Prometheus + Grafana (2) mysql、redis、Docker容器、服务端点以及预警
接着上一节 《Prometheus + Grafana (1) 监控 》,我们继续探讨 Prometheus + Grafana 的复杂应用
实现目标
这节我们的目标是搭建一个多维度监控微服务的可视化平台,包括Docker容器监控、MySQL监控、Redis监控和微服务JVM监控等,并且在必要的情况下可以发送预警邮件。
主要用到的组件有Prometheus、Grafana、alertmanager、node_exporter、mysql_exporter、redis_exporter、cadvisor。各自作用如下所示:
- Prometheus:获取、存储监控数据,供第三方查询;
- Grafana:提供Web页面,从Prometheus获取监控数据可视化展示;
- alertmanager:定义预警规则,发送预警信息;
- node_exporter:收集微服务端点监控数据(与Prometheus一套);
- mysql_exporter:收集MySQL数据库监控数据;
- redis_exporter:收集Redis监控数据;
- cadvisor:收集Docker容器监控数据。
使用docker安装 Grafana、Prometheus及监控服务
上一节我们是直接使用的Windows下的安装软件安装Grafana和Prometheus,但是在我们的日常生产=环境中多是用的Linux,所以我们选择了方便的docker进行安装部署。
- 在自己的挂载目录下创建 prometheus.yml
#创建Prometheus挂载目录
mkdir -p /dimples/volumes/prometheus
#在该目录下创建Prometheus配置文件
vim /dimples/volumes/prometheus/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- 在自己的挂载目录下创建 alertmanager.yml
global:
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '1126834403@qq.com'
smtp_auth_username: '1126834403@qq.com'
# qq邮箱获取的授权码
smtp_auth_password: 'xxxxxxxxxxxxxxxxx'
smtp_require_tls: false
#templates:
# - '/alertmanager/template/*.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 5m
repeat_interval: 5m
receiver: 'default-receiver'
receivers:
- name: 'default-receiver'
email_configs:
- to: '2119713895@qq.com'
send_resolved: true
- 创建创建 docker-compose.yml 文件
version: '3'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- /dimples/volumes/prometheus/:/etc/prometheus/
ports:
- 9090:9090
restart: on-failure
command:
- '--web.enable-lifecycle '
grafana:
image: grafana/grafana
