HiAI Foundation助力端侧音视频AI能力,高性能低功耗释放云侧成本
过去三年是端侧AI高速发展的几年,华为在2020年预言了端侧AI的发展潮流,2021年通过提供端云协同的方式使我们的HiAI Foundation应用性更进一个台阶,2022年提供视频超分端到端的解决方案,在2023HDC大会上,HiAI Foundation基于硬件能力的开放,提供更多场景高效能的解决方案。
华为HiAI Foundation提供了高性能AI算子和丰富的AI特性的接口,App直接对应HiAI Foundation的DDK。今年完整支持了HarmonyOS NEXT,开发者无需修改任何代码,只需按照HarmonyOS NEXT的要求重新编译即可运行。同时,在开发者联盟网站有HarmonyOS NEXT指导文档,在Gitee上也开源了对应的Demo,降低大家的集成成本。
今年,华为在原有的基础上,拓展了更多端侧AI场景解决方案。

华为HiAI Foundation是基于硬件创新架构的能力开放,构建了一个高性能的NPU、CPU、GPU算子,同时提供整网融合、AIPP硬化预处理、算子搜索工具、异构计算等多元的基础能力,在硬件创新架构和多元竞争基础的能力上,提供生态开放机制,在生态开放机制上提供对用户开放的接口DDK工具链、模型轻量化、算子库动态升级、开源等等机制。

华为HiAI Foundation主要由以下几个部分构成,首先是HiAI Foundation DDK推理加速平台,它主要完成与上层推理框架的接入,使开发者可以屏蔽底层硬件,能够更加聚焦于模型效果的优化。第二部分是异构计算HCL平台,它主要是使能各个硬件,比如NPU、CPU、GPU。第三部分是提供对应的工具链,包括模型转换工具链、异构调优工具链。同时我们也提供了统一的API,通过一次开发可以做到赋能多形态的设备硬件上运行,并且华为HiAI Foundation可以与HarmonyOS实时融合。

