cloudpickle —— Python分布式序列化的专用模块
给出cloudpickle的GitHub地址:
https://github.com/cloudpipe/cloudpickle
=======================================================
单机的Python序列化模块有自带的pickle,但是在Python的分布式计算中进行序列化则是使用cloudpickle。之所以在分布式计算中Python的序列化使用cloudpickle模块的原因有:
1. cloudpickle是使用value序列化的方式,而pickle则是使用reference序列化的方式。因此在反序列化时pickle需要运行环境内存在序列化对象的定义,因为pickle进行序列化的只是对象(函数、类对象)的参数;而cloudpickle在序列化时会把对象的定义和参数值一并序列化,所以在分布式计算中传递cloudpickle序列化对象时接受方可以没有对象的定义(如果序列化的是类对象,那么接收方可以没有类的定义)。
例子:
import pickle class A():pass a=A() a_pick = pickle.dumps(a)
a_unpick = pickle.loads(a_pick)
print(a_unpick) del A
b_unpick = pickle.loads(a_pick)

import cloudpickle as pickle class A():pass a=A() a_pick = pickle.dumps(a)
a_unpick = pickle.loads(a_pick)
print(a_unpick) del A
b_unpick = pickle.loads(a_pick)

--------------------------------------------------------
import cloudpickle, pickle CONSTANT = 42
def my_function(data: int) -> int:
return data + CONSTANT pickled_function = cloudpickle.dumps(my_function)
pickled_function_2 = pickle.dumps(my_function) CONSTANT = 0
depickled_function = cloudpickle.loads(pickled_function)
depickled_function_2 = pickle.loads(pickled_function_2) print(depickled_function(43))
print(depickled_function_2(43))

2. pickle模块不能序列化lambda函数,cloudpickle可以序列化lambda函数。
例子:
import pickle
squared = lambda x: x ** 2
pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda)
new_squared(2)

import cloudpickle as pickle
squared = lambda x: x ** 2
pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda)
new_squared(2)

===========================================
从上面的例子可以看出,cloudpickle更像是打包序列化,在序列化一个对象时会把该对象设计到的参数和定义也一并打包进行序列化。那么cloudpickle有没有打包不了的对象呢,这个确实还是有的,那就是序列化对象(函数、类对象)中如果包含有import语句的并不会把import语句中所涉及的对象进行一并打包。对于cloudpickle不能把序列化对象中包含的import引入的对象一并打包这个事情我个人的观点是其实现的难点在于import对象中会涉及大量的对象,这样进行一并打包要包含哪些对象难以确定、并且全部打包也是会造成序列化后对象字节码过长、序列化用时过长等问题。
例子:
模块: another_module.py

