24 b 0 1 2
25 c 3 4 5
26 d 6 7 8
下表是reindex函数的各参数及说明。
| 参数 | 说明 |
|---|---|
| index | 用作索引的新序列,既可以是Index实例,也可以是其他序列型的python数据结构,Index会被完全使用,就像没有任何复制一样 |
| method | 插值(填充)方式,具体常见之前的表格 |
| fill_value | 在重新索引的过程中,需要引入缺失值时使用的替代值 |
| limit | 前向或后向填充时的最大填充量 |
| level | 在MultiIndex的指定级别上匹配简单索引,否则选取其子集 |
| copy | 默认为True,无论无何都复制,否则为False,则新旧相等就不复制 |
5.2 丢弃指定轴上的项
丢弃某条轴上的一个或多个项只要有一个索引数组或列表即可完成。由于需要执行一些数据整理和集合逻辑,所以drop方法返回的是一个在指定轴上删除了指定值的新对象。
1 >>> obj = pd.Series(np.arange(5), index=['a', 'b', 'c', 'd', 'e'])
2 >>> new_obj = obj.drop('c')
3 >>> new_obj
4 a 0
5 b 1
6 d 3
7 e 4
8 dtype: int32
9 >>> obj.drop(['d', 'c'])
10 a 0
11 b 1
12 e 4
13 dtype: int32
对于DataFrame,可以删除任意轴上的索引值。
1 >>> data = pd.DataFrame(np.arange(16).reshape((4, 4)), index=['Oh', 'Co', 'Ut', 'New'], columns=['one', 'two', 'three', 'four'])
2 >>> data
3 one two three four
4 Oh 0 1 2 3
5 Co 4 5 6 7
6 Ut 8 9 10 11
7 New 12 13 14 15
8 >>> data.drop('two', axis=1)
9 one three four
10 Oh 0 2 3
11 Co 4 6 7
12 Ut 8 10 11
13 New 12 14 15
14 >>> data.drop(['two', 'four'], axis=1)
15 one three
16 Oh 0 2
17 Co 4 6
18 Ut 8 10
19 New 12 14
5.3 索引、选取和过滤
5.3.1 Series索引
Series索引(obj[…])的工作方式类似于NumPy数组的索引,只不过Series的索引值不是整数。
1 >>> obj = pd.Series(np.arange(4), index=['a', 'b', 'c', 'd'])
2 >>> obj['b']
3 1
4 >>> obj[1]
5 1
6 >>> obj[2:4]
7 c 2
8 d 3
9 dtype: int32
10 >>> obj[['b', 'a', 'd']]
11 b 1
12 a 0
13 d 3
14 dtype: int32
15 >>> obj[[1, 3]]
16 b 1
17 d 3
18 dtype: int32
19 >>> obj[obj < 2]
20 a 0
21 b 1
22 dtype: int32
23 >>>
利用标签的切片运算和普通的python切片运算不同,其末端是包含的。
1 >>> obj
2 a 0
3 b 1
4 c 2
5 d 3
6 dtype: int32
7 >>> obj['b':'d']
8 b 1
9 c 2
10 d 3
11 dtype: int32
12 >>> obj['b':'d'] = 5 #赋值操作
13 >>> obj
14 a 0
15 b 5
16 c 5
17 d 5
18 dtype: int32
5.3.2 DataFrame索引
对DataFrame进行索引就是获取一个或多个列。
1 >>> data
2 one two three four
3 Oh 0 1 2 3
4 Co 4 5 6 7
5 Ut 8 9 10 11
6 New 12 13 14 15
7 >>> data['two']
8 Oh 1
9 Co 5
10 Ut 9
11 New 13
12 Name: two, dtype: int32
13 >>> data[['three', 'one']]
14 three one
15 Oh 2 0
16 Co 6 4
17 Ut 10 8
18 New 14 12
19 >>> data[:2] # 通过切片选取行
20 one two three four
21 Oh 0 1 2 3
