聊聊大数据框架的数据更新策略: COW,MOR,MOW
大数据框架下,常用的数据更新策略有三种:
COW: copy-on-write, 写时复制;
MOR: merge-on-read, 读时合并;
MOW: merge-on-write, 写时合并;
hudi等数据湖仓框架,常用的是前两种实现数据更新。而Doris则主要用后两种更新数据。
COW
在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据,创建数据文件的新版本。新版本文件包括旧版本文件的记录以及来自传入批次的记录(全量最新)。
正在读数据的请求,读取的是最近的完整副本,这类似Mysql 的MVCC的思想。
在java的类库中就有一个CopyOnWriteArrayList,而linux的fork子进程的内部机制也是通过COW实现。可以说,COW是比较常用的数据更新与复制手段。
MOR
新插入的数据存储在delta log 中,定期再将delta log合并进行parquet数据文件。读取数据时,会将delta log跟老的数据文件做merge。
这个merge的过程一般是多路归并排序的实现:查询时将重复的 Key 排在一起,并进行聚合操作,其中高版本 Key 的会覆盖低版本的 Key,最终只返回给用户版本最高的那一条记录。
MOW
将被覆盖和被更新的数据进行标记删除,同时将新的数据写入新的文件。在查询的时候, 所有被标记删除的数据都会在文件级别被过滤掉,读取出来的数据就都是最新的数据,消除掉了读时合并中的数据聚合过程,并且能够在很多情况下支持多种谓词的下推。
别的大数据框架我没有查到相关的信息,这个的应用主要是在Doris的Unique数据模型中,即通过MOW实现了Unique数据模型下的数据更新。
Doris的MOW的实现方案是: Delete + Insert。即在数据写入时通过一个主键索引查找到被覆盖的 Key,将其标记为删除。 参考自微软的 SQL Server 在 2015 年 VLDB 上发表的论文《Real-Time Analytical Processing with SQL Server》中提出的方案。
Delete + Insert
这篇论文提出了数据写入时将旧的数据标记删除(使用一个 Delete Bitmap 的数据结构),并将新数据记录在 Delta Store 中,查询时将 Base 数据、Delete Bitmap、Delta Store 中的数据 Merge 起来以得到最新的数据。整体方案如下图所示
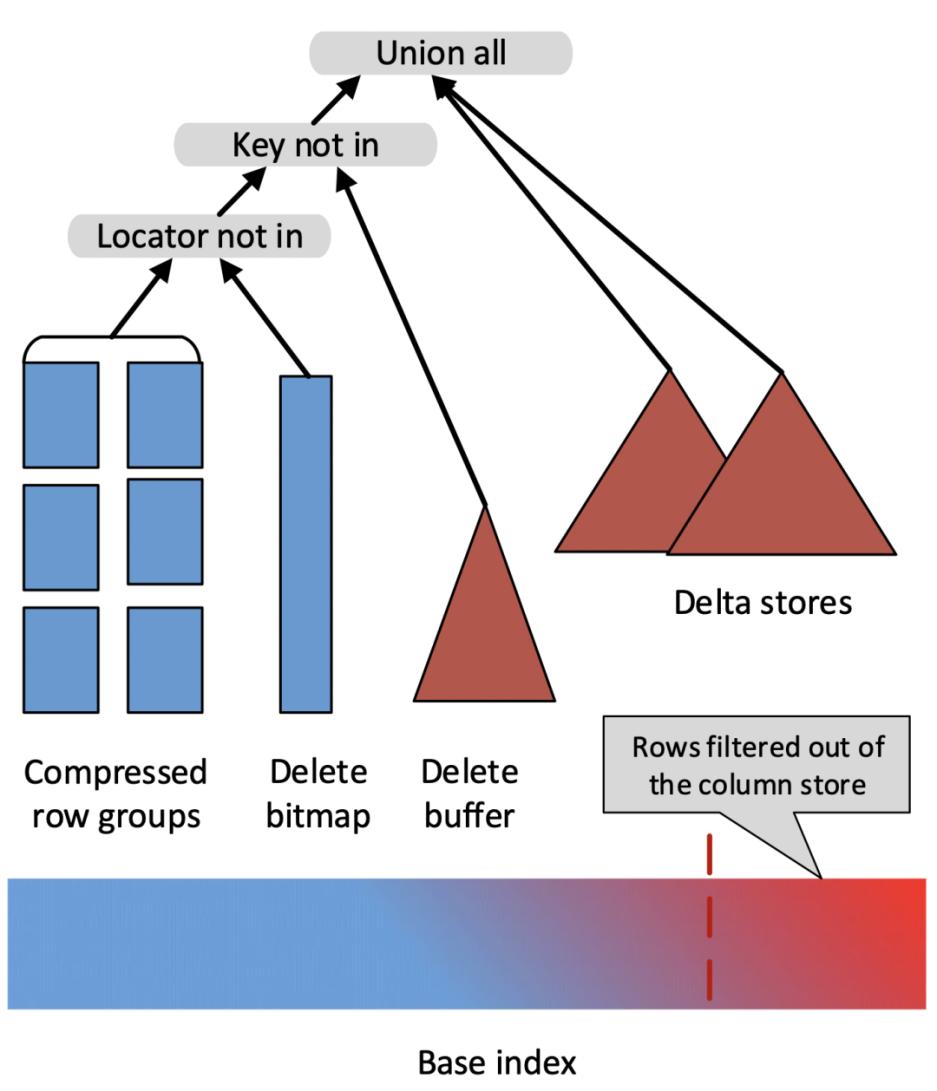
其优点是,任何一个有效的主键只存在于一个地方(要么在 Base Data 中,要么在 Delta Store 中),这样就避免了查询过程中的大量归并排序的消耗,同时 Base 数据中的各种丰富的列存索引也仍然有效。
简单来讲,Merge-On-Write 的处理流程是:
- 对于每一条 Key,查找它在 Base 数据中的位置(rowsetid + segmentid + 行号)
- 如果 Key 存在,则将该行数据标记删除。标记删除的信息记录在 Delete Bitmap中,其中每个 Segment 都有一个对应的 Delete Bitmap
- 将更新的数据写入新的 Rowset 中,完成事务,让新数据可见(能够被查询到)
- 查询时,读取 Delete Bitmap,将被标记删除的行过滤掉,只返回有效的数据
总结
之所以会有这篇文章,主要是想总结一下大数据框架下常用的(准实时/实时)数据更新的常用解决方案,毕竟解决方案是通用的,只是实现方式会有差异。
关于更详细的内容与实现,请参考:
10x 查询性能提升,全新 Unique Key 的设计与实现
聊聊大数据框架的数据更新策略: COW,MOR,MOW的更多相关文章
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
转自:https://www.cnblogs.com/reed/p/7730329.html 今天看到一篇讲得比较清晰的框架对比,这几个框架的选择对于初学分布式运算的人来说确实有点迷茫,相信看完这篇文 ...