下面以典型AI场景为例,从部署的角度来探索一下华为HiAI Foundation是如何完成这些挑战,并最终实现这些场景的落地。
视觉类加速方案人像分割
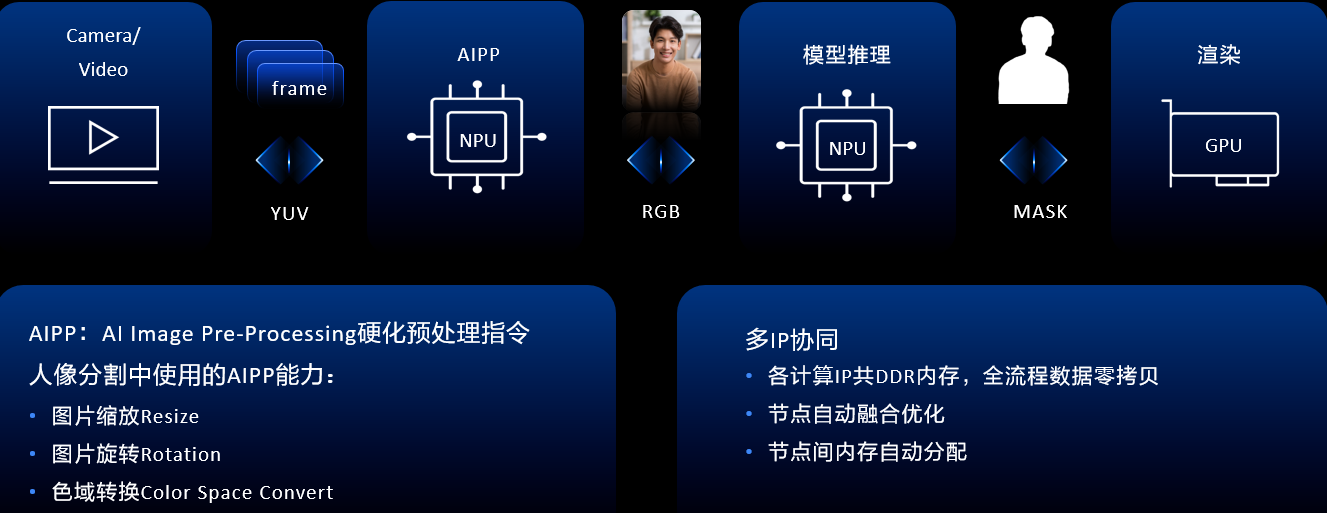
我们知道人像分割通常用于视频中的背景替换、长短视频的弹幕穿人玩法等。华为HiAI Foundation通过人像分割,通过AIPP硬化预处理指令、模型量化,使得人像分割达到性能和功耗的业务要求。从视频解码和开通预览流到AIPP推理和GPU渲染,有多个过程参与,华为HiAI Foundation不仅要进行推理,还要完成上下游的深度协同。


视频流和开放预览帧到模型,以人像分割为例,人像分割要求的输入是RGB格式,并且输入要求是固定的尺寸,视频解码帧和预览流出来的数据,要求支持图像预处理的指令,并且把它硬化到NPU里面,所以人像分割提供了包括图片缩放resize、图片旋转rotation、色域转换color space convert的能力。基于华为实验室测试结果,实现性能提升20%,模型大小缩小75%,精度损失1%以内,性能提升19%。
第二部分是模型在NPU上的高效算子推理,推理结束之后将结果送到GPU上做渲染。在传统方案中,NPU和GPU通常是操作两块不同的内存,华为HiAI Foundation提供了零拷贝的接口,将NPU和GPU在同一块内存上操作,并且在格式上保持严格一致,通过多IP协同+AIPP实现高效人像分割计算。
在端侧部署过程中提供了模型可视化+Profiling工具,通过模型可视化了解HiAI Foundation结构,通过Profiling知道IP的分布,包括算子在NPU和GPU的推理时间,综合起来通过可视化工具和Profiling工具设计出系统友好的结构,设计性能最佳的模型。
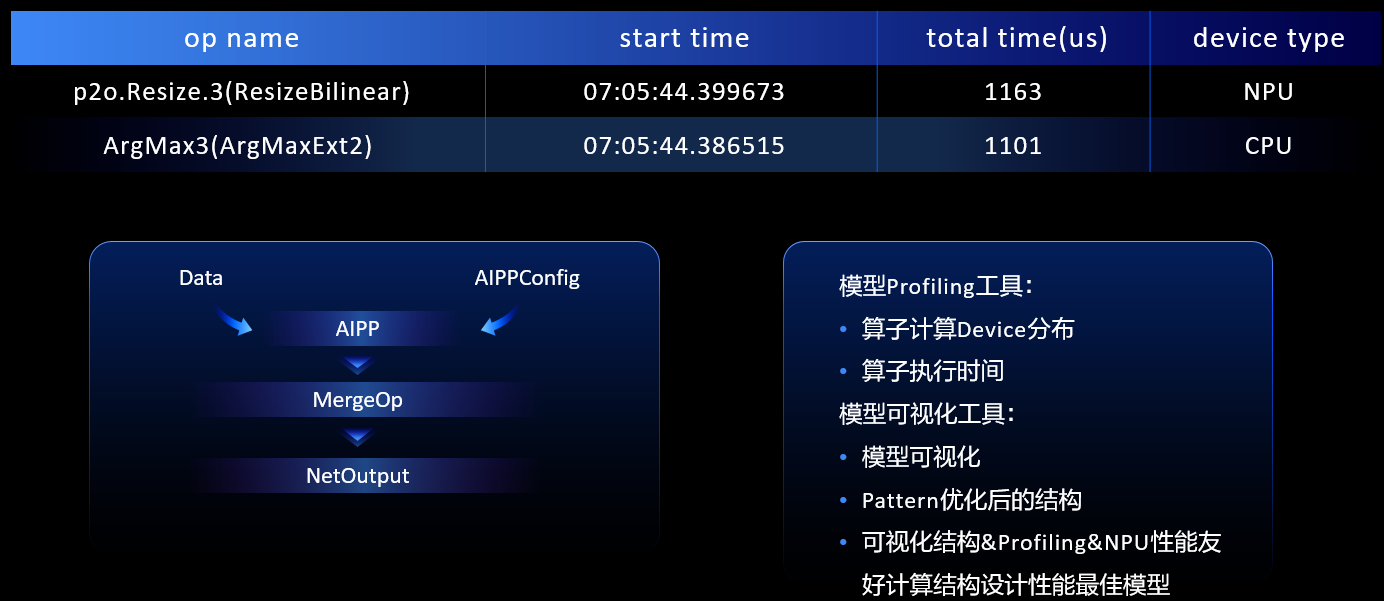
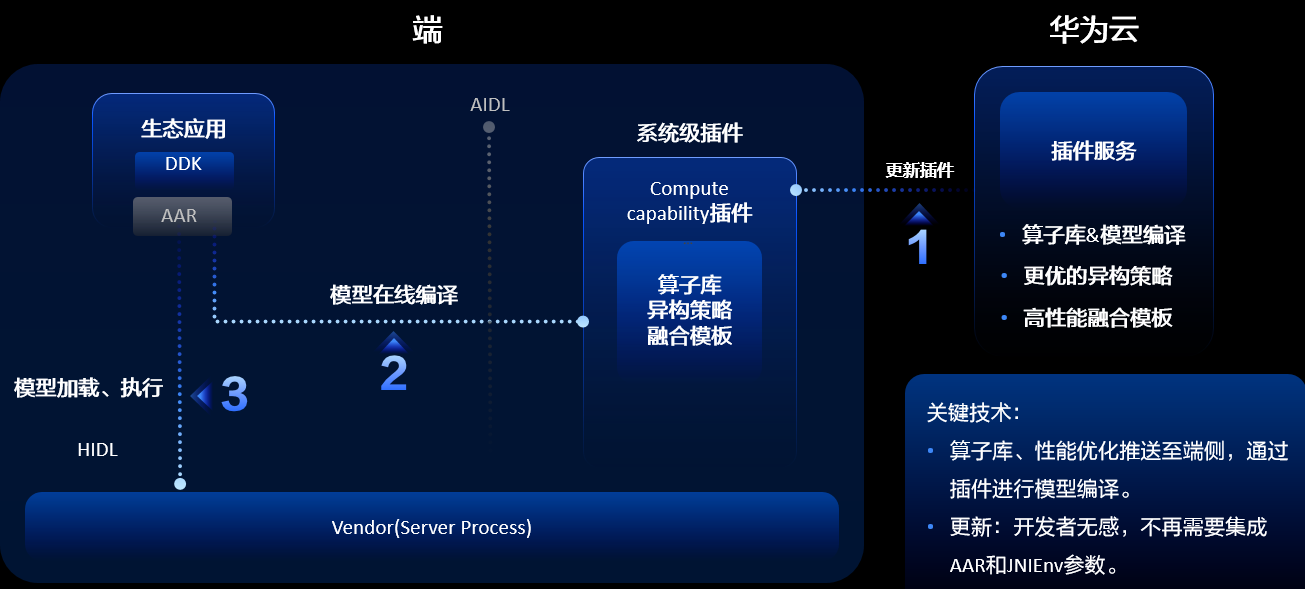