def g():
print("hello world")
return 100
模块 x.py:
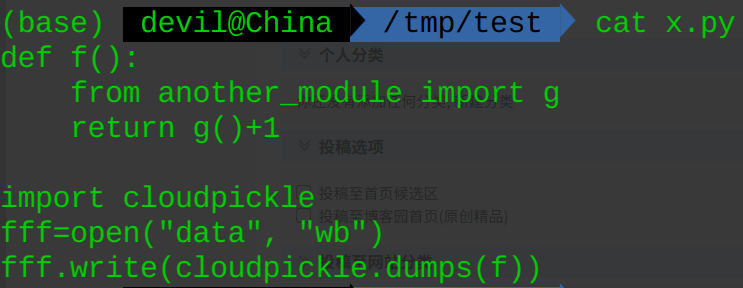
def f():
from another_module import g
return g()+1 import cloudpickle
fff=open("data", "wb")
fff.write(cloudpickle.dumps(f))
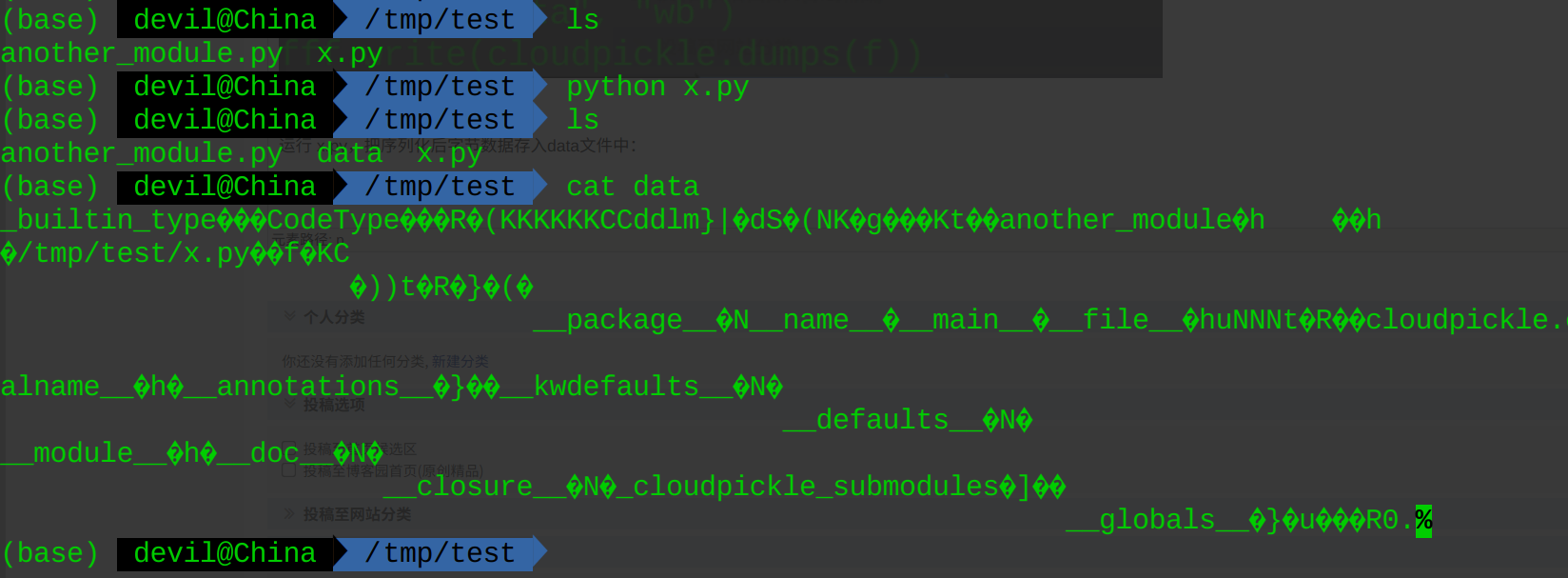
运行 x.py,把序列化后字节数据存入data文件中:
----------------------------------
给出反序列化文件 y.py:
import cloudpickle
fff=open("abc", "rb")
f = cloudpickle.loads(fff.read())
f()
如果把序列化文件data和反序列化文件y.py放在另一个单独的文件夹中并运行y.py,结果如下:
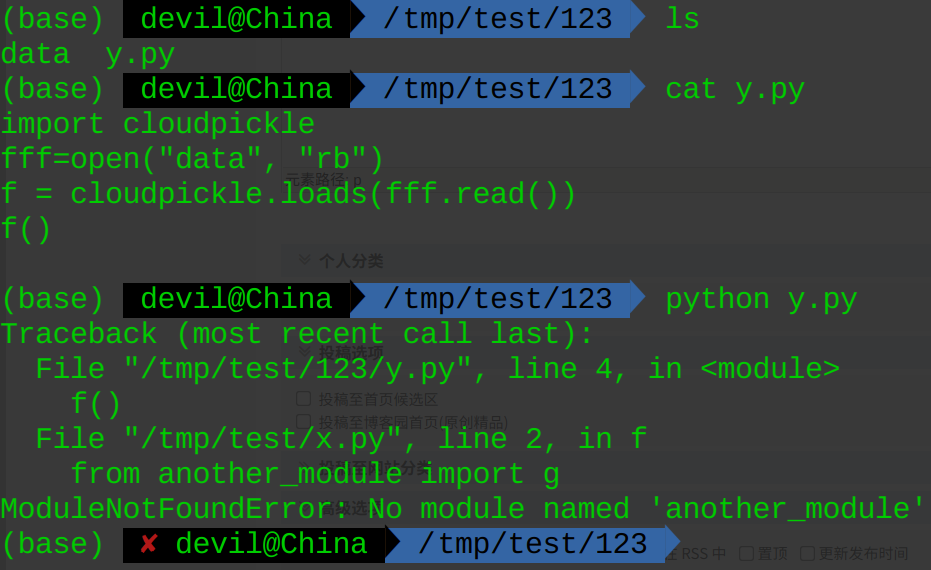
可以看到,使用cloudpickle并没有把涉及到的import语句中引入的对象进行一并的打包序列化。
PS: cloudpickle的底层实现依旧是调用pickle模块,可以说cloudpickle模块是对pickle模块的进一步包装,其实现的功能就是把pickle序列化中没有打包的对象以value的形式进行一并打包。
====================================================
cloudpickle —— Python分布式序列化的专用模块的更多相关文章
- Python:序列化 pickle JSON
序列化 在程序运行的过程中,所有的变量都储存在内存中,例如定义一个dict d=dict(name='Bob',age=20,score=88) 可以随时修改变量,比如把name修改为'Bill',但 ...
- Python库:序列化和反序列化模块pickle介绍
1 前言 在“通过简单示例来理解什么是机器学习”这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 通过简单示例来理解什么是机器学习 pickle是python语言的一个标准模块,安装pyt ...
- python 序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- python之序列化模块、双下方法(dict call new del len eq hash)和单例模式
摘要:__new__ __del__ __call__ __len__ __eq__ __hash__ import json 序列化模块 import pickle 序列化模块 补充: 现在我们都应 ...
- Python基础(正则、序列化、常用模块和面向对象)-day06
写在前面 上课第六天,打卡: 天地不仁,以万物为刍狗: 一.正则 - 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法: - 在线正则工具:http://tool ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- python模块知识二 random -- 随机模块、序列化 、os模块、sys -- 系统模块
4.random -- 随机模块 a-z:97 ~ 122 A-Z :65 ~ 90 import random #浮点数 print(random.random())#0~1,不可指定 print( ...
- Python 序列化 pickle/cPickle模块
Python 序列化 pickle/cPickle模块 2013-10-17 Posted by yeho Python序列化的概念很简单.内存里面有一个数据结构,你希望将它保存下来,重用,或者发送给 ...