- 大数据框架:Spark vs Hadoop vs Storm
大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生. 知识预热 「专治不明觉厉」之“大数据”: 大数据生态圈及其技术栈: 关于大数据的四大特征(4V) 海量的数据规模( ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- YARN之上的大数据框架REEF:微软出品,是否值得期待?
YARN之上的大数据框架REEF:微软出品,是否值得期待? 摘要:微软即将开源大数据框架REEF,REEF运行于Hadoop新一代资源管理器YARN的上层.对于机器学习等在数据传输.任务监控和结果 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 老李分享:大数据框架Hadoop和Spark的异同
poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821478,咨询电话010-845052 ...
- [转载] 2 分钟读懂大数据框架 Hadoop 和 Spark 的异同
转载自https://www.oschina.net/news/73939/hadoop-spark-%20difference 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字 ...
- 2分钟读懂大数据框架Hadoop和Spark的异同
转自:https://www.cnblogs.com/reed/p/7730313.html 谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生.但我们往往对它们的理解只是 ...
- Java程序员必备的10个大数据框架!
作者:java妞妞 blog.csdn.net/javaniuniu/article/details/71250316 当今IT开发人员面对的最大挑战就是复杂性,硬件越来越复杂,OS越来越复杂,编程语 ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink--容错机制(ACK,RDD,基于log和状态快照),消息处理at least once,exactly once两个是关键
分布式流处理是对无边界数据集进行连续不断的处理.聚合和分析.它跟MapReduce一样是一种通用计算,但我们期望延迟在毫秒或者秒级别.这类系统一般采用有向无环图(DAG). DAG是任务链的图形化表示 ...
随机推荐
- vivo 容器集群监控系统优化之道
作者:vivo 互联网容器团队 - Han Rucheng 本文介绍了vivo容器团队基于 Prometheus等云原生监控生态来构建的容器集群监控体系,在业务接入容器监控的过程中遇到的挑战.困难,并 ...
- Ceph-部署
Ceph规划 主机名 IP地址 角色 配置 ceph_controler 192.168.87.202 控制节点.MGR Centos7系统500G硬盘 ceph_node1 192.168.87.2 ...
- jdk17下netty导致堆内存疯涨原因排查
背景: 介绍 天网风控灵玑系统是基于内存计算实现的高吞吐低延迟在线计算服务,提供滑动或滚动窗口内的count.distinctCout.max.min.avg.sum.std及区间分布类的在线统计计算 ...
- 在 RedHat Enterprise、CentOS 或 Fedora Linux 上安装 MongoDB
在 RedHat Enterprise.CentOS 或 Fedora Linux 上安装 MongoDB 1.大纲 备注:采用yum安装后,所有进程将自动在/usr/bin下,如下的mongo.mo ...
- Eclipse修改Web项目名称
Eclipse修改Web项目名称需要两步: 1:修改该项目目录下:.project文件 <projectDescription><name>SpringMVC-Annotati ...
- 在线PNG, JPG, BMP 转ICO图标,适用WINDOWS XP, VISTA, 7, 8, 10
在线PNG, JPG, BMP 转ICO图标网址: http://static.krpano.tech/image2ico 该网站可以把PNG, JPG和BMP图片转换成包含多个层级的ICO图标, 可 ...
- SpringCloud搭建保姆级教程
一.搭建服务注册与发现中⼼ 使⽤Spring Cloud Netflix 中的 Eureka 搭建服务注册与发现中⼼ 1.创建SpringBoot应用添加依赖 1.spring web 2.eurek ...
- 什么是 CSS?
1.什么是 CSS? CSS 指的是层叠样式表* (Cascading Style Sheets) CSS 描述了如何在屏幕.纸张或其他媒体上显示 HTML 元素 CSS 节省了大量工作.它可以同时控 ...
- 深入理解 Python 虚拟机:协程初探——不过是生成器而已
深入理解 Python 虚拟机:协程初探--不过是生成器而已 在 Python 3.4 Python 引入了一个非常有用的特性--协程,在后续的 Python 版本当中不断的进行优化和改进,引入了新的 ...
- .NET开源简单易用、内置集成化的控制台、支持持久性存储的任务调度框架 - Hangfire
前言 定时任务调度应该是平时业务开发中比较常见的需求,比如说微信文章定时发布.定时更新某一个业务状态.定时删除一些冗余数据等等.今天给推荐一个.NET开源简单易用.内置集成化的控制台.支持持久性存储的 ...