通过Profiling工具了解到模型算子的性能不够友好,然后把它反馈到HiAI Foundation,我们在支持好这些算子之后,通过端云协同的方式快速推送到用户手中,使用户能够尽快上线业务。本次华为在端云协同助力性能优化快速升级方面做了全面的升级,开发者无SDK就可以集成,相比原来繁琐的集成要求,可以做到无感集成。
语音类的加速方案语音识别
端侧部署语音识别实时出字、响应快,在端侧执行可以保证用户的隐私,此外华为能做到在NPU上执行,稳定性高,并且可以降低云侧的资源部署成本。在语音识别这一块,HiAI Foundation支持的是端到端的Transformer模型,全部在云端推理。基于华为实验室测试结果,模型量化模型大小缩小74%,精度损失1%以内。
模型如图所示,支持Transformer模型,开发者可以根据自身的业务,根据性能和泛化性来进行定制,也可以实现高效的算子融合。
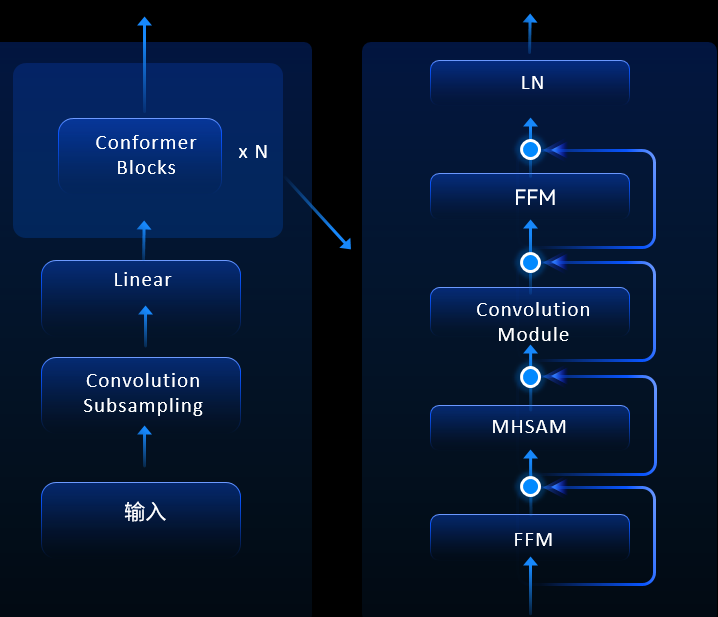
将原来需要频繁和内存交互的指令融合成一个大的算子,通过对这些关键结构进行算子融合,总共带来了60%的功耗收益,将左边很多小算子组成的结构融合成一个大算子,避免这些小算子频繁和内存进行交互,从而提升了运算效率。

在端侧部署的过程中,存储空间也是开发者们关注的问题,希望用更小的存储空间来实现更多更强的能力,所以华为提供量化工具链,通过量化工具链可以量化出更小巧、更灵活的模型。以人像分割和语音识别为例,基于华为实验室测试结果,它们的存储大小能够相比32位浮点减少70%以上,精度WER指标相比32浮点小于1%,相应的功率也有一定的提升。

在端侧AI部署中会涉及到硬件、软件和AI算法,所以华为通过开源的方式来加速业务,通过更多方式灵活部署。目前开放了推理源码的开源,通过开源可以做到和App、第三方深度学习框架对接,同时可以基于自身的需求做灵活的定制裁剪,做到开发灵活,通过这些开源平台能和开发者沟通更便捷。通过这些开源,开发者可以快速下载、编译,即可在华为手机上用NPU做推理,更高效集成业务。
