Stable Diffusion中的embedding
Stable Diffusion中的embedding
嵌入,也称为文本反转,是在 Stable Diffusion 中控制图像样式的另一种方法。在这篇文章中,我们将学习什么是嵌入,在哪里可以找到它们,以及如何使用它们。
什么是嵌入embedding?
嵌入(Embedding)是一种在机器学习和人工智能领域中常用的技术,特别是在图像生成和风格迁移等任务中。文本反转(Textual Inversion)则是一种特定于图像生成领域的方法,它允许用户在不直接修改预训练模型的情况下,通过定义新的关键字来引入新的样式或对象。
这种方法之所以受到关注,主要是因为它提供了一种高效且灵活的方式来扩展和定制AI模型的能力。尤其是在样本图像数量有限的情况下(例如只有3到5个样本),文本反转能够显著提高模型的适应性和创造力。通过这种方式,模型能够学习并模仿特定的风格或特征,并将其应用到新的图像生成过程中。
文本反转是如何工作的?
文本反转的核心思想是将特定的文本描述与图像特征相关联。这个过程通常包括以下几个步骤:
- 样本收集:首先,收集一组具有相似风格或包含特定对象的样本图像。
- 文本描述:为每个样本图像创建一个文本描述,这个描述应该捕捉到图像的关键特征或风格。
- 嵌入训练:使用这些文本描述和对应的样本图像来训练一个嵌入模型。这个模型将学习如何将文本描述映射到图像特征上。
- 应用嵌入:一旦嵌入模型训练完成,就可以将其应用于新的图像生成任务中。当模型接收到一个与训练时相似的文本描述时,它能够生成具有相应特征或风格的图像。
嵌入的优势
嵌入技术的优势在于其灵活性和高效性。通过文本反转,用户可以在不改变原有模型结构的前提下,快速地引入新的风格或对象。这种方法特别适用于以下场景:
- 快速原型设计:设计师和艺术家可以迅速尝试不同的风格和概念,而无需从头开始训练复杂的模型。
- 个性化定制:用户可以根据自己的喜好和需求,定制独特的图像风格或对象。
- 数据稀缺情况:即使在样本数量有限的情况下,也能够有效地训练模型,使其学习到新的样式或特征。
总的来说,嵌入和文本反转为图像生成领域提供了一种创新的方法,使得AI模型更加灵活和易于使用。通过这种方式,我们可以更好地利用现有的AI资源,创造出更加多样化和个性化的视觉内容。
下面转载的原始研究文章中的图表说明了它是如何工作的。
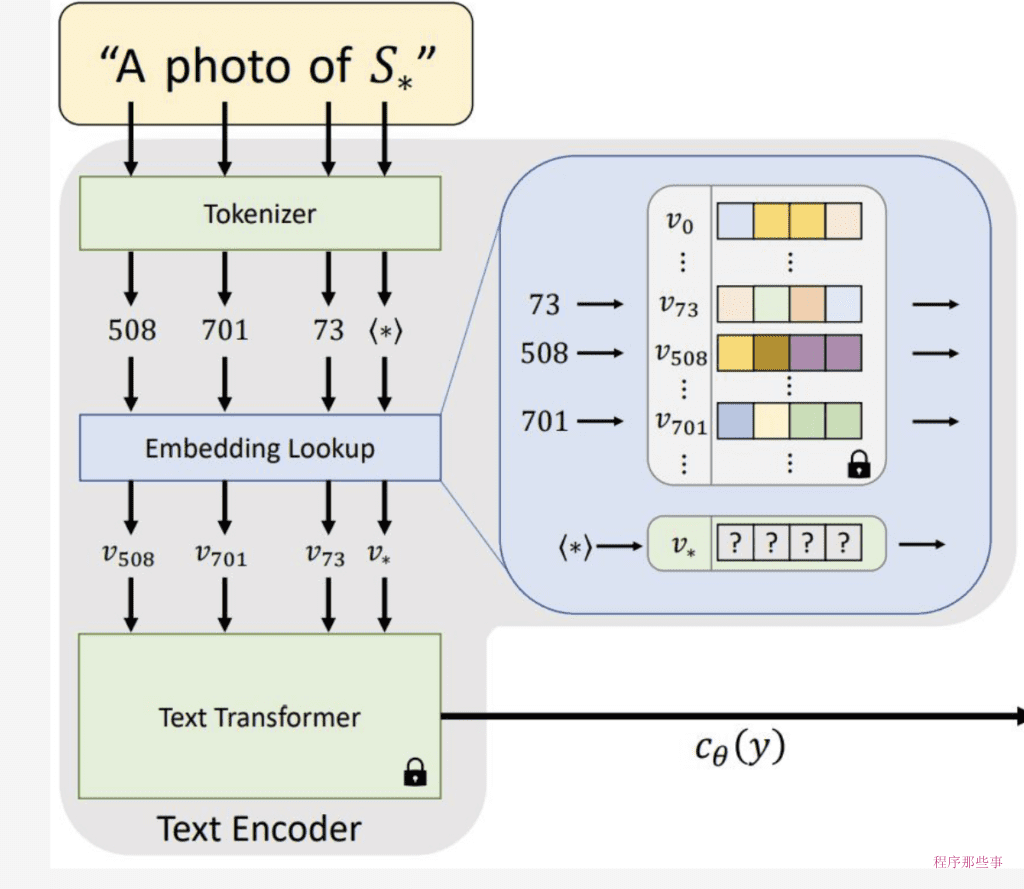
