node pressure and pod eviction
0. overview
There are too many guides about node pressure and pod eviction, most of them are specific, and no system. so here is to combine the knowledge together and see it system and specific. Before introduce the knowledge lets us thinking those questions(actually too many questions..). What happened when the node shutdown, what happened if the API-server of Kubernetes can not connect to the Kubelet, what happened if the pod use too much resource even made the node unhealthy.
Yes, it just a piece of node pressure and pod eviction, the node pressure and pod eviction are more likely to belong to the abnormal cases, and yes those cases are very very important for business.
And here has a manifest about the guide cause is the abnormal cases and I just have the env with company product, it's serious and I don't want touch and make the env bad for our abnormal cases. So there is no too much demo with trials, for the demo I will attach the links if needed, and yes minikube is a good VM Kubernetes platform for newcomer and I also do something in minikube but I have checked with some materials online there already has a similar demo so I will pick the online materials directly.
1. container resource
As we know the app is running within a container and the resource is covered at the container level, there are limited by Cgroups. For container resource, it can be defined with CPU, memory, disk. For CPU is the compressible resources, but for memory, disk is the incompressible resources which means if one container uses too much memory, others(container/process/thread) will no too much memory can be used. so the resource limit is important, in Kubernetes, there are two fields that can define the resource: request and limit.
- requests: is the minimal resource container requests, but the container can use less than the request value.
- limits: is the maximal resource container requests, once out of the limits OOM killer will kill the container.
ok, lets us focus on the requests field, design an appropriate value that is good enough for requests cause Kubernetes will schedule the pod(container) to nodes bases on the requests, not the actual resources. For example, there is 500M memory of node can be allocated,one pod(just have one container) requests 600M but actually, the container just use 100M(the request value is more than actual value).. the container still can not scheduler to the node cause the requested memory is over than the allocated memory of the node.
here we are discussing the container resource, for pod resources, yes you probably know is the sum of all containers. now lets we thinking if the node resource is not enough and the pod needs to be evicted, which pod should be the first one? we must be thinking the low priority pods should be evicted, correct, Kubernetes has a QoS field that defined the priority of pod, how to define the priority is pretty simple by requests and limits.
there are too many guides that introduce how to define the priority: BestEffort, Burstable, and Guaranteed. I just want mentioned requests/limits are for container level, for pod QoS depends on all container requests/limits, which means all QoS of the container is the same, the pod QoS is the same as the container's Qos, but once one container QoS is different with others, the QoS of the pod is Burstable. let see the table directly:
| container1 QoS | container2 QoS | pod QoS |
|---|---|---|
| BestEffort | BestEffort | BestEffort |
| BestEffort | Burstable | Burstable |
| BestEffort | Guaranteed | Burstable |
| BestEffort | Burstable | Burstable |
| Burstable | Burstable | Burstable |
| Burstable | Burstable | Burstable |
| Burstable | Guaranteed | Burstable |
| Guaranteed | Guaranteed | Guaranteed |
For the description of QoS please refer to here.
2. node pressure eviction
In chapter1 we know that if the pod wants to use the incompressible resource more than the limits of resource, the OOM killer will kill the process, more detailed info can refer here.
Now if the node has the pressure of incompressible resources, but pods haven't use the resource over the limits, how do the Kubernetes do? it will introduce the Kubelet module of Kubernetes, Kubelet will monitor the resource of pods and report the resource to API-server, once meet the condition of pod eviction, the Kubelet will do the eviction action.
let's see the configure for Kubelet, just pick the necessary field:
[root@chunqiu ~ (Master)]# systemctl cat kubelet.service
# /etc/systemd/system/kubelet.service
...
ExecStart=/usr/local/bin/kubelet \
--pod-infra-container-image=bcmt-registry:5000/gcr.io/google-containers/pause-amd64:3.1 \
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \
--config=/etc/kubernetes/kubelet-config.yml \
...