22 Co 4 5 6 7
23 >>> data[data['three'] > 5] #通过布尔型数组选取行
24 one two three four
25 Co 4 5 6 7
26 Ut 8 9 10 11
27 New 12 13 14 15
28 >>> data < 5
29 one two three four
30 Oh True True True True
31 Co True False False False
32 Ut False False False False
33 New False False False False
34 >>> data[data < 5] = 0 #通过布尔型数组选取行
35 >>> data
36 one two three four
37 Oh 0 0 0 0
38 Co 0 5 6 7
39 Ut 8 9 10 11
40 New 12 13 14 15
41 >>>
DataFrame的索引选项如下表所示:
| 类型 | 说明 |
|---|---|
| obj[val] | 选取DataFrame的单个列或一组列,在一些特殊情况下会比较方便:布尔型数组(过滤行)、切片(行切片)、布尔型DataFrame(根据条件设置值) |
| reindex方法 | 将一个或多个轴匹配到新索引 |
| xs | 根据标签选取单行或单列,返回一个Series |
5.4 算术运算和数据对齐
pandas可以对不同索引的对象进行算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。
自动的数据对齐操作在不重叠的索引处引入了NaN值,缺失值会在算术运算过程中传播。
1 >>> s1 = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
2 >>> s2 = pd.Series([5, 6, 7, 8], index = ['a', 'c', 'e', 'f'])
3 >>> s1 + s2 #加法操作
4 a 6.0
5 b NaN
6 c 9.0
7 d NaN
8 e NaN
9 f NaN
10 dtype: float64
11 >>>
对于DataFrame,对齐操作会同时发生在行和列上。它们相加后会返回一个新的DataFrame,其索引和列为原来那两个DataFrame的并集。
1 >>> df1 = pd.DataFrame(np.arange(9).reshape((3, 3)), columns=list('bcd'), index=['one', 'two', 'three'])
3 >>> df2 = pd.DataFrame(np.arange(4).reshape((2, 2)), columns=list('be'), index=['two', 'four'])
4 >>> df1
5 b c d
6 one 0 1 2
7 two 3 4 5
8 three 6 7 8
9 >>> df2
10 b e
11 two 0 1
12 four 2 3
13 >>> df1 + df2 #相加
14 b c d e
15 four NaN NaN NaN NaN
16 one NaN NaN NaN NaN
17 three NaN NaN NaN NaN
18 two 3.0 NaN NaN NaN
19 >>>
5.5 在算术方法中填充值
对不同索引的对象进行算术运算时,当一个对象中某个轴标签在另一个对象中找不到时填充一个特殊值。
1 >>> df1
2 b c d
3 one 0 1 2
4 two 3 4 5
5 three 6 7 8
6 >>> df2
7 b e
8 two 0 1
9 four 2 3
10 >>> df1.add(df2, fill_value=0)
11 b c d e
12 four 2.0 NaN NaN 3.0
13 one 0.0 1.0 2.0 NaN
14 three 6.0 7.0 8.0 NaN
15 two 3.0 4.0 5.0 1.0
16 >>> df1.add(df2, fill_value=1)
17 b c d e
18 four 3.0 NaN NaN 4.0
19 one 1.0 2.0 3.0 NaN
20 three 7.0 8.0 9.0 NaN
21 two 3.0 5.0 6.0 2.0
22 >>> df1.reindex(columns=df2.columns, fill_value=0)
23 b e
24 one 0 0
25 two 3 0
26 three 6 0
灵活的算术方法如下表所示:
| 方法 | 说明 |
|---|---|
| add | 用于加法(+)的方法 |