在使用稳定扩散AI模型进行图像生成时,引入新的对象或样式是一个常见的需求。为了实现这一点,文本反转(Textual Inversion)提供了一种有效的方法,允许我们在不修改模型本身的情况下,通过定义新的关键字来实现这一目标。下面是详细的步骤说明:
定义新的关键字
- 选择或创建新关键字:首先,你需要为想要添加到模型中的新对象或样式选择或创造一个独特的关键字。这个关键字应该是描述性的,能够清晰地表达你想要引入的新元素。
- 标记化:在模型中,所有的文本提示都是通过标记化(Tokenization)过程被转换成数字形式的。这个过程将文本中的每个单词或符号转换成对应的数字标记。对于你定义的新关键字,它也会被转换成一个唯一的数字标记。
生成嵌入向量
- 嵌入向量生成:每个标记(包括新关键字的标记)都会被进一步转换为嵌入向量。嵌入向量是高维空间中的点,它能够捕捉和表示文本的语义信息。在这个过程中,新关键字会被赋予一个独特的嵌入向量。
- 文本反转过程:文本反转技术的核心在于,它允许我们通过嵌入向量来查找和表示新关键字,而无需更改模型的任何其他部分。这意味着,即使模型在训练时没有直接接触过新关键字,它也能够通过嵌入向量来理解和生成与新关键字相关的图像内容。
应用新关键字
- 在提示中使用新关键字:在生成图像时,你可以在文本提示中包含新关键字。由于新关键字已经被标记化并转换成了嵌入向量,模型能够识别并将其作为生成图像的依据。
- 生成图像:当模型接收到包含新关键字的提示时,它会查找与该关键字对应的嵌入向量,并使用这个向量来生成图像。这个过程就像是在语言模型中引入了一种新的语言元素,使得模型能够理解和创造出新的概念。
通过这种方式,文本反转为我们提供了一种强大的工具,使得我们能够在不改变模型结构的前提下,灵活地引入新的对象或样式,极大地扩展了图像生成的可能性。这种方法不仅提高了模型的适应性和灵活性,也为艺术家和设计师提供了更多的创作自由。
在哪里可以找到embedding
下载embedding的首选位置是 Civitai。
我们在C站的右上角可以有一个filter选项:
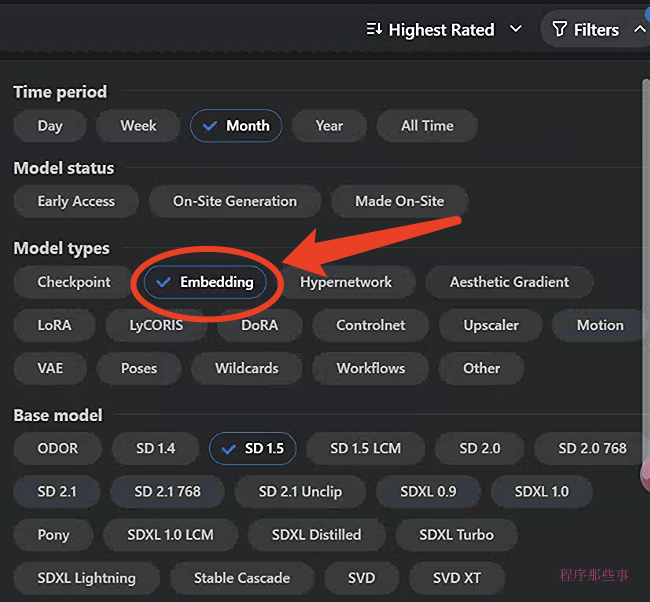
在filter中选择model types= embedding就可以找到对应的embedding了。
如何使用embedding
在 AUTOMATIC1111 中使用embedding很容易。
