MindSpore分布式并行训练 (GPU-Docker)mindspore—1.2.1—gpu—docker版本运行报错,Failed to init nccl communicator for group,init nccl communicator for group nccl_world_group
如题目所述:
计算框架MindSpore分布式并行训练报错,具体版本:docker-gpu-1.2.1
运行环境:
硬件:Intel CPU, 4卡泰坦
软件:Ubuntu18.04宿主机,docker容器运行MindSpore-gpu-1.2.1-docker版本
相关软件安装与免密登陆配置:
docker容器中安装:
OpenMPI-4.0.3:MindSpore采用的多进程通信库。
OpenMPI-4.0.3源码下载地址:https://www.open-mpi.org/software/ompi/v4.0/,选择openmpi-4.0.3.tar.gz下载。
参考OpenMPI官网教程安装:https://www.open-mpi.org/faq/?category=building#easy-build。
NCCL-2.7.6:Nvidia集合通信库。
NCCL-2.7.6下载地址:https://developer.nvidia.com/nccl/nccl-legacy-downloads。
参考NCCL官网教程安装:https://docs.nvidia.com/deeplearning/nccl/install-guide/index.html#debian。
免密登陆配置:
主机间免密登陆(涉及多机训练时需要)。若训练涉及多机,则需要配置多机间免密登陆,可参考以下步骤进行配置:
- 每台主机确定同一个用户作为登陆用户(不推荐root);
- 执行ssh-keygen -t rsa -P ""生成密钥;
- 执行ssh-copy-id DEVICE-IP设置需要免密登陆的机器IP;
- 执行ssh DEVICE-IP,若不需要输入密码即可登录,则说明以上配置成功;
- 在所有机器上执行以上命令,确保两两互通。
具体操作参考:
https://www.mindspore.cn/tutorial/training/zh-CN/r1.2/advanced_use/distributed_training_gpu.html
==========================================================
配置容器内环境后,运行报错:
运行代码:( test_nonlinear.py )
from mindspore import context
from mindspore.communication.management import init
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
init() import numpy as np
from mindspore import dataset as ds
from mindspore import nn, Tensor, Model
import time
from mindspore.train.callback import Callback, LossMonitor, ModelCheckpoint, CheckpointConfig
from mindspore.context import ParallelMode
import mindspore as ms
ms.common.set_seed(0) start_time = time.time()
def get_data(num, a=2.0, b=3.0, c=5.0):
for _ in range(num):
x = np.random.uniform(-1.0, 1.0)
y = np.random.uniform(-1.0, 1.0)
noise = np.random.normal(0, 0.03)
z = a * x ** 2 + b * y ** 3 + c + noise
yield np.array([[x**2], [y**3]],dtype=np.float32).reshape(1,2), np.array([z]).astype(np.float32) def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['xy','z'])
input_data = input_data.batch(batch_size)
input_data = input_data.repeat(repeat_size)
return input_data data_number = 1600
batch_number = 64
repeat_number = 20 context.set_auto_parallel_context(parallel_mode=ParallelMode.DATA_PARALLEL)
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
dict_datasets = next(ds_train.create_dict_iterator()) class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(2, 1, 0.02, 0.02) def construct(self, x):
x = self.fc(x)
return x net = LinearNet()
model_params = net.trainable_params()
print ('Param Shape is: {}'.format(len(model_params)))
for net_param in net.trainable_params():
print(net_param, net_param.asnumpy())
net_loss = nn.loss.MSELoss() optim = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.6)