| sub | 用于减法(-)的方法 |
| div | 用于除法(/)的方法 |
| mul | 用于乘法(*)的方法 |
5.6 DataFrame和Series之间的运算
DataFrame和Series之间的运算由明确的规定。例如计算一个二维数组与其某行之间的差。
1 >>> arr = np.arange(12).reshape((3, 4))
2 >>> arr
3 array([[ 0, 1, 2, 3],
4 [ 4, 5, 6, 7],
5 [ 8, 9, 10, 11]])
6 >>> arr[0]
7 array([0, 1, 2, 3])
8 >>> arr - arr[0] #会进行广播
9 array([[0, 0, 0, 0],
10 [4, 4, 4, 4],
11 [8, 8, 8, 8]])
DataFrame和Series之间的运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播。
1 >>> frame = pd.DataFrame(np.arange(12).reshape((4, 3)), columns=list('bde'), index=['Ut', 'Oh', 'Te', 'Or'])
2 >>> frame
3 b d e
4 Ut 0 1 2
5 Oh 3 4 5
6 Te 6 7 8
7 Or 9 10 11
8 >>> series = pd.Series(np.arange(3), index=['b', 'd', 'e'])
9 >>> series
10 b 0
11 d 1
12 e 2
13 dtype: int32
14 >>> frame - series
15 b d e
16 Ut 0 0 0
17 Oh 3 3 3
18 Te 6 6 6
19 Or 9 9 9
20 >>>
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集。
1 >>> series2 = pd.Series(range(3), index=list('bef'))
2 >>> series2
3 b 0
4 e 1
5 f 2
6 dtype: int64
7 >>> frame
8 b d e
9 Ut 0 1 2
10 Oh 3 4 5
11 Te 6 7 8
12 Or 9 10 11
13 >>> frame + series2
14 b d e f
15 Ut 0.0 NaN 3.0 NaN
16 Oh 3.0 NaN 6.0 NaN
17 Te 6.0 NaN 9.0 NaN
18 Or 9.0 NaN 12.0 NaN
19 >>>
如果希望匹配行且在列上广播,则必须使用算术运算方法。
1 >>> series3 = frame['d']
2 >>> frame
3 b d e
4 Ut 0 1 2
5 Oh 3 4 5
6 Te 6 7 8
7 Or 9 10 11
8 >>> series3
9 Ut 1
10 Oh 4
11 Te 7
12 Or 10
13 Name: d, dtype: int32
14 >>> frame.sub(series3, axis=0)
15 b d e
16 Ut -1 0 1
17 Oh -1 0 1
18 Te -1 0 1
19 Or -1 0 1
5.7 函数应用和映射
NumPy的ufuncs(元素级数组方法)也可用于操作pandas对象。
1 >>> frame
2 b d e
3 Ut 0 -3 2
4 Oh 3 -3 5
5 Te 6 -3 8
6 Or 9 -3 11
7 >>> np.abs(frame)
8 b d e
9 Ut 0 3 2
10 Oh 3 3 5
11 Te 6 3 8
12 Or 9 3 11
另一个常见操作,将函数应用到各列或行所形成的一维数组上。DataFrame的apply方法可实现此功能。
1 >>> f = lambda x: x.max() - x.min()
2 >>> frame
3 b d e
4 Ut 0 -3 2
5 Oh 3 -3 5
6 Te 6 -3 8
7 Or 9 -3 11
8 >>> frame.apply(f)
9 b 9
10 d 0
11 e 9
12 dtype: int64
13 >>> frame.apply(f, axis=1)
14 Ut 5
15 Oh 8
16 Te 11
17 Or 14
18 dtype: int64
19 >>>
除标量值外,传递给apply的函数还可以返回由多个值组成的Series。
1 >>> def f(x):
2 ... return pd.Series([x.min(), x.max()], index=['min', 'max'])
3 ...