首先,从 Civitai 网站下载好embedding文件。下载下来的embedding文件通常是bin或者pt结尾的。
你需要把这些embedding文件放到Stable diffusion webUI根目录下面的embeddings文件夹,然后重启Stable diffusion webUI即可。
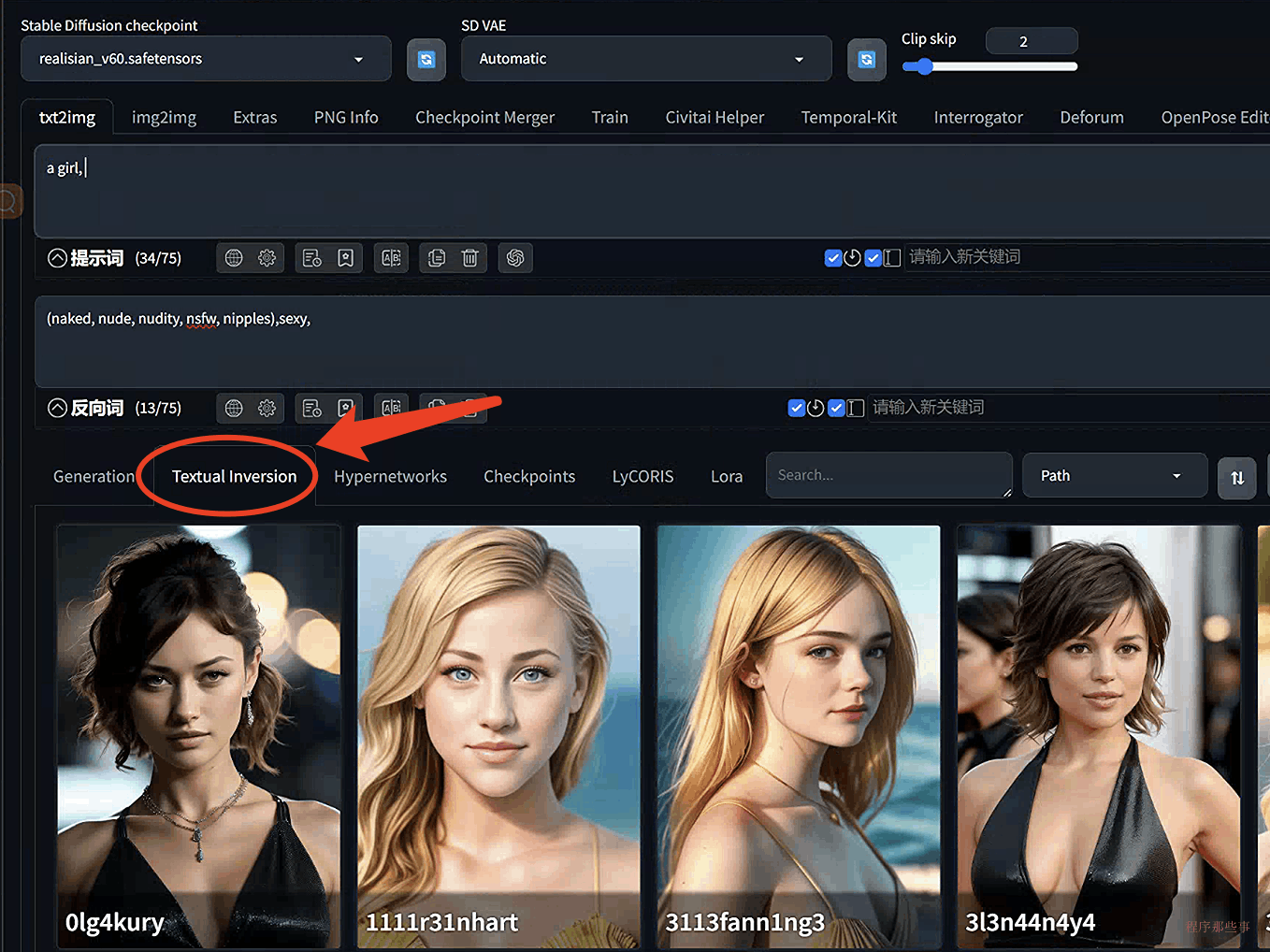
在webUI界面,你可以在Textual Inversion中找到你安装好的embedding。
要使用他,只需要点击对应的embedding, webUI会自动把对应的embedding添加到提示词中去。比如:
a girl,0lg4kury,
这里0lg4kury就是我安装的第一个embedding的名字。点击生成,看看效果:

可以看到人物还是很相似的。
这里我用了多种采样方法来进行最终图片的对比。
调整embedding的强度
之前听过我的prompt文章的朋友应该知道我们可以调整提示词强度的。
因为embedding同样也是提示词的一部分,所以我们也可以用同样的方式来调整embedding的强度。

neg embedding
有了正面的embedding,同样也有负面的embedding,下面是几个常用的负面embedding:



embedding、dreambooth 和hypernetwork的区别
文本反转(Textual Inversion)、Dreambooth 和超网络 是三种不同的技术,它们都可以用于微调Stable Diffusion模型,但各自有不同的特点和应用场景。
- 文本反转(Textual Inversion):
- 文本反转是一种通过少量样本图像来训练模型的方法,它允许用户定义新的关键字来描述特定的对象或风格。
- 这种方法不需要更改模型的结构,而是通过嵌入向量来实现新关键字的添加。
- 嵌入向量存储在相对较小的文件中(通常小于100 kB),这使得它们易于存储和传输。
- 文本反转适合于快速添加新概念到模型中,但可能不如其他方法那样灵活或强大。
- Dreambooth:
- Dreambooth是一种基于深度学习的图像风格转换技术,它使用少量图像来训练模型。
- 它特别适合于生成高质量艺术作品,而无需用户具备专业艺术技能。
- Dreambooth通过微调模型的权重来实现特定主题的生成,这可能导致模型过度拟合训练数据。
- 它生成的模型文件相对较大(2-4GB),并且在使用时需要加载模型。