ckpt_config = CheckpointConfig()
ckpt_callback = ModelCheckpoint(prefix='data_parallel', config=ckpt_config) model = Model(net, net_loss, optim) epoch = 1000
#model.train(epoch, ds_train, dataset_sink_mode=True)
#model.train(epoch, ds_train, callbacks=[ckpt_callback], dataset_sink_mode=True)
model.train(epoch, ds_train, callbacks=[LossMonitor(500)], dataset_sink_mode=True) for net_param in net.trainable_params():
print(net_param, net_param.asnumpy()) print ('The total time cost is: {}s'.format(time.time() - start_time))
代码原地址:
https://www.cnblogs.com/dechinphy/p/dms.html
由于运行的服务器是有4卡泰坦服务器,因此我们的运行命令如下:
mpirun -n 4 python ./test_nonlinear.py
运行结果报错:
Failed to init nccl communicator for group
init nccl communicator for group nccl_world_group
对于上面的报错信息比较懵,不过大致可以判断是nccl的问题,
于是网上找到了一个可以打印nccl信息的操作(https://blog.csdn.net/m0_37426155/article/details/108129952)
打印nccl的日志,在环境变量里添加:
export NCCL_DEBUG=info
export NCCL_SOCKET_IFNAME=eth0
export NCCL_IB_DISABLE=1
再次运行,打印出详细的报错详细:
78244:78465 [0] NCCL INFO Call to connect returned Connection timed out, retrying
78244:78466 [1] NCCL INFO Call to connect returned Connection timed out, retrying
78244:78465 [0] NCCL INFO Call to connect returned Connection timed out, retrying
78244:78466 [1] NCCL INFO Call to connect returned Connection timed out, retrying NCCL_ERROR_SYSTEM_ERROR: unhandled system error
按照再次运行打印出的详细信息,找到这个帖子:(https://github.com/pytorch/pytorch/issues/49095)
虽然这个帖子讲的是分布式运行pytorch,但是报错信息和我这里的基本一致,由于她们实现分布式的原理和依赖的框架完全一致,由此大致判断问题相同。
比较有帮助的内容如下:
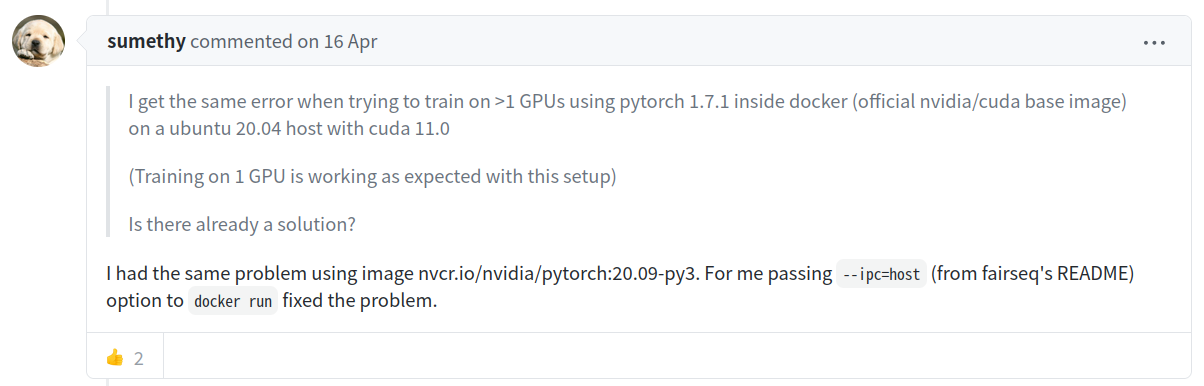

根据帖子上的解决方案就是如果使用docker容器启动,那么就需要设置项: --ipc=host
根据帖子上的方法,重新建立容器,在建立时加入设置: --ipc=host
完整命令:
sudo docker run -it --ipc=host -v /dev/shm:/dev/shm -v /data/devil/data:/data -p 7999:22 -p 8000:8000 -p 8001:8080 -p 8002:8002 -p 8003:8003 -p 8004:8004 -p 8005:8005 --runtime=nvidia --privileged=true swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu:1.2.1 /bin/bash
可以看到这个建立容器的命令与官网提供的最大区别就是加上了: --ipc=host
经过一些已经发现问题出现是由于 nccl 需要使用多进程共享内存的功能,而启动的docker容器如果不加 --ipc=host ,那么则无法使用该功能因此报错。
最终答案:
启动容器时加入: --ipc=host
=============================================================
官网提供的最新分布式说明文档地址:
MindSpore分布式并行训练 (GPU-Docker)mindspore—1.2.1—gpu—docker版本运行报错,Failed to init nccl communicator for group,init nccl communicator for group nccl_world_group的更多相关文章
- docker运行报错docker0: iptables: No chain/target/match by that name.
转自:https://blog.csdn.net/wohaqiyi/article/details/84450562 docker运行报错docker0: iptables: No chain/tar ...
- docker 报错Failed to start Docker Storage Setup. 的处理基本都是容器满了
:: localhost docker-storage-setup: Volume group extents): required. Apr :: localhost systemd: docker ...