未来,华为会探索Transformer模型更加泛化、更高能效的场景化解决方案,同时在端云协同上也会探索更多更高性能场景的能力支持,也会通过ModelZoo提供更多场景NPU友好的模型结构,用户可以设计更加NPU友好的模型结构。
了解更多详情>>
关注我们,第一时间了解 HMS Core 最新技术资讯~
HiAI Foundation助力端侧音视频AI能力,高性能低功耗释放云侧成本的更多相关文章
- 视频云肖长杰:视频AI科技助力短视频生态
人工智能技术是当今炙手可热的技术领域,它在制造.家居.零售.交通.安防等行业的应用已经是大势所趋.在本月云栖Techday音视频技术沙龙中,阿里云视频云产品专家肖长杰为我们分享了一些AI技术在视频中应 ...
- 如何做好 Android 端音视频测试?
在用户眼中,优秀的音视频产品应该具有清晰.低延时.流畅.秒开.抗丢包.高音效等特征.为了满足用户以上要求,网易云信的工程师通过自建源站,在SDK端为了适应网络优化进行QoS优化,对视频编码器进行优化, ...
- 融云携新版实时音视频亮相 LiveVideoStack 2019
4 月 19 日,LiveVideoStack 2019 音视频大会在上海隆重开幕,全球多媒体创新专家.音视频技术工程师.产品负责人.高端行业用户等共襄盛会,聚焦音频.视频.图像.AI 等技术的最新探 ...
- 腾讯技术分享:微信小程序音视频与WebRTC互通的技术思路和实践
1.概述 本文来自腾讯视频云终端技术总监rexchang(常青)技术分享,内容分别介绍了微信小程序视音视频和WebRTC的技术特征.差异等,并针对两者的技术差异分享和总结了微信小程序视音视频和WebR ...
- 腾讯技术分享:微信小程序音视频技术背后的故事
1.引言 微信小程序自2017年1月9日正式对外公布以来,越来越受到关注和重视,小程序上的各种技术体验也越来越丰富.而音视频作为高速移动网络时代下增长最快的应用形式之一,在微信小程序中也当然不能错过. ...