- 超网络(Hypernetwork):
- 超网络是一种使用神经网络来生成模型参数的方法。
- 它通过在原有模型的基础上添加一个附加网络来实现微调,这个附加网络可以学习新的生成特征。
- 超网络生成的模型文件大小介于文本反转和Dreambooth之间(大约几十MB),这使得它在存储和传输方面比较平衡。
- 超网络适合于生成近似内容图像,如果训练数据与目标风格高度相关,那么超网络是一个不错的选择。
总的来说,文本反转、Dreambooth和超网络各有优势和适用场景。文本反转适合快速添加新概念,Dreambooth适合个性化的高质量图像生成,而超网络则提供了一种在保留原有模型结构的同时进行微调的中间方案。用户可以根据自己的需求和资源限制来选择最合适的方法。
Stable Diffusion中的embedding的更多相关文章
- Diffusers中基于Stable Diffusion的哪些图像操作
目录 辅助函数 Text-To-Image Image-To-Image In-painting Upscale Instruct-Pix2Pix 基于Stable Diffusion的哪些图像操作们 ...
- AI绘画提示词创作指南:DALL·E 2、Midjourney和 Stable Diffusion最全大比拼 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
- 从 GPT2 到 Stable Diffusion:Elixir 社区迎来了 Hugging Face
上周,Elixir 社区向大家宣布,Elixir 语言社区新增从 GPT2 到 Stable Diffusion 的一系列神经网络模型.这些模型得以实现归功于刚刚发布的 Bumblebee 库.Bum ...
- 基于Docker安装的Stable Diffusion使用CPU进行AI绘画
基于Docker安装的Stable Diffusion使用CPU进行AI绘画 由于博主的电脑是为了敲代码考虑买的,所以专门买的高U低显,i9配核显,用Stable Diffusion进行AI绘画的话倒 ...
- 使用 LoRA 进行 Stable Diffusion 的高效参数微调
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题.目前超过数十亿以上参数的具有强能力的大 ...