container_name: grafana
ports:
- 3000:3000
node_exporter:
image: prom/node-exporter
container_name: node_exporter
ports:
- 9100:9100
redis_exporter:
image: oliver006/redis_exporter
container_name: redis_exporter
command:
- "--redis.addr=redis://127.0.0.1:6379"
- "--redis.password 'ZHONG9602.class'" # 认证密码,如果没有密码,该参数不需要
ports:
- 9101:9121
restart: on-failure
mysql_exporter:
image: prom/mysqld-exporter
container_name: mysql_exporter
environment:
- DATA_SOURCE_NAME=root:123456@(127.0.0.1:3306)/
ports:
- 9102:9104
cadvisor:
image: google/cadvisor
container_name: cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- 9103:8080
alertmanager:
image: prom/alertmanager
container_name: alertmanager
volumes:
- /dimples/volumes/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- 9104:9093
使用 docker-compose up -d 启动服务
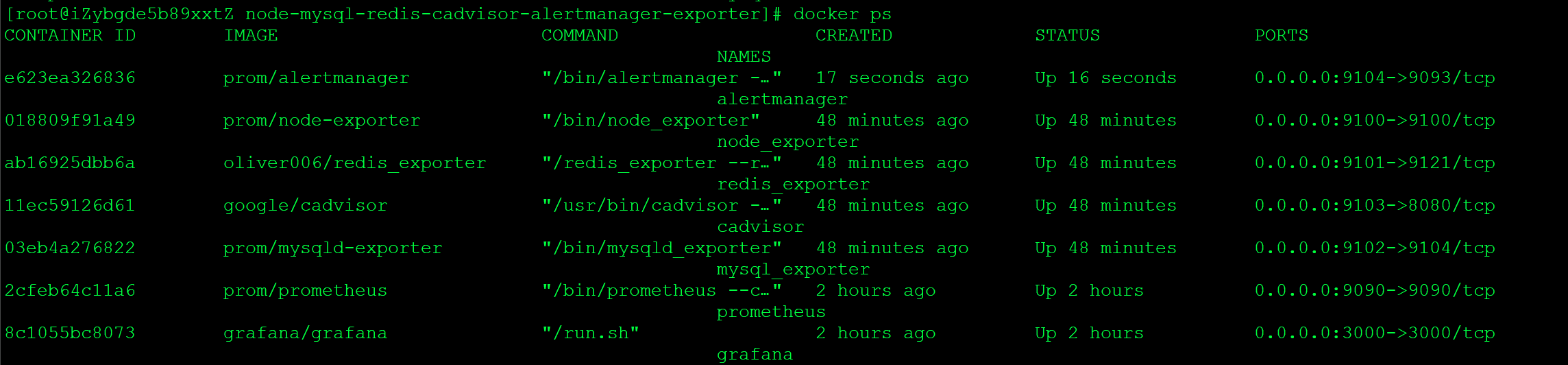
# 不使用docker-compose安装
docker run -d --name prometheus -p 9090:9090 -v /dimples/volumes/prometheus/:/etc/prometheus/ prom/prometheus --config.file=/etc/prometheus/prometheus.yml --web.enable-lifecycle
docker run -d --name redis_exporter -p 9101:9121 oliver006/redis_exporter --redis.addr redis://127.0.0.1:6379 --redis.password 'ZHONG9602.class'
- 测试是否监控到数据
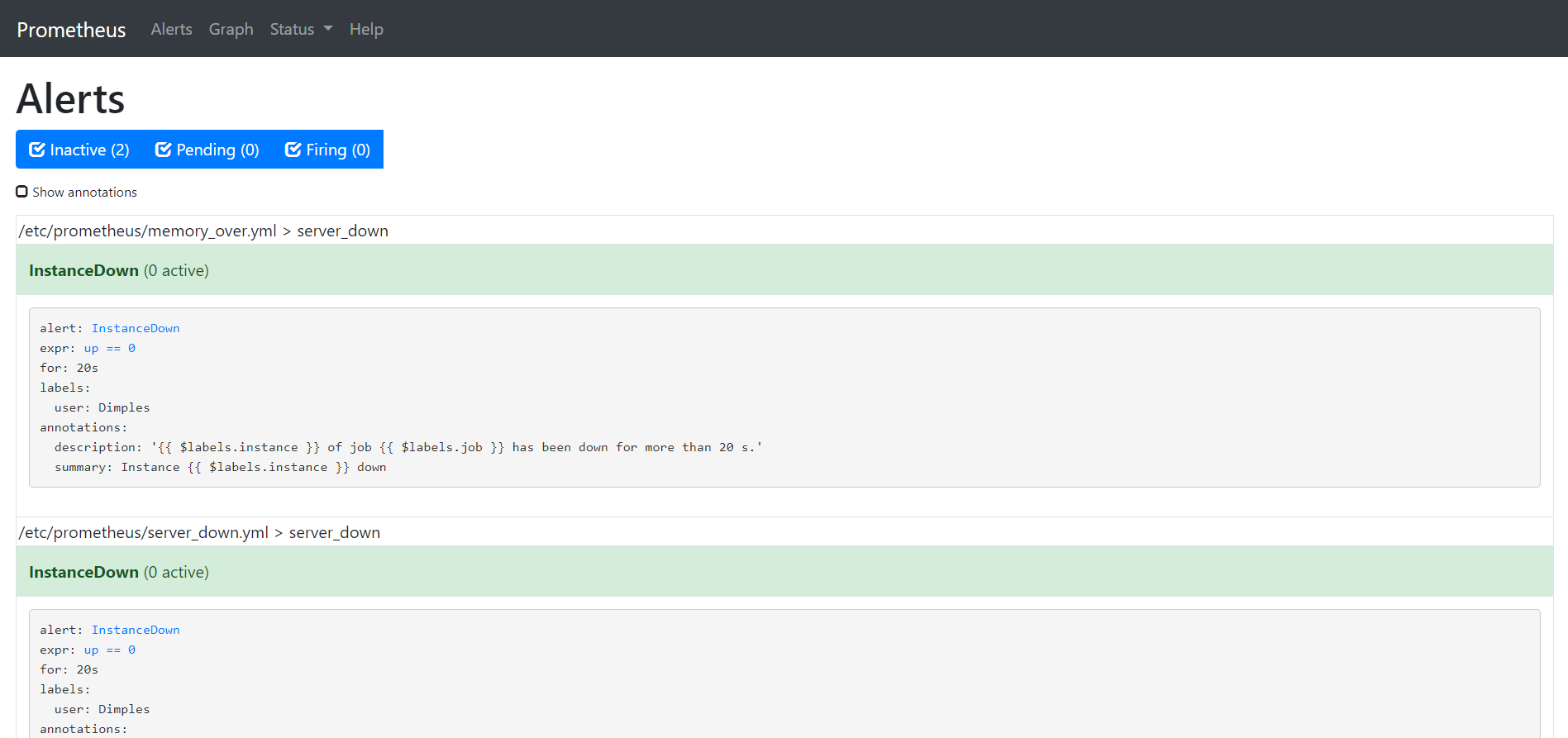
如上图所示,我们刚刚定义的两个警告规则已经成功加载
接着访问 http://127.0.0.1:9090/targets 观察在Prometheus配置文件里定义的各个job的状态:
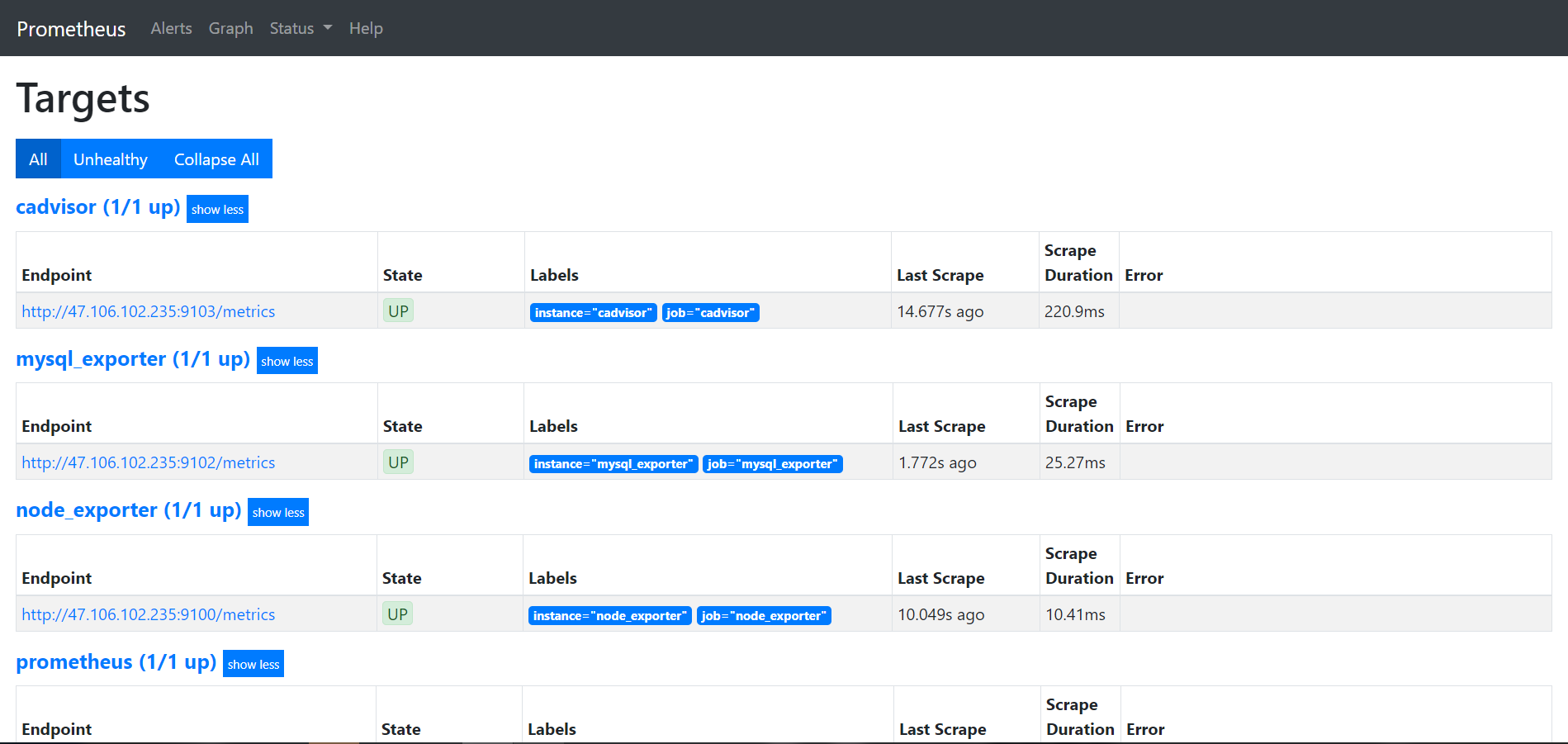
可以看的都是监控的UP状态。
还可以点击上面这个页面的各个 Endpoint 的链接,如果页面显示出了收集的数据,则说明各个Endpoint已经成功采集到了数据,以mysql_exporter为例子,访问
http://127.0.0.1:9102/metrics
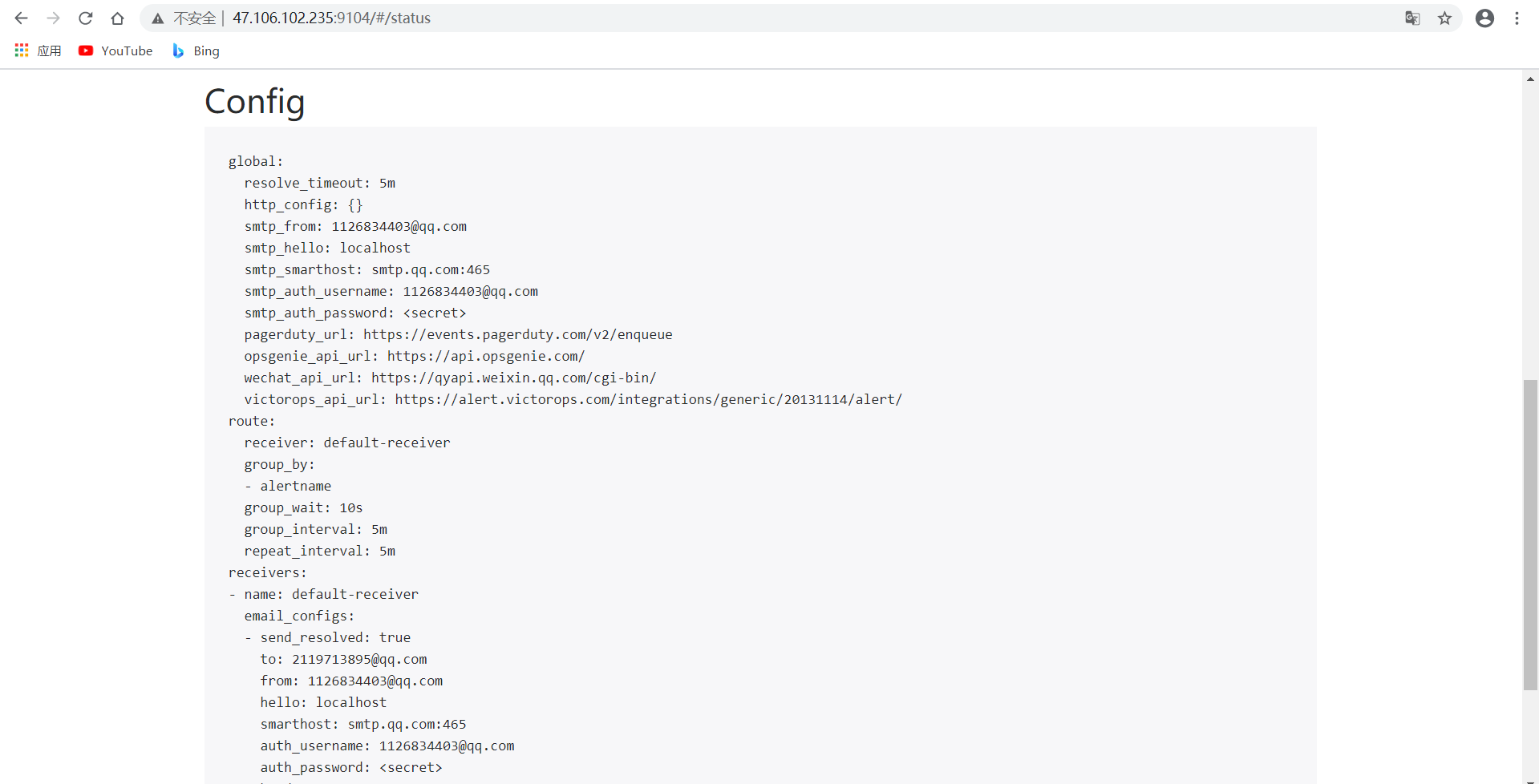
访问http://127.0.0.1:9104/#/status看看我们在alertmanager.yml配置的规则是否已经生效:
配置Java程序监控
在上面的配置中我们简单的将Prometheus采集的对于自身的数据通过Grafana进行了展示,而我们的核心是通过Prometheus去采集Java应用的数据,这就需要针对前面提到的通过Prometheus的pull模式定时去拉取SpringBoot通过Actuator暴露的Micrometer采集的监控指标
- 首先需要的做的是完成Java应用的Micrometer集成,访问actuator/prometheus或者/prometheus能够正常的返回Micrometer采集的数据指标(这一步操作在上节中已经很详细的介绍了,此处不再赘述)
- 进入部署Prometheus的文件目录,打prometheus.yml进行拉取节点的配置,在配置文件的scrape_configs节点添加针对java的配置
修改 prometheus.yml 配置所有监控服务
在上面启动的 prometheus,我们没有配置任何的监控,所以我们要修改 prometheus.yml 文件,使其监控我们想监控的数据源,具体的修改内容如下图所示
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['127.0.0.1:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['127.0.0.1:9100']
labels:
instance: 'node_exporter'
- job_name: 'redis_exporter'
static_configs:
- targets: ['127.0.0.1:9101']
labels:
instance: 'redis_exporter'
- job_name: 'mysql_exporter'
static_configs:
- targets: ['127.0.0.1:9102']
labels:
instance: 'mysql_exporter'
- job_name: 'cadvisor'
static_configs:
- targets: ['127.0.0.1:9103']
labels:
instance: 'cadvisor'
- job_name: 'server-demo-actuator'
metrics_path: '/actuator/prometheus'
scrape_interval: 5s
static_configs:
- targets: ['127.0.0.1:8001']
labels:
instance: 'server-demo'
rule_files:
- 'memory_over.yml'
- 'server_down.yml'
alerting:
alertmanagers:
- static_configs:
- targets: ["127.0.0.1:9104"]
PS: 每个服务的targets都是一个数组,可以收集多个服务器下的exporter提供的监控数据。
接着创建上面提到的两个监控规则 memory_over.yml 和 server_down.yml
# 创建 memory_over.yml
vim /dimples/volumes/prometheus/memory_over.yml
内容如下:
groups:
- name: server_down
rules:
- alert: InstanceDown
expr: up == 0
for: 20s
labels:
user: Dimples
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 20 s."
