strimzi实战之二:部署和消息功能初体验
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 本篇是《strimzi实战》系列的第二篇,前文完成了介绍和准备工作,是时候体验strimzi的核心功能了:发送和接受kafka消息,为了完成这个目标,本篇会按照如下步骤开始实战:
- 在kubernetes环境部署strimzi,这里面包含两个步骤:首先是将各类资源创建好,然后再启动strmzi
- 验证基本功能:发送和接受kafka消息,这里面有两种操作(注意,是两种里面二选一,不是两步):如果您的kubernetes环境有pv,就可以选择使用pv的操作步骤,如果您没有pv,就选择不用pv的操作步骤
- 删除操作
- 接下来开始实战
部署
- 创建namespace
kubectl create namespace kafka
- 部署角色、权限、CRD等资源
kubectl create -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafka
启动
- 接下来的启动操作,根据您的实际情况,有两种可选
- 第一种:如果您的k8s环境已经准备好了pv,请执行以下命令完成部署,strimzi会通过pvc去申请使用pv,这样就算pod有问题被删除重建了,kafka消息的数据也不会丢失
kubectl apply -f https://strimzi.io/examples/latest/kafka/kafka-persistent-single.yaml -n kafka
- 第二种,如果您的k8s环境还没有准备好pv,请执行以下命令完成部署,这样创建的kafka服务也能正常使用,只不过所有数据都存在pod中,一旦pod被删除,数据就找不回来了
kubectl apply -f https://strimzi.io/examples/latest/kafka/kafka-ephemeral-single.yaml -n kafka
- 以上两种方式只要选择一种去执行即可,执行完命令后,需要等待镜像下载和服务创建,尤其是镜像下载,实测真的慢啊,我用腾讯云服务器大约等了七八分钟
[root@VM-12-12-centos ~]# kubectl get pod -n kafka
NAME READY STATUS RESTARTS AGE
strimzi-cluster-operator-566948f58c-h2t6g 0/1 ContainerCreating 0 16m
- 等到operator的pod运行起来后,就该创建zookeeper的pod了,继续等镜像下载...
[root@VM-12-12-centos ~]# kubectl get pods -n kafka
NAME READY STATUS RESTARTS AGE
my-cluster-zookeeper-0 0/1 ContainerCreating 0 7m59s
my-cluster-zookeeper-1 0/1 ContainerCreating 0 7m59s
my-cluster-zookeeper-2 0/1 ContainerCreating 0 7m59s
strimzi-cluster-operator-566948f58c-h2t6g 1/1 Running 0 24m
- 如下图红色箭头所指,显示正在拉取zookeeper镜像

- 等到zookeeper的pod创建完成后,终于轮到主角登场了:开始kafka的pod创建,最后,来个全家福,如下所示,一套具备基本功能的kafka环境
[root@VM-12-12-centos ~]# kubectl get pods -n kafka