- Stable Diffusion魔法入门
写在前面 本文为资料整合,没有原创内容,方便自己查找和学习, 花费了一晚上把sd安装好,又花了大半天了解sd周边的知识,终于体会到为啥这些生成式AI被称为魔法了,魔法使用前要吟唱类比到AI上不就是那些 ...
- Window10环境下,Stable Diffusion的本地部署与效果展示
Diffusion相关技术最近也是非常火爆,看看招聘信息,岗位名称都由AI算法工程师变成了AIGC算法工程师,本周跟大家分享一些Diffusion算法相关的内容. Window10环境下,Stable ...
- Stable Diffusion 关键词tag语法教程
提示词 Prompt Prompt 是输入到文生图模型的文字,不同的 Prompt 对于生成的图像质量有较大的影响 支持的语言Stable Diffusion, NovelAI等模型支持的输入语言为英 ...
- 最新版本 Stable Diffusion 开源AI绘画工具之部署篇
目录 AI绘画 本地环境要求 下载 Stable Diffusion 运行启动 AI绘画 关于 AI 绘画最近有多火,既然你有缘能看到这篇文章,那么相信也不需要我过多赘述了吧? 随着 AI 绘画技术的 ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之汉化篇
目录 汉化预览 下载汉化插件一 下载汉化插件二 下载汉化插件三 开启汉化 汉化预览 在上一篇文章中,我们安装好了 Stable Diffusion 开源 AI 绘画工具 但是整个页面都是英文版的,对于 ...
随机推荐
- RageFrame学习笔记:环境配置+项目拉取并实例化到本地
最近在研究一个基于YII2的框架,原本我以为很简单,但没想到在第一步环境配置和实例化上就卡了我4个小时,这里分享出我走过的弯路和解决问题的整个流程. 关注我文章的朋友应该了解过,我之前学习easyad ...
- python实现批量运行命令行
python实现批量运行命令行 背景: 对于不同参数设置来调用同一个接口,如果手动一条条修改再运行非常慢且容易出错.尤其是这次参数非常多且长.比如之前都是输入nohup python -u exe.p ...
- MappedByteBuffer VS FileChannel:从内核层面对比两者的性能差异
本文基于 Linux 内核 5.4 版本进行讨论 自上篇文章<从 Linux 内核角度探秘 JDK MappedByteBuffer> 发布之后,很多读者朋友私信我说,文章的信息量太大了, ...
- https://codeforces.com/gym/496432
ABC:略. D 枚举分的段数,然后扫一遍判断. E F G H
- list集合中的实现类Vector
Vector: 它底层也是用数组来存数据对象的,但它是唯一一个线程安全的,线程安全也就意味着时间长,效率慢,如果是单一线程的话,建议不使用该实现类 add(E element): 将指定的元素追加到此 ...
- 提高生产力!这10个Lambda表达式必须掌握,开发效率嘎嘎上升!
在Java8及更高版本中,Lambda表达式的引入极大地提升了编程的简洁性和效率.本文将围绕十个关键场景,展示Lambda如何助力提升开发效率,让代码更加精炼且易于理解. 集合遍历 传统的for-ea ...
- OpenHarmony之NAPI框架介绍
张志成 诚迈科技高级技术专家 NAPI是什么 NAPI的概念源自Nodejs,为了实现javascript脚本与C++库之间的相互调用,Nodejs对V8引擎的api做了一层封装,称为NAPI.可 ...
- C#_面试题1
C#_面试题1 1.维护数据库的完整性.一致性.你喜欢用触发器还是自写业务逻辑?为什么? 答:尽可能用约束(包括CHECK.主键.唯一键.外键.非空字段)实现,这种方式的效率最好:其次用触发器,这种方 ...
- Linux Ubuntu配置国内源
配置国内源 因为众所周知的原因,国外的很多网站在国内是访问不了或者访问极慢的,这其中就包括了Ubuntu的官方源. 所以,想要流畅的使用apt安装应用,就需要配置国内源的镜像. 市面上Ubuntu的国 ...
- 国产开源数据库OpenGauss的安装运行
步骤一:OpenGauss 的安装 环境 OS:openEuler 20.03 64bit with ARM 架构:arm64 部署:单机 安装过程 1.环境配置 安装依赖包: yum install ...