- docker pull报错failed to register layer: Error processing tar file(exit status 1): open permission denied
近来在一个云主机上操作docker pull,报错如下: failed to register layer: Error processing ): open /etc/init.d/hwclock. ...
- docker 1.13.1 启动容器过程中mount报错
docker 1.13.1 启动container 问题 [root@openfalcon_transfer1 harbor]# docker run -it --name test busybox ...
- 【Devops】【docker】【CI/CD】jenkins 清除工作空间报错Error: Wipe Out Workspace blocked by SCM
jenkins 清除工作空间报错 错误如下: Error: Wipe Out Workspace blocked by SCM 解决方法: 进入jenkins服务器,进入workspace,手动rm ...
- 【Devops】【docker】【CI/CD】Jenkins源代码管理 添加gitlab项目地址,报错Failed to connect to repository : Error performing command: ls-remote -h git@192.168.92.130:8090/root/swapping.git HEAD
Jenkins源代码管理 添加gitlab项目地址 报错如下: Failed to connect to repository : Error performing command: ls-remot ...
- 【docker】centos7 上拉取docker镜像,一直拉取不到,报错:Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request canceled while w
镜像拉取一直报错: Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: request cancel ...
- 启动docker报错Failed to listen on Docker Socket for the API.
1.启动时报错查看日志发现 # journalctl -xe Failed to listen on Docker Socket for the API. 查找socket这个配置文件,修改如下 # ...
- 解决Pyqt打包后运行报错:应用程序无法启动 因为程序的并行配置不正确
做了一个生成二维码的小程序:http://www.cnblogs.com/dcb3688/p/4241048.html 直接运行脚本没问题,用pyinstaller打包后再运行就直接报错了: 应用程序 ...
- Docker随笔:Hyper-V PowerShell Module is not available报错解决方法
当在win10使用docker-machine创建Hyper-v虚拟机时,返回了一个错误”Error with pre-create check: "Hyper-V PowerShell M ...
随机推荐
- 在 Windows 10、Windows 11 中打开 IE 浏览器
在 Windows 10.Windows 11 中打开 IE 浏览器 新建 OpenIE.vbs 文件,输入以下内容后保存: Set OpenIE = CreateObject("Inter ...
- filebeat实战
1.打开filebeat支持nginx模块 [root@es-node1 /etc/filebeat]#ls fields.yml filebeat.reference.yml filebeat.ym ...
- 18.9k star!一个高性能的嵌入式分析型数据库,主要用于数据分析和数据处理任务。
大家好,今天给大家分享的是一个开源的面向列的关系数据库管理系统(RDBMS). DuckDB是一个嵌入式的分析型数据库,它提供了高性能的数据分析和数据处理能力.DuckDB的设计目标是为数据科学家.分 ...
- 记一次 React context 使用
学习 React 之 Context 使用 记录一次React context 使用 React.createContext Api 新建文件 contexts.js 文件用来存放 context 对 ...
- 使用python脚本玩转古早TCAD软件(待更新)
前言 TCAD(Technology Computer Aided Design),虽然原名中没有与半导体器件有关的词汇,但这种软件便是半导体工艺模拟及器件模拟的工具,可以说是EDA软件的一种.TCA ...
- pytest-allure 命令生成的报告,test body 没有具体的参数和日志
run.py: pytest.main([命令参数执行]),pytest命令执行完毕后,使用os.system()执行allure的命令 原因: 使用了命令:os.system('allure gen ...
- EasyExcel 无法读取图片?用poi写了一个工具类
在平时的开发中,经常要开发 Excel 的导入导出功能.一般使用 poi 或者 EasyExcel 开发,使用 poi 做 excel 比较复杂,大部分开发都会使用 EasyExcel 因为一行代码就 ...
- DDD 笔记
1. 简单讲讲DDD,和DDD哪些优势 领域驱动设计.就是通过领域来指导软件设计,是一种十分抽象的软件设计思想,它主要分为战略设计和战术设计 战略方面,通过事件风暴进行领域模型的划分,划分出核心域,子 ...
- CLR via C# 笔记 -- 异常和状态管理(20)
1. 异常是指成员没有完成它的名称所宣称的行动,异常类继承System.Exception. 2. .Net Framework 异常处理机制是用Microsoft windows提供的结构化异常处理 ...
- Gitbook的安装和部署
安装 npm install gitbook-cli -g gitbook命令: gitbook init //初始化目录文件 gitbook help //列出gitbook所有的命令 gitboo ...