NAME READY STATUS RESTARTS AGE
my-cluster-entity-operator-66598599fc-sskcx 3/3 Running 0 73s
my-cluster-kafka-0 1/1 Running 0 96s
my-cluster-zookeeper-0 1/1 Running 0 14m
my-cluster-zookeeper-1 1/1 Running 0 14m
my-cluster-zookeeper-2 1/1 Running 0 14m
strimzi-cluster-operator-566948f58c-h2t6g 1/1 Running 0 30m
基本操作:收发消息
- strimzi部署已经OK,现在收发消息试试,看kafka基本功能是否正常
- 接下来的操作需要两个控制台窗口,一个用于发消息,一个用于收消息
- 在发消息的窗口输入以下命令,就会创建名为my-topic的topic,并且进入发送消息的模式
kubectl -n kafka \
run kafka-producer \
-ti \
--image=quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 \
--rm=true \
--restart=Never \
-- bin/kafka-console-producer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic
- 在收消息的窗口输入以下命令,就会进入消费消息的模式,topic是my-topic
kubectl -n kafka \
run kafka-consumer \
-ti \
--image=quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 \
--rm=true \
--restart=Never \
-- bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic --from-beginning
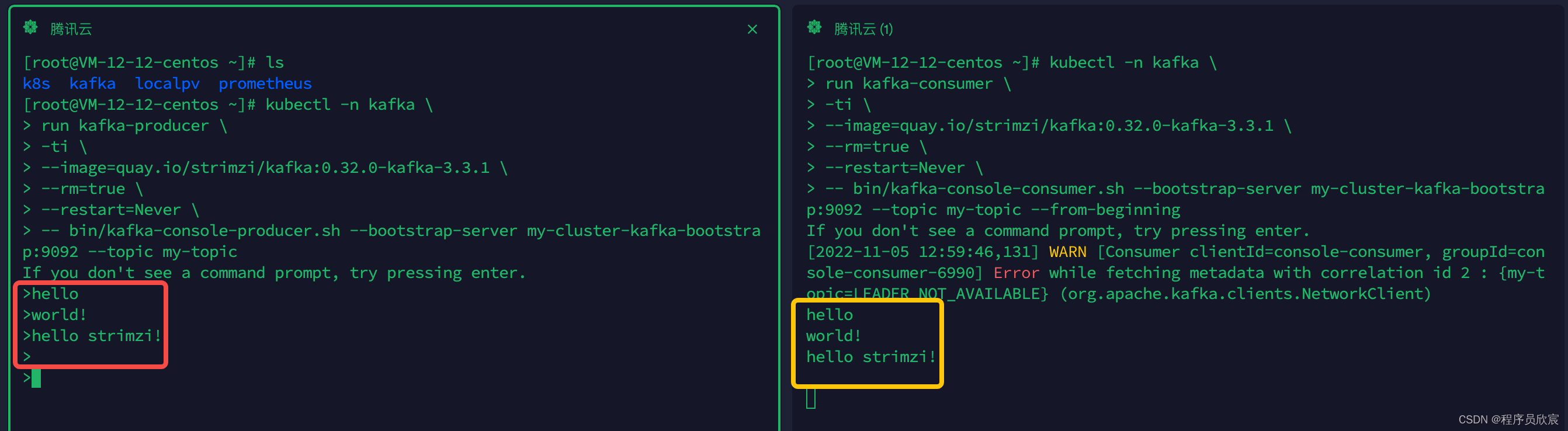
然后,在发送消息的窗口输入一些文字后再回车,消息就会发送出去,如下图,左侧红框显示一共发送了四次消息,最后一次是空字符串,右侧黄框显示成功收到四条消息
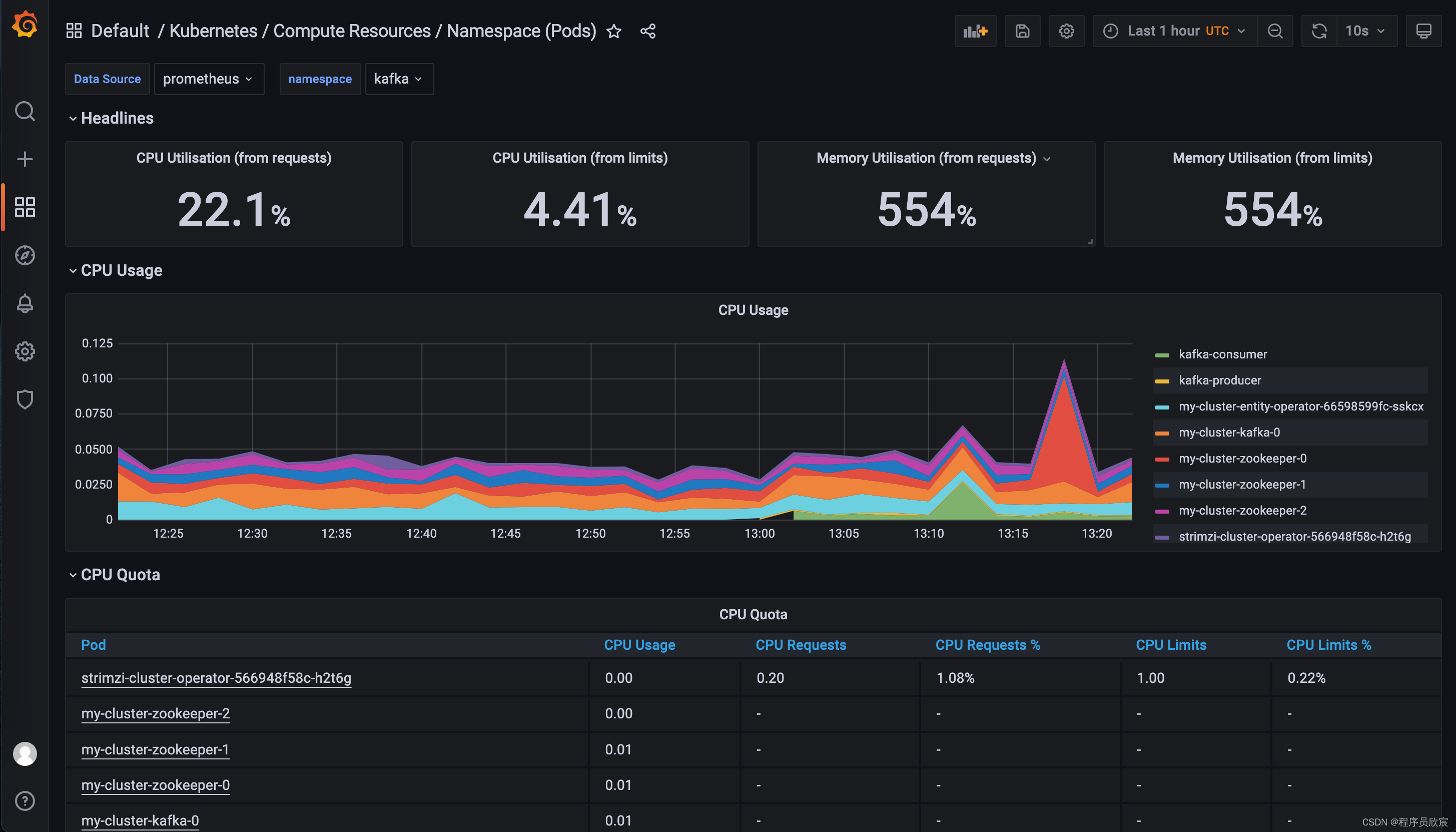
如果您的kubernetes环境是按照《快速搭建云原生开发环境(k8s+pv+prometheus+grafana)》的方法来部署的,现在就能通过grafana看到命名空间kafka下面的资源了,如下图
另外,如果您使用了pv,还可以关注一下pv的使用情况,如下图,kafka的zookeeper的数据都改为外部存储了,数据不会因为pod问题而丢失

不过由于我们还没有将strimzi的监控配置好,现在还看不到kafka业务相关的指标情况,只能从k8s维度去查看pod的基本指标,这些会在后面的章节补齐
删除操作
- 如果需要把strimzi从kubernetes环境删除,执行以下操作即可:
- 如果您使用了pv,就执行以下命令完成删除
kubectl delete -f https://strimzi.io/examples/latest/kafka/kafka-persistent-single.yaml -n kafka \
&& kubectl delete -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafka \
&& kubectl delete namespace kafka
- 如果您没有使用pv,就执行以下命令完成删除
kubectl delete -f https://strimzi.io/examples/latest/kafka/kafka-ephemeral-single.yaml -n kafka \
&& kubectl delete -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafka \
&& kubectl delete namespace kafka
- 再去检查所有pod,已看不到strimzi的痕迹
[root@VM-12-12-centos ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
calico-apiserver calico-apiserver-67b7856948-bg2wh 1/1 Running 0 6d2h
calico-apiserver calico-apiserver-67b7856948-fz64n 1/1 Running 0 6d2h
calico-system calico-kube-controllers-78687bb75f-z2r7m 1/1 Running 0 6d2h
calico-system calico-node-l6nmw 1/1 Running 0 6d2h
calico-system calico-typha-b46ff96f6-qqzxb 1/1 Running 0 6d2h
calico-system csi-node-driver-lv2g2 2/2 Running 0 6d2h
kafka my-cluster-entity-operator-66598599fc-fz7wx 3/3 Running 0 4m57s
kafka my-cluster-kafka-0 1/1 Running 0 5m22s
kafka my-cluster-zookeeper-0 1/1 Running 0 5m48s
kafka strimzi-cluster-operator-566948f58c-pj45s 1/1 Running 0 6m15s
kube-system coredns-78fcd69978-57r7x 1/1 Running 0 6d2h
kube-system coredns-78fcd69978-psjcs 1/1 Running 0 6d2h
kube-system etcd-vm-12-12-centos 1/1 Running 0 6d2h
kube-system kube-apiserver-vm-12-12-centos 1/1 Running 0 6d2h
kube-system kube-controller-manager-vm-12-12-centos 1/1 Running 0 6d2h
kube-system kube-proxy-x8nhg 1/1 Running 0 6d2h
kube-system kube-scheduler-vm-12-12-centos 1/1 Running 0 6d2h
local-path-storage local-path-provisioner-55d894cf7f-mpd2n 1/1 Running 0 3d21h
monitoring alertmanager-main-0 2/2 Running 0 24h
monitoring alertmanager-main-1 2/2 Running 0 24h
monitoring alertmanager-main-2 2/2 Running 0 24h
