ES 分词器简单应用
本文为博主原创,未经允许不得转载:
1. ES 分词器
1.1 elasticsearch 默认分词器: standard
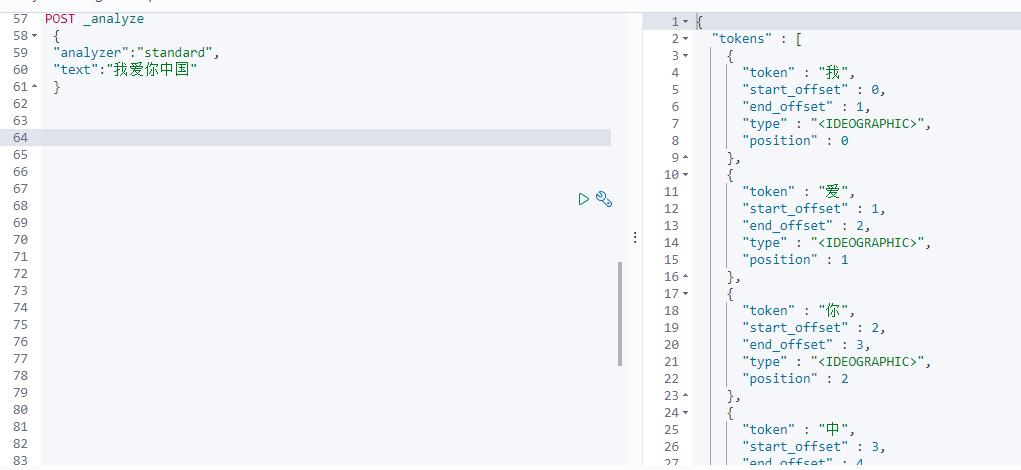
standard 分词器会将每个英文单词及每个汉字进行单独拆分进行索引
使用示例:
POST _analyze
{
"analyzer":"standard",
"text":"我爱你中国"
}
2. ik 中文分词器
ik 中文分词器会根据具体的语义进行拆分,比如南京市,如果使用standard 分词设置,则会形成 南,京, 市三个索引,明显不合理,使用 ik 中文分词器,则会拆分成 南京市进行索引。ik 中文分词器有两种模式: ik_smart和ik_max_word 。 ik_smart 智能化拆分:比如清华大学,则会拆分为 清华大学,而 ik_max_word 则会拆分为清华大学,清华,大学等索引。
POST _analyze
{
"analyzer": "ik_smart",
"text": "江苏省南京市江宁区"
} POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市"
}
修改索引的默认分词方法:
PUT /test_es_db
{
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
ES 分词器简单应用的更多相关文章
- es分词器
1.默认的分词器 standard standard tokenizer:以单词边界进行切分standard token filter:什么都不做lowercase token filter:将所有字 ...
- es 分词器介绍
按照单词切分,不做处理 GET _analyze { "analyzer": "standard", "text": "2 run ...
- ElasticSearch 分词器,了解一下
这篇文章主要来介绍下什么是 Analysis ,什么是分词器,以及 ElasticSearch 自带的分词器是怎么工作的,最后会介绍下中文分词是怎么做的. 首先来说下什么是 Analysis: 什么是 ...
- Elasticsearch简介、倒排索引、文档基本操作、分词器
lucene.Solr.Elasticsearch 1.倒排序索引 2.Lucene是类库 3.solr基于lucene 4.ES基于lucene 一.Elasticsearch 核心术语 特点: 1 ...
- Lucene5学习之使用MMSeg4j分词器
分类:程序语言|标签:C|日期: 2015-05-01 02:00:24 MMSeg4j是一款中文分词器,详细介绍如下: 1.mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法( ...
- es 修改拼音分词器源码实现汉字/拼音/简拼混合搜索时同音字不匹配
[版权声明]:本文章由danvid发布于http://danvid.cnblogs.com/,如需转载或部分使用请注明出处 在业务中经常会用到拼音匹配查询,大家都会用到拼音分词器,但是拼音分词器匹配的 ...
- ES[7.6.x]学习笔记(七)IK中文分词器
在上一节中,我们给大家介绍了ES的分析器,我相信大家对ES的全文搜索已经有了深刻的印象.分析器包含3个部分:字符过滤器.分词器.分词过滤器.在上一节的例子,大家发现了,都是英文的例子,是吧?因为ES是 ...
- Elasticsearch(ES)分词器的那些事儿
1. 概述 分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引. 今天我们就来聊聊分词器的相关知识. 2. 内置 ...
- ES之分析器(Analyzer)及拼音分词器
把输入的文本块按照一定的策略进行分解,并建立倒排索引.在Lucene的架构中,这个过程由分析器(analyzer)完成. 主要组成 character filter:接收原字符流,通过添加.删除或者替 ...
- ES 09 - 定制Elasticsearch的分词器 (自定义分词策略)
目录 1 索引的分析 1.1 分析器的组成 1.2 倒排索引的核心原理-normalization 2 ES的默认分词器 3 修改分词器 4 定制分词器 4.1 向索引中添加自定义的分词器 4.2 测 ...
随机推荐
- 初始OpenGL
OpenGL到底是什么? 一般它被认为是一个API,包含一系列操作图形,图像的函数.然而,它并不是一个API,而是Khronos组织制定并维护的规范. OpenGL规定了每个函数如何执行,以及它们的输 ...
- django-filter的详细使用
有时候前端需要各种各样的过滤查询,如果自己写多少有点麻烦和冗余.使用django-filter就可以很好的解决这个问题. django-filter可以用在django上, 也与配合drf一起使用. ...
- Scrapy在pipeline中集成mongodb
settings.py中设置配置项 MONGODB_HOST = "127.0.0.1" MONGODB_PORT = 27017 MONGODB_DB_NAME = " ...
- 华企盾DSC防泄密系统:半透明问题调试方法
1.先添加下图中的注册表 2.用debugview工具监控操作过程,然后找到后面是DSE_SANDBOX,把它前面的值一个一个加到控制台的半透明沙盒对象里面调,直到找到可以正常的为止 3.用supe ...
- 3D网站LOGO动画
相关技术和实现分析 3D模型 帧动画 threejs 推荐用blender创建3d模型,k帧实现从上到下翻转的帧动画 threejs 中执行帧动画,并关联滚动条 threejs 模型材质 Blende ...
- Ef Core花里胡哨系列(10) 动态起来的 DbContext
Ef Core花里胡哨系列(10) 动态起来的 DbContext 我们知道,DbContext有两种托管方式,一种是AddDbContext和AddDbContextFactory,但是呢他们各有优 ...
- LeetCode 947. 移除最多的同行或同列石头 并查集
传送门 思路 干货太干就不太好理解了,以下会有点话痨( ̄▽ ̄)" 首先题目给了一个二维stones数组,存储每个石子的坐标,因为在同行或者同列的石子最终可以被取到只剩下一个,那么我们将同行同 ...
- C++ Traits Classes
参考博文 https://blog.csdn.net/lihao21/article/details/55043881 Traits classes 的作用主要是用来为使用者提供类型信息.在 C++ ...
- JSON字符串中获取一个特定字段的值
第一种 import com.google.gson.JsonObject; import com.google.gson.JsonParser; String json="{\" ...
- 如何使用 Node.js Stream API 减少服务器端内存消耗?
摘要:让我们看一个示例,展示在内存消耗方面,采用流的编程思路带来的巨大优越性. 本文分享自华为云社区<使用 Node.js Stream API 减少服务器端内存消耗的一个具体例子>,作者 ...