构筑开放式大数据架构,Apache Kyuubi和NDH荣登开源OSCAR

此外,网易数帆发起的云原生开源项目Slime和Curve分别获得了“可信开源社区共同体(TWOS)”和“TWOS 银河计划成员”的授牌。
“OSCAR开源尖峰案例”评选旨在为开源产业发展立标杆、树典范,已开展多年,可谓中国开源领域的奥斯卡,可信开源社区则致力于推动开源社区发展和落地应用。网易数帆获得权威评选的认可,再次证明了公司构建的开放式大数据架构的先进性,及践行“架构开放,内核开源”理念的决心。

Apache Kyuubi:社区成熟,毕业可期
Kyuubi作为一个封装SparkSQL的服务诞生,将多租户、高可用和分布式等企业级特性引入开源大数据的世界,因其实用性受到了社区用户的关注。2021年6月,Kyuubi项目进入Apache软件基金会孵化,并在Apache Way的指引下实现了更快的发展速度。依托本身的架构设计,Apache Kyuubi快速迭代,在Spark之外完成了Flink 、Trino(Presto)、Hive 等主流计算框架的支持,成为一个面向Serverless SQL on Lakehouse的服务,支持更加丰富的大数据场景应用,并被网易、阿里云、腾讯云、小米、华泰证券、广发证券、丁香园、eBay、T3出行、携程、爱奇艺、哔哩哔哩、womply、Houzz、kt NexR等国内外近百家企业采用。

网易数帆的开放式大数据架构中,Apache Kyuubi被视为统一SQL网关,用以屏蔽整个体系中不同存储、计算/查询引擎的差异,为数据中台提供支撑。
Apache Kyuubi的演进得益于社区的成熟,经过不到15个月的孵化,社区已经拥有93位代码贡献者,其中来自网易外部的贡献者占比超过了80%,充分体现了社区驱动的力量。最近,Apache Kyuubi被中国开源软件推进联盟主编的《2022中国开源发展蓝皮书》和InfoQ研究院编撰的《中国开源发展研究分析2022》列为中国开源大数据基础设施的代表。而今,在整个社区坚持不懈的努力下,Kyuubi从Apache基金会毕业可期,成为基金会顶级项目的目标不再遥远。
对于Apache Kyuubi的项目表现和社区发展态势,OSCAR评委专家均给予高度认可。
NDH:我左Spark,右Impala,Kyuubi在上面
作为一款企业级大数据基础平台,网易数帆有数大数据基础平台NDH的核心特点,一是兼容并增强Hadoop体系组件,二是完全自主掌握核心代码,这对于企业从原有大数据平台平滑迁移、满足自主可控要求来说都很重要。更为重要的是,有数大数据基础平台NDH基于最新开源技术打造,在业务支撑能力及性能上有更加出色的表现。
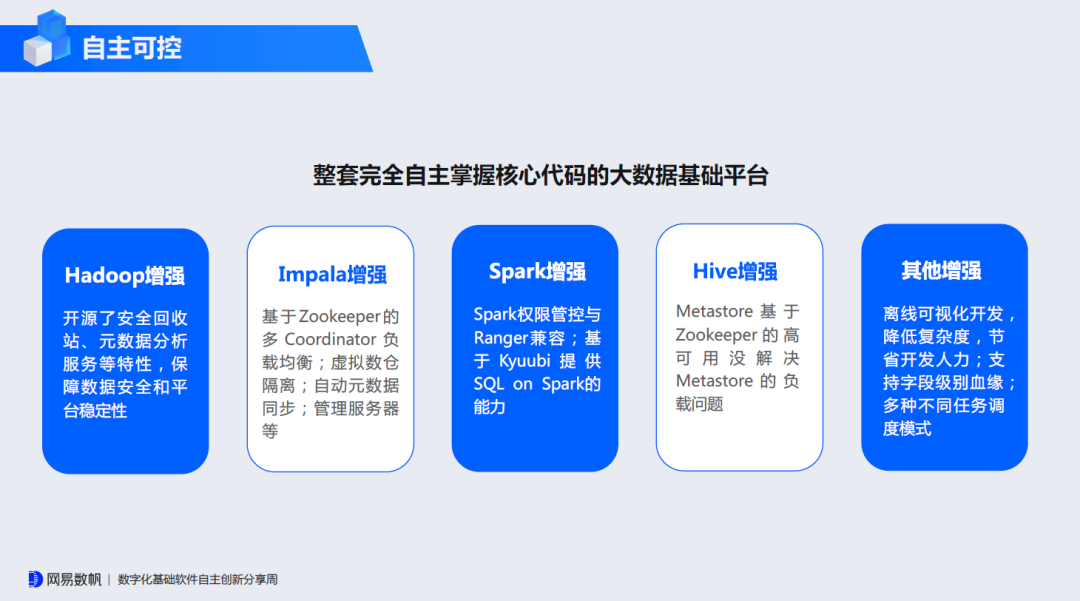
有数大数据基础平台NDH内置多种存储计算引擎,并在Hadoop、Spark、Impala等多个核心组件做了功能及性能增强(例如在Impala上实现虚拟数仓特性),还新增了智能运维和任务治理能力,支持企业级安全管控。这些能力的增强正是大规模生产落地的结晶,获得了评委专家的肯定。
有数大数据基础平台NDH原本作为网易数帆数据中台的底座提供,因市场需求,于今年6月作为单独的产品发布,此举也曾引发业界热议——网易数帆为何进军这门“不好的生意”。然而,这款产品在Impala和Kyuubi方面的积累和优势让从业者印象深刻。目前,有数大数据基础平台NDH已应用于银行、证券、流通、制造等行业三百多家企业客户生产环境。
Slime和Curve:持续完善开源云原生基础设施
Apache Kyuubi和有数大数据基础平台NDH是网易数帆开放式大数据架构的开源项目和商业产品代表,Slime和Curve则是网易数帆开源云原生基础设施的两大支柱,分别填补了服务网格智能管理和国产高性能云原生存储的空白。因其生态定位、架构设计的独特性以及社区发展前景,Slime社区和Curve社区分别受邀成为可信开源社区共同体(TWOS)成员和TWOS 银河计划成员,针对项目质量、社区发展、商业模式等话题加强开源社区之间的交流协作,不仅完善开源云原生基础设施生态,也助推国内开源产业健康、快速发展。
未来,网易数帆将继续秉承开放式思维拥抱开源,以扎实的产品实力和先进的技术实力为后盾,团结社区合作伙伴,持续为开源生态建设贡献力量。

