cloudpickle —— Python分布式序列化的专用模块
给出cloudpickle的GitHub地址:
https://github.com/cloudpipe/cloudpickle
=======================================================
单机的Python序列化模块有自带的pickle,但是在Python的分布式计算中进行序列化则是使用cloudpickle。之所以在分布式计算中Python的序列化使用cloudpickle模块的原因有:
1. cloudpickle是使用value序列化的方式,而pickle则是使用reference序列化的方式。因此在反序列化时pickle需要运行环境内存在序列化对象的定义,因为pickle进行序列化的只是对象(函数、类对象)的参数;而cloudpickle在序列化时会把对象的定义和参数值一并序列化,所以在分布式计算中传递cloudpickle序列化对象时接受方可以没有对象的定义(如果序列化的是类对象,那么接收方可以没有类的定义)。
例子:
import pickle class A():pass a=A() a_pick = pickle.dumps(a)
a_unpick = pickle.loads(a_pick)
print(a_unpick) del A
b_unpick = pickle.loads(a_pick)

import cloudpickle as pickle class A():pass a=A() a_pick = pickle.dumps(a)
a_unpick = pickle.loads(a_pick)
print(a_unpick) del A
b_unpick = pickle.loads(a_pick)

--------------------------------------------------------
import cloudpickle, pickle CONSTANT = 42
def my_function(data: int) -> int:
return data + CONSTANT pickled_function = cloudpickle.dumps(my_function)
pickled_function_2 = pickle.dumps(my_function) CONSTANT = 0
depickled_function = cloudpickle.loads(pickled_function)
depickled_function_2 = pickle.loads(pickled_function_2) print(depickled_function(43))
print(depickled_function_2(43))

2. pickle模块不能序列化lambda函数,cloudpickle可以序列化lambda函数。
例子:
import pickle
squared = lambda x: x ** 2
pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda)
new_squared(2)

import cloudpickle as pickle
squared = lambda x: x ** 2
pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda)
new_squared(2)

===========================================
从上面的例子可以看出,cloudpickle更像是打包序列化,在序列化一个对象时会把该对象设计到的参数和定义也一并打包进行序列化。那么cloudpickle有没有打包不了的对象呢,这个确实还是有的,那就是序列化对象(函数、类对象)中如果包含有import语句的并不会把import语句中所涉及的对象进行一并打包。对于cloudpickle不能把序列化对象中包含的import引入的对象一并打包这个事情我个人的观点是其实现的难点在于import对象中会涉及大量的对象,这样进行一并打包要包含哪些对象难以确定、并且全部打包也是会造成序列化后对象字节码过长、序列化用时过长等问题。
例子:
模块: another_module.py