monitoring blackbox-exporter-6798fb5bb4-4hmf7 3/3 Running 0 24h
monitoring grafana-d9c6954b-qts2s 1/1 Running 0 24h
monitoring kube-state-metrics-5fcb7d6fcb-szmh9 3/3 Running 0 24h
monitoring node-exporter-4fhb6 2/2 Running 0 24h
monitoring prometheus-adapter-7dc46dd46d-245d7 1/1 Running 0 24h
monitoring prometheus-adapter-7dc46dd46d-sxcn2 1/1 Running 0 24h
monitoring prometheus-k8s-0 2/2 Running 0 24h
monitoring prometheus-k8s-1 2/2 Running 0 24h
monitoring prometheus-operator-7ddc6877d5-d76wk 2/2 Running 0 24h
tigera-operator tigera-operator-6f669b6c4f-t8t9h 1/1 Running 0 6d2h
- 不过,对于pv来说,由于使用的策略是Retain,因此还会继续存在

- 至此,strimzi基本功能实战已经完成,咱们知道了如何快速部署strimzi和收发消息,感受到operator给我们带来的便利,接下来的文章,还会有更多简单的操作,更多精彩的功能等着咱们去尝试,欢迎您继续关注欣宸原创,咱们一起学习共同进步
欢迎关注博客园:程序员欣宸
strimzi实战之二:部署和消息功能初体验的更多相关文章
- 阿里云部署Java web项目初体验(转)
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 摘要:本文主要讲了如何在阿里云上安装JDK.Tomcat以及其配置过程.最后以一个实例来演示在 ...
- 阿里云部署Java web项目初体验(转)/linux 上配置jdk和安装tomcat
摘要:本文主要讲了如何在阿里云上安装JDK.Tomcat以及其配置过程.最后以一个实例来演示在阿里云上部署Java web项目. 一.准备工作 购买了阿里云的云解析,和云服务器ecs. 2.下载put ...
- 阿里云部署Java web项目初体验
林炳文Evankaka原创作品. 转载请注明出处http://blog.csdn.net/evankaka 摘要:本文主要讲了怎样在阿里云上安装JDK.Tomcat以及其配置过程. 最后以一个实例来演 ...
- .NET gRPC 核心功能初体验,附Demo源码
gRPC是高性能的RPC框架, 有效地用于服务通信(不管是数据中心内部还是跨数据中心). 由Google开源,目前是一个Cloud Native Computing Foundation(CNCF)孵 ...
- Java进阶专题(二十八) Service Mesh初体验
前言 ⽬前,微服务的架构⽅式在企业中得到了极⼤的发展,主要原因是其解决了传统的单体架构中存在的问题.当单体架构拆分成微服务架构就可以⾼枕⽆忧了吗? 显然不是的.微服务架构体系中同样也存在很多的挑战 ...
- php消息队列之 think queue消息队列初体验
使用thinkphp 5的 消息队列 think queue ● php think queue:listen --queue queuename ● php think queue:work -- ...