- python序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- [python] Python数据序列化模块pickle使用笔记
pickle是一个Python的内置模块,用于在Python中实现对象结构序列化和反序列化.Python序列化是一个将Python对象层次结构转换为可以本地存储或者网络传输的字节流的过程,反序列化则是 ...
随机推荐
- k8s配置文件管理
1.为什么要用configMap ConfigMap是一种用于存储应用所需配置信息的资源类型,用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件. 通过ConfigMap可以方便的 ...
- Prometheus + Grafana (2) mysql、redis、Docker容器、服务端点以及预警
接着上一节 <Prometheus + Grafana (1) 监控 >,我们继续探讨 Prometheus + Grafana 的复杂应用 实现目标 这节我们的目标是搭建一个多维度监控微 ...
- Java线程池maximumPoolSize和workQueue哪个先饱和?
先说结论,真正的饱和顺序是corePoolSize -> workQueue -> maximumPoolSize. 我们都知道,线程池有以下参数 ThreadPoolExecutor(i ...
- Java服务发起HTTPS请求报错:PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException
Java服务发起HTTPS请求报错:PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderExcept ...
- 利用 device_map、torch.dtype、bitsandbytes 压缩模型参数控制使用设备
为了更好的阅读体验,请点击这里 device_map 以下内容参考 Huggingface Accelerate文档:超大模型推理方法 在 HuggingFace 中有个重要的关键字是 device_ ...
- 【BUG记录】Cause: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x90\xA6' for column 'name' at row 1
大家好呀,我是summo,这次的文章标题是一个Mysql数据库的SQL错误,遇到的同学自然懂,没遇到的同学希望你永远也不要遇到. 一.错误说明 Cause: java.sql.SQLException ...
- ROS让机器人开发更便捷,基于RK3568J+Debian系统发布!
ROS系统是什么 ROS(Robot Operating System)是一个适用于机器人的开源的元操作系统.它提供了操作系统应有的服务,包括硬件抽象,底层设备控制,常用函数的实现,进程间消息传递,以 ...
- Linux 鉴定故障
导读 进入linux,输入root账户,密码输入是正确的,提示"鉴定故障",刚开始以为是系统挂了,后来百度说,需要重置root密码,具体步骤如下. 重置root密码 重启Linux ...
- Task异步多线程
不废话,直接贴上要实现的效果和代码... [1]直接使用Lambda表达式是实现多线程: using System; using System.Collections.Generic; using S ...
- Python 华为云OSS建桶与文件上传下载删除及检索示例
华为云OSS建桶与文件上传下载删除及检索示例 实践环境 运行环境: Python 3.5.4 CentOS Linux release 7.4.1708 (Core)/Win10 需要安装以下类库: ...