当某个节点的内存使用率大于80%,并且持续时间大于20秒后,触发监控预警。
接着创建 server_down.yml:
# server_down.yml
vim /dimples/volumes/prometheus/server_down.yml
内容如下:
groups:
- name: server_down
rules:
- alert: InstanceDown
expr: up == 0
for: 20s
labels:
user: Dimples
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 20 s."
当某个节点宕机(up==0表示宕机,1表示正常运行)超过20秒后,则触发监控。
在 Grafana 中使用
使用浏览器访问 http://127.0.0.1:9090,用户名密码为admin/admin,首次登录需要修改密码。
第一步:首先需要添加数据源,上一节中已经详细介绍过了,此处不再赘述,结果如图:
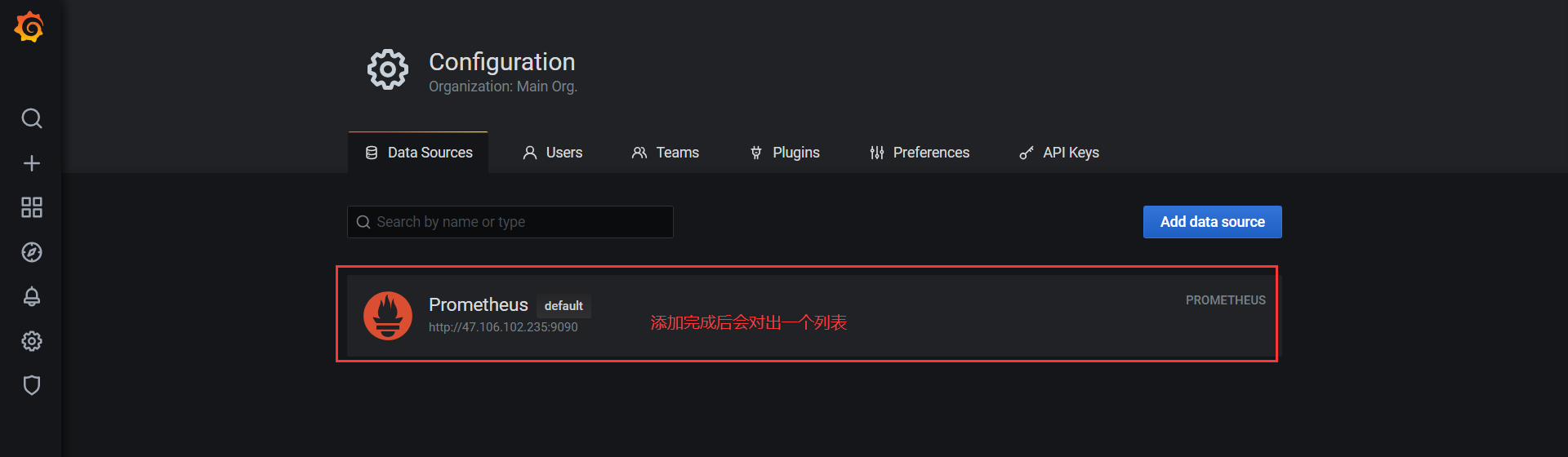
添加数据源成功后,我们就可以添加监控面板了,同样的,我们可以去Grafana官方市场选择别人配置好的模板:https://grafana.com/grafana/dashboards
此处我收集了几个好用的监控模板,已经上传到微云网盘,只需要下载然后导入即可( 链接:https://share.weiyun.com/XDzICKtf )