- 了不起的WebRTC:生态日趋完善,或将实时音视频技术白菜化
本文原文由声网WebRTC技术专家毛玉杰分享. 1.前言 有人说 2017 年是 WebRTC 的转折之年,2018 年将是 WebRTC 的爆发之年,这并非没有根据.就在去年(2017年),WebR ...
- 深圳云栖大会人工智能专场:探索视频+AI,玩转智能视频应用
摘要: 在人工智能时代,AI技术是如何在各行业和领域真正的发挥应用和商业价值,带来产业变革才是关键.在3月28日深圳云栖大会的人工智能专场中,阿里云视频服务技术专家邹娟将带领大家探索熟悉的视频场景中, ...
- [转帖]AVS音视频编解码技术了解
AVS高清立体视频编码器 电视技术在经历了从黑白到彩色.从模拟到数字的技术变革之后正在酝酿另一场技术革命,从单纯观看二维场景的平面电视跨越到展现三维场景的立体电视3DTV.3DTV系统的核心问题之一是 ...
- Android 音视频采集那些事
音视频采集 在整个音视频处理的过程中,位于发送端的音视频采集工作无疑是整个音视频链路的开始.在 Android 或者 IOS 上都有相关的硬件设备--Camera 和麦克风作为输入源.本章我们来分析如 ...
- 云-腾讯云-实时音视频:实时音视频(TRTC)
ylbtech-云-腾讯云-实时音视频:实时音视频(TRTC) 支持跨终端.全平台之间互通,从零开始快速搭建实时音视频通信平台 1.返回顶部 1. 腾讯实时音视频(Tencent Real-Time ...
随机推荐
- cv学习总结(11.6-11.13)
两层全连接神经网络的内容要比想象中的多很多,代码量也很多,在cs231n只用了15分钟讲解的东西我用了一周半的时间才完全的消化理解,这周终于完成了全连接神经网络博客的书写https://www.cnb ...
- 【QCustomPlot】性能提升之修改源码(版本 V2.x.x)
说明 使用 QCustomPlot 绘图库的过程中,有时候觉得原生的功能不太够用,比如它没有曲线平滑功能:有时候又觉得更新绘图数据时逐个赋值效率太低,如果能直接操作内存就好了:还有时候希望减轻 CPU ...
- Windows/Linux 下功能强大的桌面截图软件
说到桌面截图软件,很多人首先想到的是 QQ 自带的截图,或者更高级功能更强大的 Snipaste 截图工具. 独立版本的 QQ 截图至少我目前没找到官方正式的下载链接,默认需要安装和打开 QQ 才能使 ...
- 基于uniapp+vite4+vue3搭建跨端项目|uni-app+uview-plus模板
最近得空学习了下uniapp结合vue3搭建跨端项目.之前也有使用uniapp开发过几款聊天/仿抖音/后台管理等项目,但都是基于vue2开发.随着vite.js破局出圈,越来越多的项目偏向于vue3开 ...
- 解决Mysql 5.7 不能插入中文的问题
问题的解决方案 问题描述 : 在学习DML插入中文数据时 , 发现出现了以下问题 -- 插入数据 insert into tea (id , name) values (2 , '徐凤年'); -- ...
- JavaCV人脸识别三部曲之三:识别和预览
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos <JavaCV人脸识别三部曲>链接 < ...
- 解决 Windows 环境下 conda 切换 Python 版本报错 NoWritablePkgsDirError: No writeable pkgs directories configured.
1. 起因 今天运行一个 flask 项目,报错:AttributeError: module 'time' has no attribute 'clock' 一查才发现,Python3.8 不再支持 ...
- 4.10 x64dbg 反汇编功能的封装
LyScript 插件提供的反汇编系列函数虽然能够实现基本的反汇编功能,但在实际使用中,可能会遇到一些更为复杂的需求,此时就需要根据自身需要进行二次开发,以实现更加高级的功能.本章将继续深入探索反汇编 ...
- UI自动化打开游览器失败 elenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 90
原因是: 驱动和当前游览器版本不一致 查看游览器版本: 下载对应驱动: http://npm.taobao.org/mirrors/chromedriver/ 在自己电脑上 找到原来驱动的存放位置 将 ...
- load initialize总结
load initialize 方法的区别1.调用的方式 - load 根据函数地址调用 - initialize 通过objc_msgsend调用 2.调用时刻 - load runtime 加载类 ...