Restart=always
RestartSec=5
Slice=system.slice
OOMScoreAdjust=-999
[root@chunqiu ~ (Master)]# cat /etc/kubernetes/kubelet-config.yml
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
...
nodeStatusUpdateFrequency: 8s
evictionPressureTransitionPeriod: "60s"
evictionMaxPodGracePeriod: 120
evictionHard:
memory.available: 9588Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
imagefs.available: 15%
evictionSoft:
memory.available: 15341Mi
evictionMminimumReclaim:
memory.available: 15341Mi
evictionSoftGracePeriod:
memory.available: "30s"
systemReserved:
memory: 33Gi
cpu: "44"
Before introducing these parameters, let's see the eviction is split into two kinds of styles: soft eviction and hard eviction. For soft eviction, there are graceful eviction time(evictionSoftGracePeriod) and also graceful eviction time for pod(evictionMaxPodGracePeriod). For hard eviction, it more like an urgent status for node, so the pod will be evicted immediately to relieve symptoms asap.
ok, let's see the parameters now, and yes the detailed introduce can be found from Kubernetes Docs here.
common parameters
- nodeStatusUpdateFrequency: as the name, Kubelet will report the node status to API-server with this frequency, for the frequency is also too much is too slow to check the status of the node, too lower will make the node update frequently. it has been discussed with the article here.
- evictionPressureTransitionPeriod: when a pod has been evicted, probably the pod will be scheduled to the same node(with a label, affinity..) at that time the node pressure will become high again, then eviction will be triggered again, so the pod will be eviction and do the same procedure like a circle(and also here has an exponential delay for pod delete, it means pod will be deleted after 10s, 20s,30s.. till default value 5minutes, after that pod will be deleted by 5min, 10min.. this mechanism is for avoiding the frequent deletion of a pod), so Kubernetes has defined a period with parameter evictionPressureTransitionPeriod is to keep no pod scheduled to the node which just eviction pods.
- evictionMminimumReclaim: see how much resource Kubernetes will be clean up, if too low the purpose of eviction is not obvious, which means the pod will scheduler to the node again and the resource pressure will high after a while. so Kubernetes will clean up to enough resources which have been defined with parameter evictionMminimumReclaim so that no more resource pressure frequently.
soft eviction
- memory.available: is the target of memory available, once over the target, the pod eviction will be triggered.
- evictionSoftGracePeriod: after fitting the target, wait the time of evictionSoftGracePeriod to see whether the target is always satisfied, once satisfied the "alarm" will be canceled.
- evictionMaxPodGracePeriod: once fitting the target and satisfied the time of evictionSoftGracePeriod, the pod will be eviction by Kubelet, and the pod needs to graceful shutdown during the time evictionMaxPodGracePeriod, is important for business. The time of evictionMaxPodGracePeriod has two places one is the time that set in the pod manifest, Kubelet will choose the minimal value, such as here the evictionMaxPodGracePeriod is 120(s), and the pod manifest has defined the time with terminationGracePeriodSeconds: 30(s), so the evictionMaxPodGracePeriod time for Kubelet is 30(s).
hard eviction
- there are no too many parameters defined for hard eviction cause hard eviction is an urgent case once met the hard condition, the pod will be evicted immediately.
emm.., another question raised up: which pod should be eviction? it more related to the QoS that we discussed in the chapter1, and the incompressible resource itself, for how to pick the evicted pod here has been introduced in detail, we just skip it, and then we know the framework now, but how do we know the real-time resource status of pod or specific containers?
It will relate with the monitor mechanism of Kubernetes, the Kubelet module of Kubernetes has integrated the cAdvisor module build-in which is to monitor the pods status. and there is another module called metrics-server that will collect all cAdvisor data together then provide to outside with Kubernetes service clusterIP:
[root@chunqiu ~ (Master)]# kubectl get pods -n kube-system | grep met
dashboard-metrics-scraper-6554464489-kptsr 1/1 Running 1 102d
metrics-server-78f8b874b5-4hdzj 2/2 Running 4 102d
[root@chunqiu ~ (Master)]# kubectl get service -n kube-system | grep met
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metrics-server ClusterIP **.***.246.177 <none> 443/TCP 102d
for more detailed Infos about the metrics server please refer here.
we can get the metrics server data by curl, but a more common way is to use the command: kubectl top, like:
[root@chunqiu ~ (Master)]# kubectl top pod --containers -n ci
POD NAME CPU(cores) MEMORY(bytes)
chunqiu-pod-0 container1 7m 64Mi
chunqiu-pod-0 container2 9m 83Mi
chunqiu-pod-0 container3 4m 20Mi
...