4 >>> frame
5 b d e
6 Ut 0 -3 2
7 Oh 3 -3 5
8 Te 6 -3 8
9 Or 9 -3 11
10 >>> frame.apply(f)
11 b d e
12 min 0 -3 2
13 max 9 -3 11
14 >>>
元素级的python函数也是可以使用的。例如求frame中各个浮点值的格式化字符串,使用applymap即可。
1 >>> format = lambda x: '%.2f' % x
2 >>> frame.applymap(format)
3 b d e
4 Ut 0.00 -3.00 2.00
5 Oh 3.00 -3.00 5.00
6 Te 6.00 -3.00 8.00
7 Or 9.00 -3.00 11.00
5.8 排序和排名
5.8.1 排序
根据条件对数据集排序(sorting)也是一种重要的内置运算。
要对行或列索引进行排序(按字典顺序),可使用sort_index方法,它返回的是一个已排序的新对象。
1 >>> obj = pd.Series(range(4), index=['d', 'e', 'b', 'c'])
2 >>> obj.sort_index()
3 b 2
4 c 3
5 d 0
6 e 1
7 dtype: int64
对于DataFrame,可以根据任意一个轴上的索引进行排序。
1 >>> frame = pd.DataFrame(np.arange(8).reshape((2, 4)), index=['three', 'one'], columns=['d', 'e', 'b', 'c'])
2 >>> frame.sort_index()
3 d e b c
4 one 4 5 6 7
5 three 0 1 2 3
6 >>> frame.sort_index(axis=1) #对轴1进行排序
7 b c d e
8 three 2 3 0 1
9 one 6 7 4 5
10 >>> frame.sort_index(axis=1, ascending=False) #默认为升序,改为降序
11 e d c b
12 three 1 0 3 2
13 one 5 4 7 6
14 >>>
5.8.2 排名
排名跟排序密切相关,且它会增加一个排名值(从1开始,一直到数组中有效数据的数量)。使用的是rank方法,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的。
可参考我的另一篇博客:pandas rank()函数简介 - zhengcixi - 博客园 (cnblogs.com)
官方文档:pandas.DataFrame.rank — pandas 1.3.4 documentation (pydata.org)
这里有点不好理解,可按照下图理解。
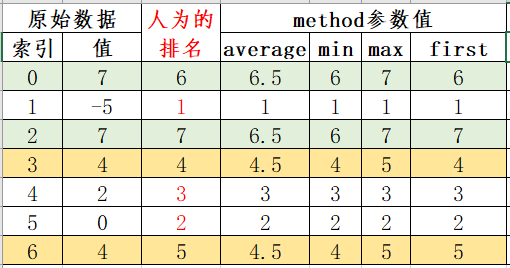
method参数说明。
| method | 说明 |
|---|---|
| ‘average’ | 默认,在相等分组中,为各个值分配平均排名 |
| ‘min’ | 使用整个分组的最小排名 |
| ‘max’ | 使用整个分组的最大排名 |
| ‘first’ | 按值在原始数据中出现顺序分配排名 |
示例:
1 >>> obj = pd.Series([7, -5, 7, 4, 2, 0, 4])
2 >>> obj.rank()
3 0 6.5
4 1 1.0
5 2 6.5
6 3 4.5
7 4 3.0
8 5 2.0
9 6 4.5
10 dtype: float64
11 >>> obj
12 0 7
13 1 -5
14 2 7
15 3 4
16 4 2
17 5 0
18 6 4
19 dtype: int64
20 >>> obj.rank(method='first') #根据值在原数据中出现的顺序给出排名
21 0 6.0
22 1 1.0
23 2 7.0
24 3 4.0
25 4 3.0
26 5 2.0
27 6 5.0
28 dtype: float64
29 >>> obj.rank(ascending=False, method='max') #按降序进行排名
30 0 2.0
31 1 7.0
32 2 2.0
33 3 4.0
34 4 5.0
35 5 6.0
36 6 4.0
37 dtype: float64
DataFrame可以在行或列上计算排名:
1 >>> frame = pd.DataFrame({'b': [4.3, 7, -3, 2], 'a': [0, 1, 0, 1], 'c': [-2, 5, 8, -2.5]})
2 >>> frame
3 b a c
4 0 4.3 0 -2.0
5 1 7.0 1 5.0
6 2 -3.0 0 8.0
7 3 2.0 1 -2.5
8 >>> frame.rank(axis=1)
9 b a c
10 0 3.0 2.0 1.0
11 1 3.0 1.0 2.0
12 2 1.0 2.0 3.0
13 3 3.0 2.0 1.0
5.9 带有重复值的轴索引
pandas并不强制要求轴标签唯一。对于带有重复值的索引,数据选取的型位将会有所不同。如果某个索引对应多个值,则返回一个Series;而对应单个值的,则返回一个标量值。DataFrame也是如此。
1 >>> obj = pd.Series(range(5), index=['a', 'a', 'b', 'b', 'c'])
2 >>> obj
3 a 0
4 a 1
5 b 2
6 b 3
7 c 4
8 dtype: int64
9 >>> obj.index.is_unique
10 False
11 >>> obj['a']
12 a 0
13 a 1
14 dtype: int64
15 >>> obj['c']
16 4
pandas基础--基本功能的更多相关文章
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
- Pandas基础笔记
Basic knowledge of Pandas pandas库是以numpy库为基础建成的,是python数据分析的核心库.也正因如此,pandas内的数据结构与numpy的数组有许多相似的地方. ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- pandas的基本功能(一)
第16天pandas的基本功能(一) 灵活的二进制操作 体现在2个方面 支持一维和二维之间的广播 支持缺失值数据处理 四则运算支持广播 +add - sub *mul /div divmod()分区和 ...