下面以 MySql 监控为例,演示导入模板:
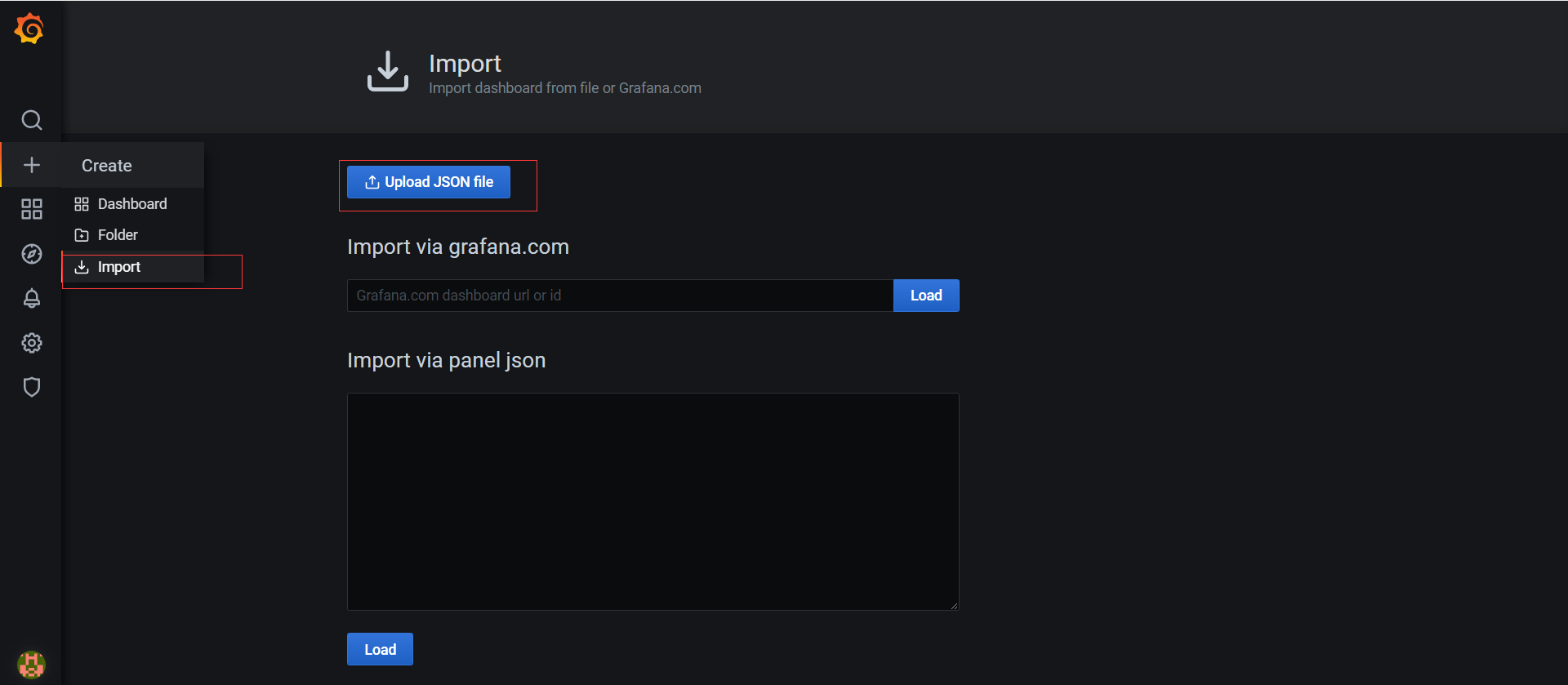
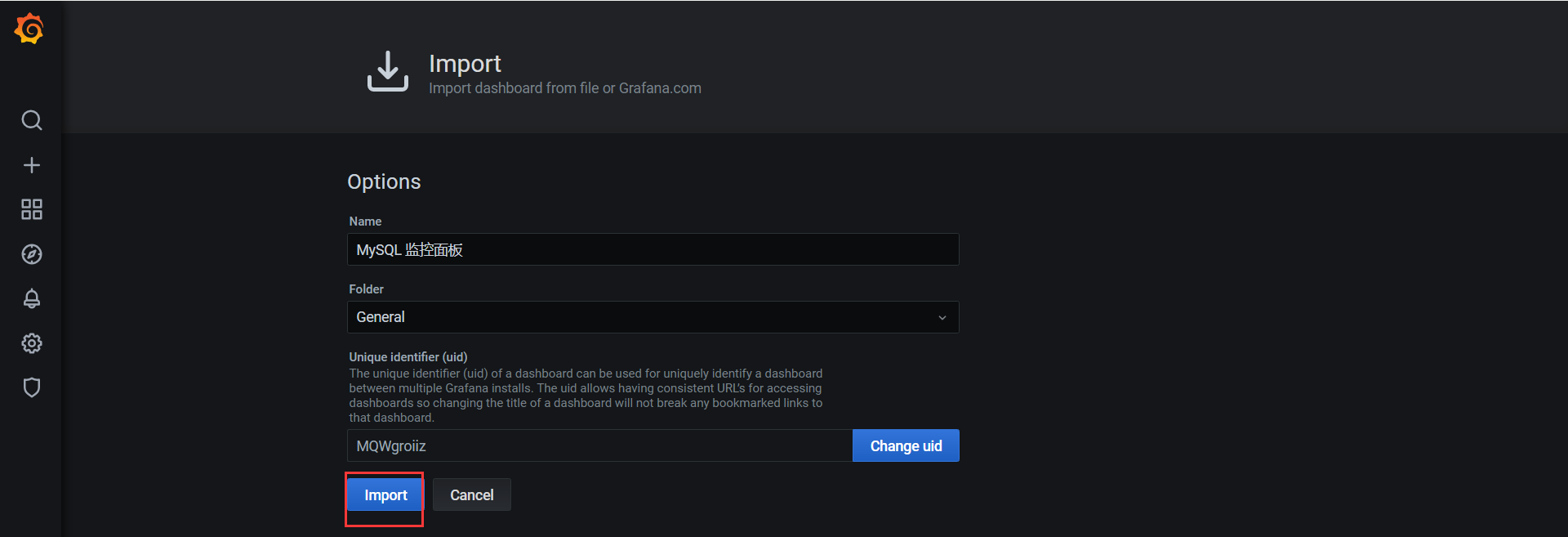
点击 Upload JSON file 后,选择对应的文件,成功后会自动弹出一下界面,然后点击Import
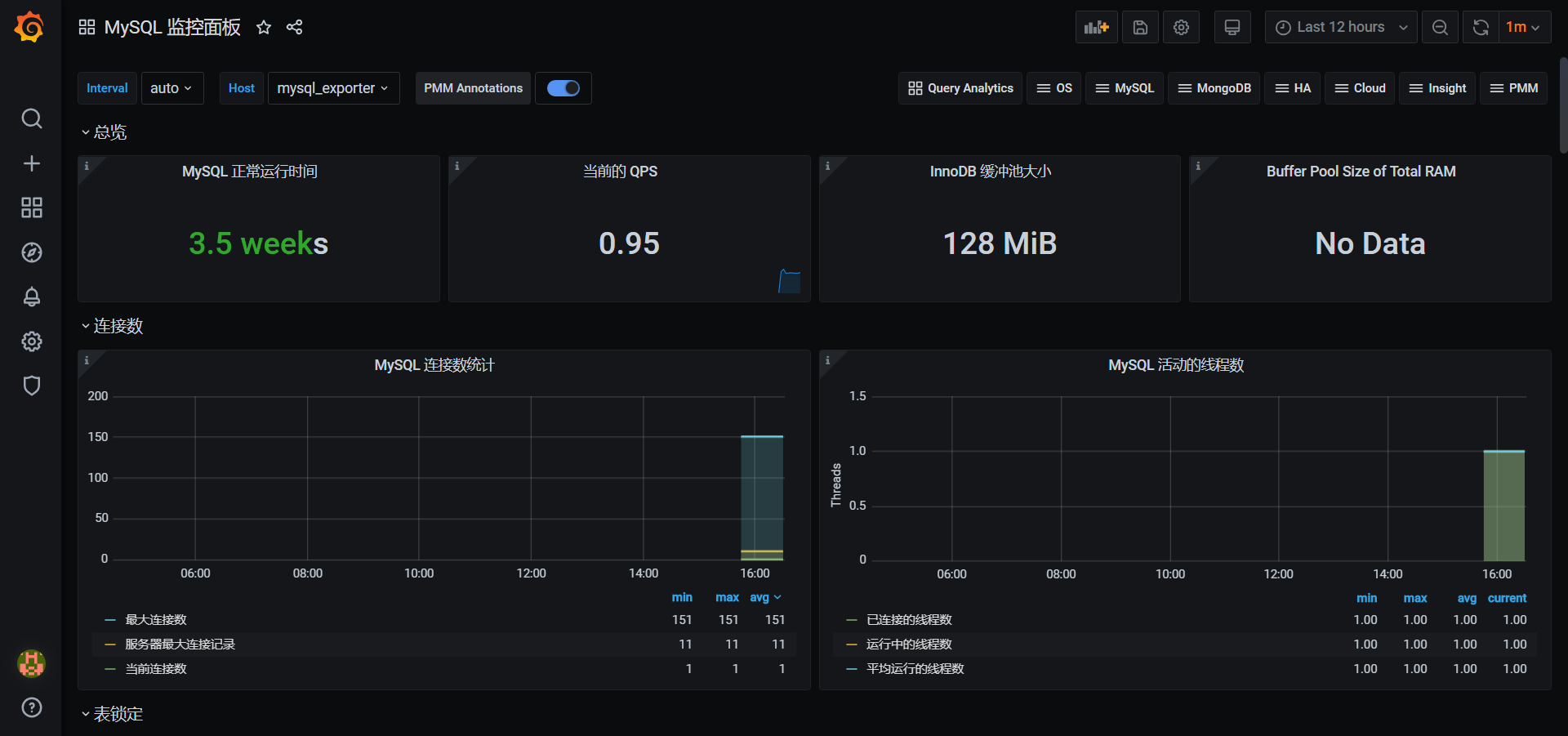
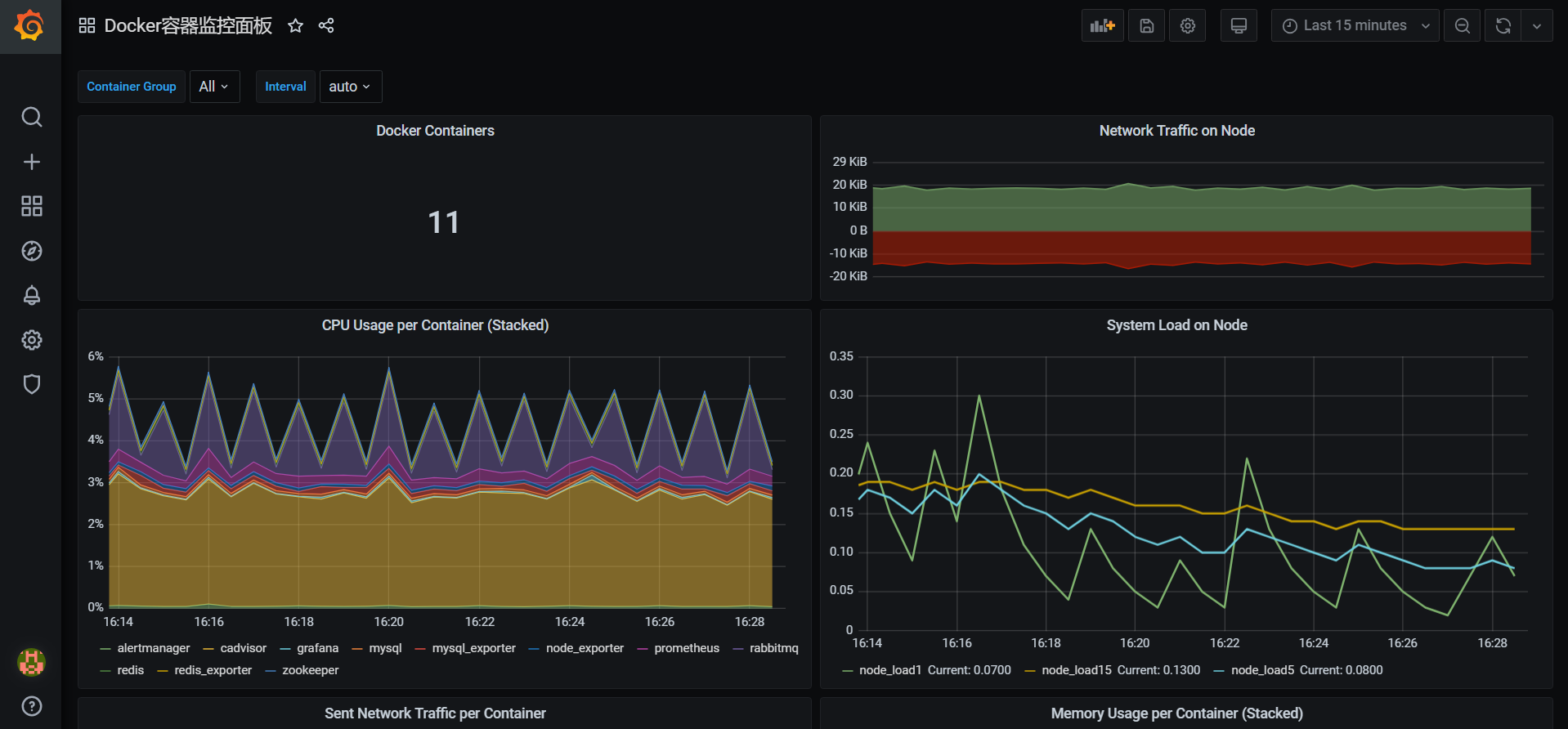
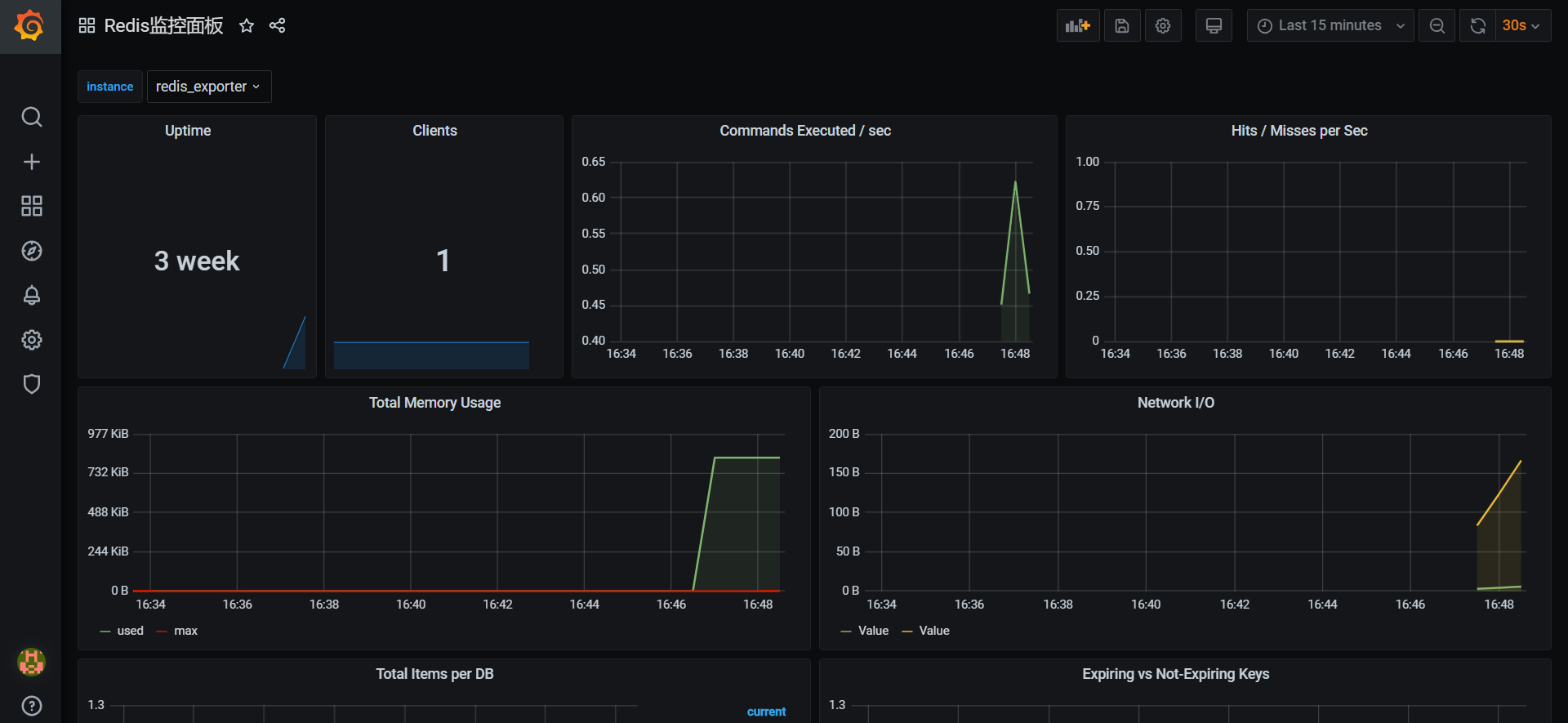
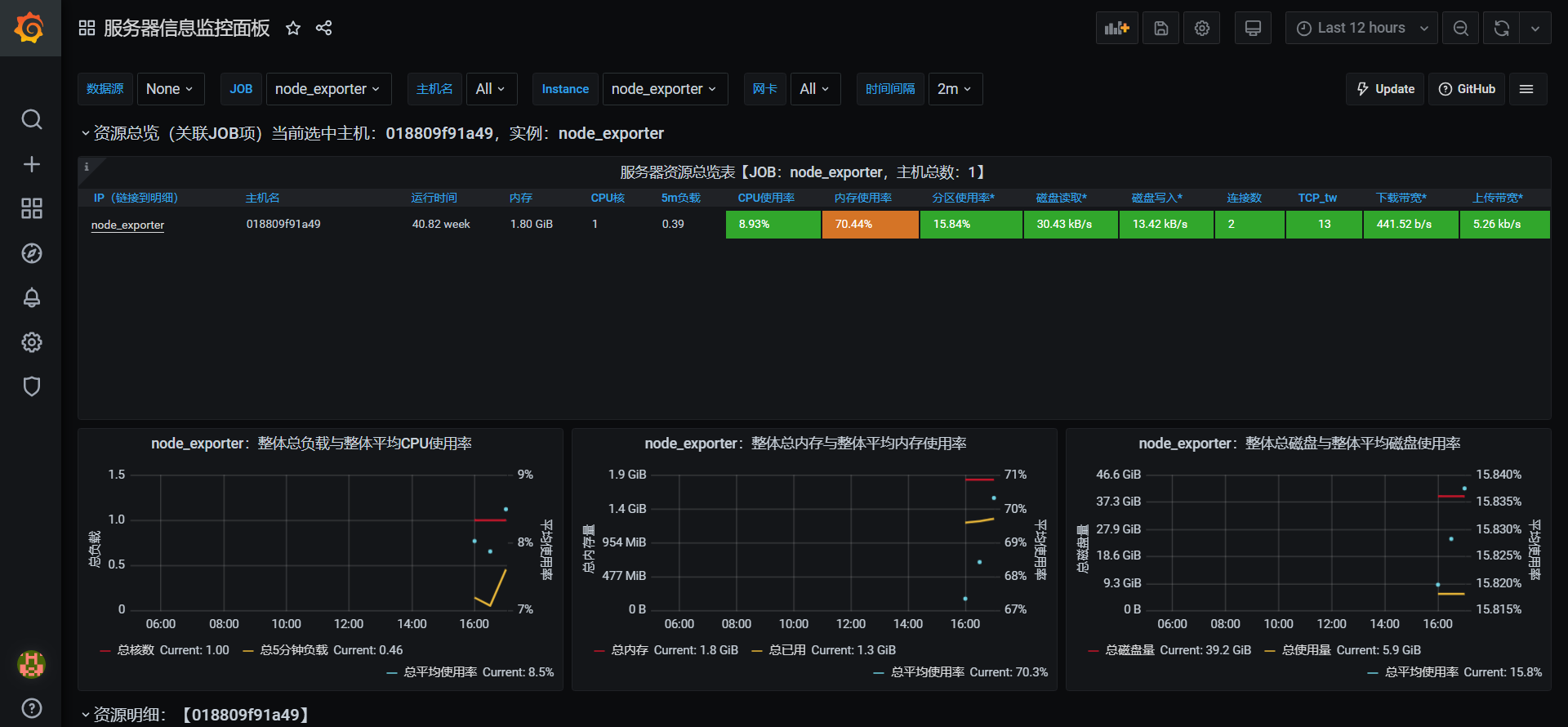
额外补充
alertmanager 丰富的预警配置
groups:
- name: example #定义规则组
rules:
- alert: InstanceDown #定义报警名称
expr: up == 0 #Promql语句,触发规则
for: 1m # 一分钟
labels: #标签定义报警的级别和主机
name: instance
severity: Critical
annotations: #注解
summary: " {{ $labels.appname }}" #报警摘要,取报警信息的appname名称
description: " 服务停止运行 " #报警信息
value: "{{ $value }}%" # 当前报警状态值
- name: Host
rules:
- alert: HostMemory Usage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
name: Memory
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机内存使用率超过80%."
value: "{{ $value }}"
- alert: HostCPU Usage
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance,appname) > 0.65
for: 1m
labels:
name: CPU
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机CPU使用率超过65%."
value: "{{ $value }}"
- alert: HostLoad
expr: node_load5 > 4
for: 1m
labels:
name: Load
severity: Warning
annotations:
summary: "{{ $labels.appname }} "
description: " 主机负载5分钟超过4."
value: "{{ $value }}"
- alert: HostFilesystem Usage
expr: 1-(node_filesystem_free_bytes / node_filesystem_size_bytes) > 0.8
for: 1m
labels:
name: Disk
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [ {{ $labels.mountpoint }} ]分区使用超过80%."
value: "{{ $value }}%"
- alert: HostDiskio
expr: irate(node_disk_writes_completed_total{job=~"Host"}[1m]) > 10
for: 1m
labels:
name: Diskio
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}]磁盘1分钟平均写入IO负载较高."
value: "{{ $value }}iops"
- alert: Network_receive
expr: irate(node_network_receive_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 3
for: 1m
labels:
name: Network_receive
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}] 网卡5分钟平均接收流量超过3Mbps."