The result is different from the Kubectl describe command, this is the real-time resource status of pods.
ok, someone might see we can check the real-time result, but how do I know the resource define of containers? yes, this is related to the Linux cgroup, we can check with the container inside:
[root@chunqiu ~ (Master)]# kubectl exec -it chunqiu-pod-0 /bin/bash -n ci
bash-5.0$ ls /sys/fs/cgroup/memory/
memory.kmem.max_usage_in_bytes memory.max_usage_in_bytes memory.pressure_level
...
the container resource has been defined in cgroup, and also can check the defined with pod level, more detailed info can refer to here.
3. node eviction
Chapter2 we have discussed the case of node pressure, but how about this case that node shutdown and can not recovery long time, or network issue cause work node can not connect to the master node. For this case is also covered in Kubernetes, the controller manager has to monitor the status of the node, once the node "failed"(can cause by many factors), the Kubelet can not connect to API-server, which is an offline status, and then the controller manager will do something "delete" the pod, add Taints and scheduler the pod to other nodes. Describe the procedure is so complex, let's see a procedure figure first:
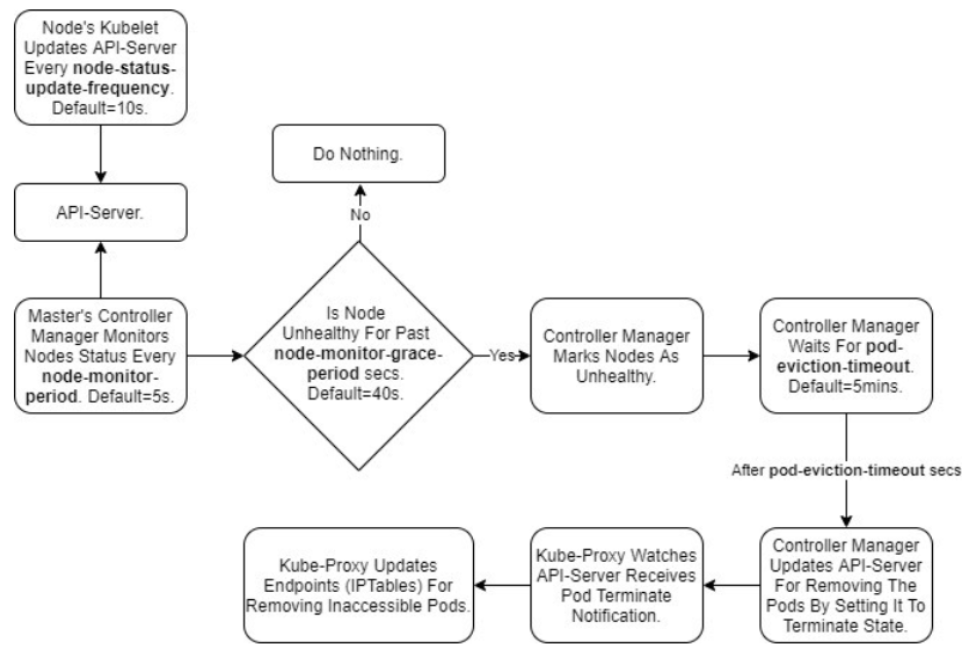
The figure is clear, we will introduce the procedure based on the figure, first, let's see the parameters that can be found by the controller-manager defined in the picture.
[root@chunqiu ~ (Master)]# kubectl get pods -n kube-system | grep controller-manager
kube-controller-manager-chunqiu-0 1/1 Running 1 102d
[root@chunqiu ~ (Master)]# kubectl describe pods kube-controller-manager-chunqiu-0 -n kube-system
Name: kube-controller-manager-chunqiu-0
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: chunqiu-0/172.17.66.2
Controlled By: Node/chunqiu-0
Command:
/usr/local/bin/kube-controller-manager
--node-monitor-period=5s
--node-monitor-grace-period=35s
--pod-eviction-timeout=120s
--terminated-pod-gc-threshold=100
State: Running
Last State: Terminated
Reason: Error
Exit Code: 255
Ready: True
Restart Count: 1
Limits:
cpu: 300m
memory: 1000Mi
Requests:
cpu: 100m
memory: 30Mi
Liveness: http-get https://127.0.0.1:10252/healthz delay=15s timeout=1s period=10s #success=1 #failure=3
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
...