随机推荐
- Vue3实现图片滚轮缩放和拖拽
在项目开发中遇到一个需求: 1:用鼠标滚轮可对图片进行缩放处理 2:点击按钮可对图片进行缩放处理 3:可对图片进行拖拽处理 我在开发中通过自己实现与百度查看优秀的铁子进行了两种类型的使用 <te ...
- maven报错:501 HTTPS Required
maven报错:501 HTTPS Required 简单来说,如果报错中出现http://repo1.maven.org/maven2/的字样的话,那么大概率就是Maven仓库的设置里的地址有问题, ...
- 行业 SaaS 微服务稳定性保障实战
简介: 对于Tob企业而言,稳定性即是生命线.那么,面对商户数目暴增, C 端场景业务不断扩展呢,F6汽车科技又是如何搭建可观测体系呢?一线负责人深度解读实际演进过程! 很多研发人员在日常工作中经常回 ...
- 我们为什么要做 SoloPi
SoloPi现状 去年(2019年)7月份,蚂蚁集团正式对外开源了客户端自动化测试工具 SoloPi ,其主要包括三大模块:录制回放(用于功能测试).性能工具(用于性能测试)以及一机多控(服务于兼容性 ...
- 轻松处理高于平常10倍的视频需求,还能节省60%的IT成本,蓝墨做对了什么?
近年来,Serverless 一直在高速发展,并呈现出越来越大的影响力.主流的云服务商也在不断地丰富云产品体系,提供更好的开发工具,更高效的应用交付流水线,更好的可观测性,更细腻的产品间集成,但一切才 ...
- EventBridge 特性介绍|以 IaC 的方式使用 EventBridge
简介:本文将重点介绍 EventBridge 和 IaC 的重点概念和特性,然后演示如何应用 IaC 理念自动化部署 EventBridge 来使用这些概念和特性. 作者:王川(弗丁) 引言 Eve ...
- Cube 技术解读 | 支付宝新一代动态化技术架构与选型综述
简介: 支付宝客户端的动态化技术经历三个阶段:现阶段也就是第三阶段是实体组件+部分光栅化的hybrid模式,Cube 就是该模式下的产物. 如标题所述,笔者将持续更新<Cube 技术解读& ...
- [FAQ] Beego2.0.2 bee 生成的 api 项目运行 404, http server Running on http://:8080
Beego, bee version 2.0.2 https://github.com/beego/beego/issues/4363 Tool:AI 编程助手 Refer:Beego还流行吗 Lin ...
- [Contract] 一次搞懂 ETH Gas, GasPrice, GasLimit 之间关系与使用
Gas 是一个交易费的基本单位(unit),类似汽油的单位"升",比如一次链上交易可能消耗 5 Gas 汽油,由运行的程序决定. GasPrice 是一个 Gas 的单价,一般用 ...
- 笔记06-第六讲 Cadence同一页面建立电气互连
笔记06-第六讲 Cadence同一页面建立电气互连 内容: 90度和任意角度连线; 连线方式; 十字线添加/删除连接点; Net alias; 无连接的管脚处理; 注意事项. 连线有两种方式,右侧工 ...