value: "{{ $value }}3Mbps"
- alert: Network_transmit
expr: irate(node_network_transmit_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 3
for: 1m
labels:
name: Network_transmit
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [{{ $labels.device }}] 网卡5分钟内平均发送流量超过3Mbps."
value: "{{ $value }}3Mbps"
- name: Container
rules:
- alert: ContainerCPU Usage
expr: (sum by(name,instance) (rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 60
for: 1m
labels:
name: CPU
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: " 容器CPU使用超过60%."
value: "{{ $value }}%"
- alert: ContainerMem Usage
# expr: (container_memory_usage_bytes - container_memory_cache) / container_spec_memory_limit_bytes * 100 > 10
expr: container_memory_usage_bytes{name=~".+"} / 1048576 > 1024
for: 1m
labels:
name: Memory
severity: Warning
annotations:
summary: "{{ $labels.name }} "
description: " 容器内存使用超过1GB."
value: "{{ $value }}G"
预警除了使用邮件外,也可以使用企业微信接收,可以参考:https://songjiayang.gitbooks.io/prometheus/content/alertmanager/wechat.html
Prometheus + Grafana (2) mysql、redis、Docker容器、服务端点以及预警的更多相关文章
- [转帖]安装prometheus+grafana监控mysql redis kubernetes等
安装prometheus+grafana监控mysql redis kubernetes等 https://www.cnblogs.com/sfnz/p/6566951.html plug 的模式进行 ...
- 安装prometheus+grafana监控mysql redis kubernetes等
1.prometheus安装 wget https://github.com/prometheus/prometheus/releases/download/v1.5.2/prometheus-1.5 ...
- 记一次使用Asp.Net Core WebApi 5.0+Dapper+Mysql+Redis+Docker的开发过程
#前言 我可能有三年没怎么碰C#了,目前的工作是在全职搞前端,最近有时间抽空看了一下Asp.net Core,Core版本号都到了5.0了,也越来越好用了,下面将记录一下这几天以来使用Asp.Net ...
- egg 连接 mysql 的 docker 容器,报错:Client does not support authentication protocol requested by server; consider upgrading MySQL client
egg 连接 mysql 的 docker 容器,报错:Client does not support authentication protocol requested by server; con ...
- prometheus+grafana监控mysql
prometheus+grafana监控mysql 1.安装配置MySQL官方的 Yum Repository(有mysql只需设置监控账号即可) [root@localhost ~]# wget - ...
- 远见而明察近观若明火|Centos7.6环境基于Prometheus和Grafana结合钉钉机器人打造全时监控(预警)Docker容器服务系统
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_181 我们知道,奉行长期主义的网络公司,势必应在软件开发流程管理体系上具备规范意识,即代码提交有CR(CodeReview),功能 ...
- Prometheus+Grafana监控MySQL、Redis数据库
俗话说,没有监控的系统就是在裸奔,好的监控就是运维人员的第三只手,第三只眼.本文将使用prometheus及Grafana搭建一套监控系统来监控主机及数据库(MySQL.Redis). 1. 安装G ...
- 基于Centos7.4搭建prometheus+grafana+altertManger监控Spring Boot微服务(docker版)
目的:给我们项目的微服务应用都加上监控告警.在这之前你需要将 Spring Boot Actuator引入 本章主要介绍 如何集成监控告警系统Prometheus 和图形化界面Grafana 如何自定 ...
- Prometheus + Grafana 监控(mysql 和redis)
1.监控MySQL(mysqld-exporter) https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/m ...
- 使用Prometheus+Grafana监控MySQL实践
一.介绍Prometheus Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的.随着发展,越来越多公司和组织接受采 ...
随机推荐
- 深度解析|基于 eBPF 的 Kubernetes 一站式可观测性系统
简介:阿里云 Kubernetes 可观测性是一套针对 Kubernetes 集群开发的一站式可观测性产品.基于 Kubernetes 集群下的指标.应用链路.日志和事件,阿里云 Kubernete ...
- 逸仙电商Seata企业级落地实践
简介: 本文将会以逸仙电商的业务作为背景, 先介绍一下seata的原理, 并给大家进行线上演示, 由浅入深去介绍这款中间件, 以便读者更加容易去理解 Seata 这个中间件. 作者 | 张嘉伟(Git ...
- dotnet 警惕判断文件是否存在因为检查网络资源造成超长等待
在使用 System.IO.File.Exists 方法时,绝大部分的情况下都是一个非常快捷且没有成本的,但是如果判断的文件是否存在,是从非自己完全控制的逻辑下进入的,那就需要警惕是否判断的文件路径属 ...
- WPF 自定义控件入门 Focusable 与焦点
自定义控件时,如果自定义的控件需要用来接收键盘消息或者是输入法的输入内容,那就需要关注到控件的焦点 默认情况下的自定义控件是没有带可获取焦点的功能的,例如编写一个继承 FrameworkElement ...
- WPF 通过 Windows Template Studio 快速搭建项目框架和上手项目
本文对新手友好.在咱开始一个新项目的时候,可以利用 Windows Template Studio 快速搭建整个项目的框架.搭建出来的框架比较现代化,适合想要快速开发一个项目的大佬使用,也适合小白入门 ...
- 【OpenVINO™】基于 C# 和 OpenVINO™ 部署 Blazeface 模型实现人脸检测
前言 OpenVINO C# API 是一个 OpenVINO 的 .Net wrapper,应用最新的 OpenVINO 库开发,通过 OpenVINO C API 实现 .Net 对 OpenV ...
- gorm使用小结
增 db.Create(user) db.Save(user) 参数只能用**结构体指针****,因为要根据指针写入该条插入的数据, 所以user可以作为该条数据使用. 新增只能用结构体 save方法 ...
- LVS负载均衡(2)-- NAT模型搭建实例
目录 1. LVS NAT模型搭建 1.1 NAT模型网络规划 1.2 NAT模型访问流程 1.3 NAT模型配置步骤 1.3.1 ROUTER设备配置 1.3.2 后端nginx服务器配置 1.3. ...
- C 语言编程 — 堆栈与内存管理
目录 文章目录 目录 前文列表 栈(Stack)和堆(Heap) 栈 堆 内存管理 动态分配内存 重新调整内存的大小和释放内存 前文列表 <程序编译流程与 GCC 编译器> <C 语 ...
- 文件系统(四):FAT32文件系统实现原理
FAT32是从FAT12.FAT16发展而来,目前主要应用在移动存储设备中,比如SD卡.TF卡.隐藏的FAT文件系统现在也有被大量使用在UEFI启动分区中. 为使文章简单易读,下面内容特意隐藏了很多实 ...