There are some necessary parameters that need to introduce, the detained info can check here:
- node-monitor-period: the controller manager will query the API-server by the period of node-monitor-period.
- node-monitor-grace-period: if the status of the node is not ready or unknown with the period of node-monitor-grace-period, the node will be set as unhealthy(unknown), the default time of node-monitor-grace-period is the 40s.
- pod-eviction-timeout: after fitting the node-monitor-grace-period, the controller manager will wait the time of pod-eviction-timeout, after meeting the time, the controller manager will update the pod status as Terminating. The default time of pod-eviction timeout is 5 minutes.
Combine the procedure and parameters. Now let us summary the procedure here:
The Kubelet will report the node status to API-server with the period of nodeStatusUpdateFrequency, and then the controller manager will query the node status by API-server, here if the time is over the node-monitor-period, the node will be set as not ready(the meaning is like one give a signal to other, but other handles the signal so slowly, and also the revert case one query signal from other, but other haven't sent the signal), the more discussed the info can be checked here. ok, then if the status of the node is not ready(unhealthy)(actually, I haven't find the info about how to define the node status, like when is not ready, when is unhealthy, when is unknown, a related article is in here, it might occur together, but still need check, anyone knows the info please tell me, thanks so much). and then if the not ready status keeps until the period of node-monitor-grace-period, the node will be set as unknown, and the controller manager will wait for the time defined in pod-eviction-timeout, after that the pod will be set as Terminating but it still existing in Kubernetes cause Kubernetes doesn't know what happened with the unknown node, and also doesn't know the pod alive or not. The controller manager will set the status of the pod, and then add the Taints to the unknown nodes:
node.kubernetes.io/not-ready: Node is not ready. This corresponds to the NodeCondition Ready being “False”;
node.kubernetes.io/unreachable: Node is unreachable from the node controller. This corresponds to the NodeCondition Ready being “Unknown”.
after that, the new pod will be scheduled to other nodes, and once the unknown nodes become normal the old pod will be deleted by Kubelet which is triggered by the controller manager, also the operator can delete the Terminating pod manually in this case.
ok, is finished all? I would like to see no. lets us thinking again pod has been controller by the controller manager which divided into deployments, statefulSet, Daemonset.. so we talked above is what kind of controller? I prefer is deployments much cause for statefulSet the controller manager doesn't scheduler the new pod, the real action is to wait for the status of the old pod from Terminating to Ready, for daemonset is almost same, and the daemonset is more adapt for the hot env, more detailed info can refer to here.
4. What Next?
- For CPU/memory.. is the system resource, and if we want to define the resource by ourself how should we do?
- We have seen the priority 2000001000 of pod kube-controller-manager-chunqiu-0, how do the priority get and what's the functionality of the priority?
- What happened if the node has been added the Taints.
node pressure and pod eviction的更多相关文章
- kubernetes continually evict pod when node's inode exhausted
kubernetes等容器技术可以将所有的业务进程运行在公共的资源池中,提高资源利用率,节约成本,但是为避免不同进程之间相互干扰,对底层docker, kubernetes的隔离性就有了更高的要求,k ...
- kubernetes 利用label标签来绑定到特定node运行pod
利用label标签来绑定到特定node运行pod: 不如将有大量I/O的pod部署到配置了ssd的node上或者需要使用GPU的pod部署到某些安装了GPU的节点上 查看节点的标签: kubectl ...
- Kubernetes调整Node节点快速驱逐pod的时间
在高可用的k8s集群中,当Node节点挂掉,kubelet无法提供工作的时候,pod将会自动调度到其他的节点上去,而调度到节点上的时间需要我们慎重考量,因为它决定了生产的稳定性.可靠性,更快的迁移可以 ...
- k8s,coredns内部测试node节点上的pod的calico是否正常的一个小技巧
最近由于master整个挂掉,导致相关一些基础服务瘫掉,修复中测试有些节点网络又出现不通的情况正常的启动相关一些服务后,测试一些节点,比较费劲,还有进入pod,以及还有可能涉及命名空间操作这里可以这样 ...