- think queue 消息队列初体验
使用的是tp5 自带的消息队列 thinkphp top里的 消息队列框架 think-queue 这是thinkphp官方团队开发的一个专门支持队列服务的扩展包 消息队列应用场景: 消息队列适用于 ...
- DubboSPI机制二之Dubbo中SPI初体验
Dubbo高级之一SPI机制之JDK中的SPI - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中阐述了JDK标准的SPI,并对其应用做了相应的实践.在实际应用中,很多框架都会对其进行扩展 ...
- EMQ消息队列初体验
使用命令创建admin用户,密码123 emqx_ctl users add admin 配置规则/etc/emqx/acl.conf(除管理员,其他用户只能订阅限定的测试主题路径) %% 允许'ad ...
- 二 APPIUM Android自动化 测试初体验
本文转自:http://www.cnblogs.com/sundalian/p/5629358.html 1.创建一个maven项目 成功新建工程: 编辑pom.xml,在<dependenci ...
随机推荐
- 【技术积累】Python中的Pandas库【二】
如何在 Pandas 中进行文本的匹配和替换操作? 在 Pandas 中,使用 str 属性与正则表达式可以进行文本的匹配和替换操作.下面是一些常用的方法: str.contains():判断字符串中 ...
- 五年磨一剑——Sealos 云操作系统正式发布!
这是个宏伟的计划 这是一个宏伟的计划,漫长且有趣. 2018 年的某个夜晚,夜深人静,我挥舞键盘,敲下了 Sealos 的第一行代码.当时仓库命名为 "kubeinit",后来觉得 ...
- 【电脑Tips】Win11自动更新之后开机黑屏
目录 0.问题描述 1. 释放静电 具体操作 效果 参考博客 2. 运行explorer.exe 具体操作: [问题]:如何打开任务管理器? 效果 参考博客 另外的运行方法 3. 禁用APP Read ...
- Java发展历程及各版本新特性
Java的历史是非常有意思的.1990年底,Sun Microsystems在工作站计算机市场上领先世界,并继续保持健康发展.Sun想把本公司的创新和专业知识应用到即将到来的消费电子市场领域,于是该公 ...
- SLF4J门面日志框架源码探索
1 SLF4J介绍 SLF4J即Simple Logging Facade for Java,它提供了Java中所有日志框架的简单外观或抽象.因此,它使用户能够使用单个依赖项处理任何日志框架,例如:L ...
- vue前端预览pdf并加水印、ofd文件,控制打印、下载、另存,vue-pdf的使用方法以及在开发中所踩过的坑合集
根据公司的实际项目需求,要求实现对pdf和ofd文件的预览,并且需要限制用户是否可以下载.打印.另存pdf.ofd文件,如果该用户可以打印.下载需要控制每个用户的下载次数以及可打印的次数.正常的预览p ...
- Vue3从入门到精通(三)
vue3插槽Slots 在 Vue3 中,插槽(Slots)的使用方式与 Vue2 中基本相同,但有一些细微的差异.以下是在 Vue3 中使用插槽的示例: // ChildComponent.vue ...
- APP中Web容器的核心实现
现在的业务型APP中,采用纯原生开发策略的已经很少了,大部分都使用的混合开发.如原生,H5,ReactNative,Flutter,Weex它们之间任意的组合就构成了混合开发. 其中原生+H5是出 ...
- P2709 小B的询问题解
本题需要用到莫队算法 关于莫队算法 莫队算法是一种离线算法,适用于序列中统计区间特定的目标的问题. 时间复杂度通常是 \(O(n \sqrt n)\) 或更高. P2709 小B的询问 点击查看原题 ...
- 2023-07-13:如果你熟悉 Shell 编程,那么一定了解过花括号展开,它可以用来生成任意字符串。 花括号展开的表达式可以看作一个由 花括号、逗号 和 小写英文字母 组成的字符串 定义下面几条语
2023-07-13:如果你熟悉 Shell 编程,那么一定了解过花括号展开,它可以用来生成任意字符串. 花括号展开的表达式可以看作一个由 花括号.逗号 和 小写英文字母 组成的字符串 定义下面几条语 ...