构筑开放式大数据架构,Apache Kyuubi和NDH荣登开源OSCAR的更多相关文章
- 大数据架构-使用HBase和Solr将存储与索引放在不同的机器上
大数据架构-使用HBase和Solr将存储与索引放在不同的机器上 摘要:HBase可以通过协处理器Coprocessor的方式向Solr发出请求,Solr对于接收到的数据可以做相关的同步:增.删.改索 ...
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
- 后Hadoop时代的大数据架构
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本.我把2012年后定义成后Hadoop平台时代,这不是说不 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 大数据架构师必读的NoSQL建模技术
大数据架构师必读的NoSQL建模技术 从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术. 1.前言 为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- 决战大数据之三-Apache ZooKeeper Standalone及复制模式安装及测试
决战大数据之三-Apache ZooKeeper Standalone及复制模式安装及测试 [TOC] Apache ZooKeeper 单机模式安装 创建hadoop用户&赋予sudo权限, ...
- WOT干货大放送:大数据架构发展趋势及探索实践分享
WOT大数据处理技术分会场,PingCAP CTO黄东旭.易观智库CTO郭炜.Mob开发者服务平台技术副总监林荣波.宜信技术研发中心高级架构师王东及商助科技(99Click)顾问总监郑泉五位讲师, ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
随机推荐
- yum install --downloadonly
yum install --downloadonly --downloaddir=[directory] [package] https://www.cnblogs.com/wangbaobao/p/ ...
- EDP .Net开发框架--组织架构
职类 职类是将职务进行分类管理,并定义了职类标记和职级.职类标记会带入到该职类下的职务作为职务的标记,并为职务提供职级范围选择. "高管类"职类定义了其职级范围为"PM1 ...
- 胃食管反流之 SAP分析( in the Ohmega software)
原文:https://note.youdao.com/s/GED6wise SAP analysis in the Ohmega software ohmega software 关于胃食管反流疾病 ...
- winform cefsharp chart.js 再winform上使用chart.js 绘制动态曲线
CefSharp 是一款开源的使用.net平台基于谷歌的 封装浏览器组件,可用于winform wpf . chart.js 也是一款开源的图表展示组件. 我所作的就是使用这两个组件再winform上 ...
- VMware Workstation安装Ubuntu窗口太小的解决方式
1.选择菜单中的:虚拟机--------安装VMware-Tools 2.点击DVD图标 3.将压缩文件复制到桌面 4.解压压缩文件 5.进入解压后的目录,执行命令: sudo perl vmware ...
- Android 13 - Media框架(13)- OpenMax(一)
关注公众号免费阅读全文,进入音视频开发技术分享群! 这一节我们将了解Android OpenMax框架,该框架了解完成之后,我们会再回过头去了解 ACodec,将 MediaCodec - ACode ...
- js 生成pdf
最简洁的代码 <script src="js/html2canvas.min.js" type="text/javascript" charset=&qu ...
- sort awk 文本处理命令
sort: 1.将文件的每一行作为一个单位,相互比较 2.默认升序 3.以字符来进行对比,从首字符开始往后,依次按ASCII码值排序 sort 显示文件内容 (类似cat) 选项: -u 去掉重复行 ...
- testArticle
Test Article This is a test article for ArticleSync. Test Edit...... test Edit
- QEMU EDU设备模拟PCI设备驱动编写
环境安装 buildroot编译 buildroot下载,编译: 下载地址:Index of /downloads (buildroot.org) 下载版本:https://www.buildroot ...