- 我们可以定向调度某个pod在某个node上进行创建
集群环境:1.k8s用的是二进制方式安装 2.操作系统是linux (centos)3.操作系统版本为 7.2/7.4/7.94.k8s的应用管理.node管理.pod管理等用rancher.k8s令 ...
- 8.深入k8s:资源控制Qos和eviction及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com,源码版本是1.19 又是一个周末,可以愉快的坐下来静静的品味一段源码,这一篇涉及到资源的 ...
- Kubernetes基础:Pod的详细介绍
本文的演练环境为基于Virtualbox搭建的Kubernetes集群,具体搭建步骤可以参考kubeadm安装kubernetes V1.11.1 集群 1. 基本概念 1.1 Pod是什么 Pod是 ...
- kubernetes-深入理解pod对象(七)
Pod中如何管理多个容器 Pod中可以同时运行多个进程(作为容器运行)协同工作.同一个Pod中的容器会自动的分配到同一个 node 上.同一个Pod中的容器共享资源.网络环境和依赖,它们总是被同时调度 ...
- tune kubernetes eviction parameter
Highlight 本文会介绍kubernetes中关于集群驱逐的相关参数, 合理设置驱逐速率的考虑因素, 但是不会涉及node层面资源的驱逐阈值的设置. Basic 在kubernetes中, 如果 ...
- 深入掌握K8S Pod
k8s系列文章: 什么是K8S K8S configmap介绍 Pod是k8s中最小的调度单元,包含了一个"根容器"和其它用户业务容器. 如果你使用过k8s的话,当然会了解pod的 ...
随机推荐
- POJ-3624 01背包入门
还是入门题,只不过需要优化一下空间,不然就会内存超限 Bessie has gone to the mall's jewelry store and spies a charm bracelet. O ...
- Object类、String和StringBuffer、Math类、日期处理类
1.Object类 "万物皆对象":(1)从类和对象角度:任何具体事物都是一个对象,. (2)Object类,类似"东西".所有的类都继承了Object类. 使 ...
- React 类组件转换为函数式
函数式的 React 组件更加现代,并支持有用的 hooks,现在流行把旧式的类组件转换为函数式组件.这篇文章总结了转换的一些通用的步骤和陷阱. 通用替换 定义 从 class (\w+) exten ...
- 文心一言 VS 讯飞星火 VS chatgpt (144)-- 算法导论12.1 4题
四.用go语言,对于一棵有 n 个结点的树,请设计在 O(n)时间内完成的先序遍历算法和后序遍历算法. 我个人喜欢 灵小智 . 文心一言: 在 Go 语言中,我们可以使用递归来实现树的前序遍历和后序遍 ...
- BM25(Best Matching 25)算法基本思想
BM25(Best Matching 25)是一种用于信息检索(Information Retrieval)和文本挖掘的算法,它被广泛应用于搜索引擎和相关领域.BM25 基于 TF-IDF(Ter ...
- ReactNative环境安装
一.Homebrew 采用 Homebrew 镜像源及工具,切换到国内. /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/Homebre ...
- 新晋“网红”Cat1 是什么
摘要:此Cat非彼Cat,它是今年物联网通信圈新晋网红"靓仔". 引言 今年5月,工信部发布了<关于深入推进移动物联网全面发展的通知>,明确提出推动存量2G.3G物联网 ...
- Java开发如何通过IoT边缘ModuleSDK进行进程应用的开发?
摘要:为解决用户自定义处理设备数据以及自定义协议设备快速接入IOT平台的诉求,华为IoT边缘提供ModuleSDK,用户可通过集成SDK让设备以及设备数据快速上云. 本文分享自华为云社区<[华为 ...
- 高颜值开源数据可视化工具——Superset 2.0正式发布!
Superset终于迎来了又一个重大的版本更新.使用superset已经近三年的时间了,其为我们提供了数据可视化的解决方案.也成为了最好的商用BI的替代方案. 在Github上本次更新已经发布 ...
- Seal 软件供应链防火墙 v0.2 发布,提供依赖项全局洞察
Seal 软件供应链防火墙 v0.2 已于近日发布.这款产品旨在为企业提供代码安全.构建安全.依赖项安全及运行环境安全等4大防护,通过全链路扫描.问题关联及风险组织的方式保护企业软件供应链安全,降低企 ...