def g():
print("hello world")
return 100
模块 x.py:
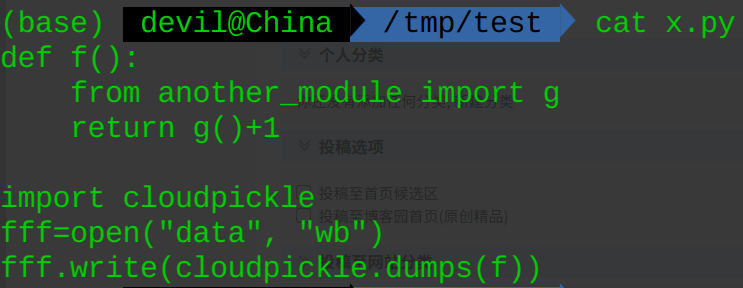
def f():
from another_module import g
return g()+1 import cloudpickle
fff=open("data", "wb")
fff.write(cloudpickle.dumps(f))
运行 x.py,把序列化后字节数据存入data文件中:
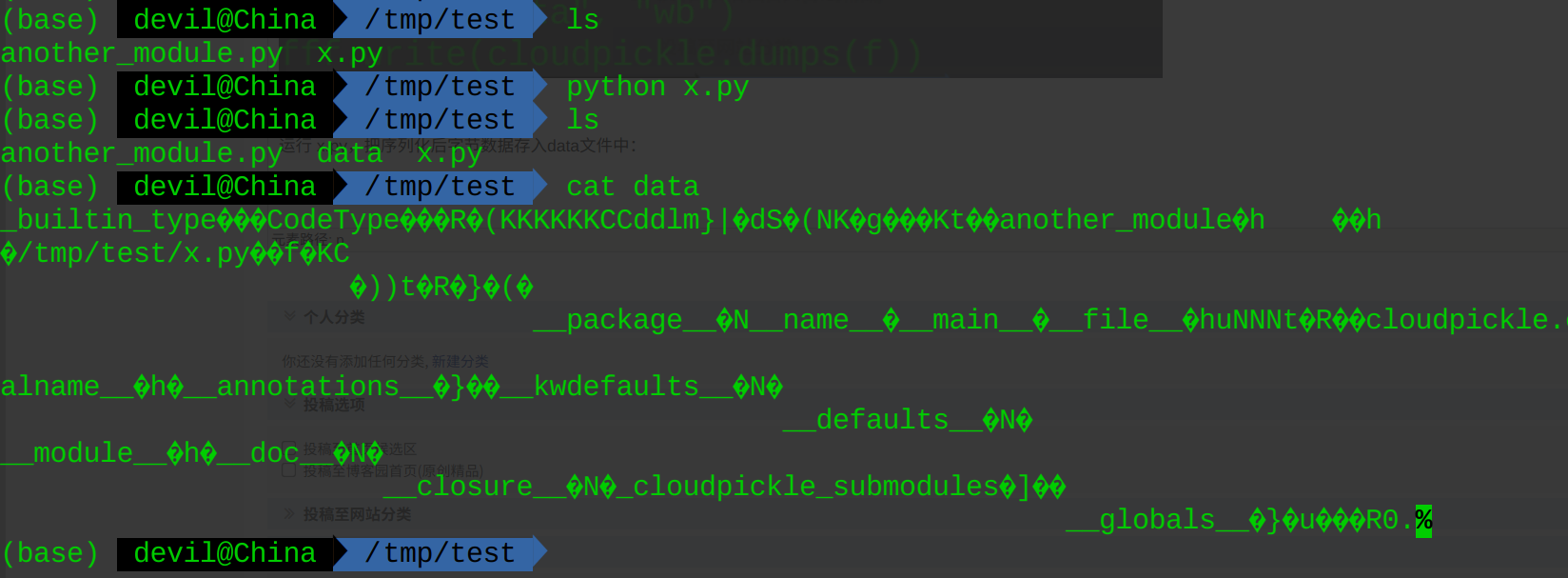
----------------------------------
给出反序列化文件 y.py:
import cloudpickle
fff=open("abc", "rb")
f = cloudpickle.loads(fff.read())
f()
如果把序列化文件data和反序列化文件y.py放在另一个单独的文件夹中并运行y.py,结果如下:
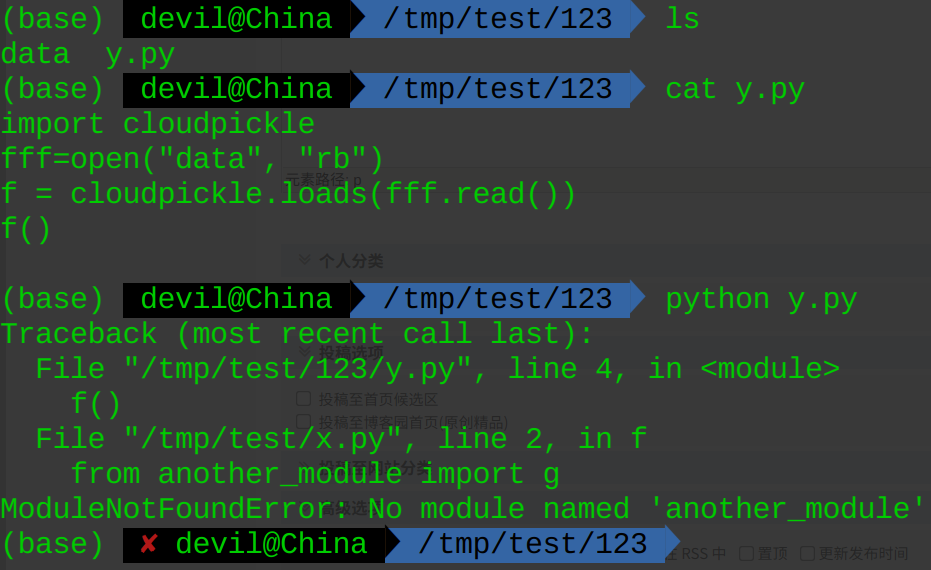
可以看到,使用cloudpickle并没有把涉及到的import语句中引入的对象进行一并的打包序列化。
PS: cloudpickle的底层实现依旧是调用pickle模块,可以说cloudpickle模块是对pickle模块的进一步包装,其实现的功能就是把pickle序列化中没有打包的对象以value的形式进行一并打包。
====================================================
cloudpickle —— Python分布式序列化的专用模块的更多相关文章
- Python:序列化 pickle JSON
序列化 在程序运行的过程中,所有的变量都储存在内存中,例如定义一个dict d=dict(name='Bob',age=20,score=88) 可以随时修改变量,比如把name修改为'Bill',但 ...
- Python库:序列化和反序列化模块pickle介绍
1 前言 在“通过简单示例来理解什么是机器学习”这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 通过简单示例来理解什么是机器学习 pickle是python语言的一个标准模块,安装pyt ...
- python 序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- python之序列化模块、双下方法(dict call new del len eq hash)和单例模式
摘要:__new__ __del__ __call__ __len__ __eq__ __hash__ import json 序列化模块 import pickle 序列化模块 补充: 现在我们都应 ...
- Python基础(正则、序列化、常用模块和面向对象)-day06
写在前面 上课第六天,打卡: 天地不仁,以万物为刍狗: 一.正则 - 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法: - 在线正则工具:http://tool ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- python模块知识二 random -- 随机模块、序列化 、os模块、sys -- 系统模块
4.random -- 随机模块 a-z:97 ~ 122 A-Z :65 ~ 90 import random #浮点数 print(random.random())#0~1,不可指定 print( ...
- Python 序列化 pickle/cPickle模块
Python 序列化 pickle/cPickle模块 2013-10-17 Posted by yeho Python序列化的概念很简单.内存里面有一个数据结构,你希望将它保存下来,重用,或者发送给 ...
- python序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- [python] Python数据序列化模块pickle使用笔记
pickle是一个Python的内置模块,用于在Python中实现对象结构序列化和反序列化.Python序列化是一个将Python对象层次结构转换为可以本地存储或者网络传输的字节流的过程,反序列化则是 ...
随机推荐
- 轻松实现H5页面下拉刷新:滑动触发、高度提示与数据刷新全攻略
前段时间在做小程序到H5的迁移,其中小程序中下拉刷新的功能引起了产品的注意.他说到,哎,我们迁移后的H5页面怎么没有下拉刷新,于是乎,我就急忙将这部分的内容给填上. 本来是计划使用成熟的组件库来实现, ...
- WebApi 接口参数不再困惑
从网上看了WEBAPI理解感觉不错分享一下 前言:还记得刚使用WebApi那会儿,被它的传参机制折腾了好久,查阅了半天资料.如今,使用WebApi也有段时间了,今天就记录下API接口传参的一些方式方法 ...
- Linux 增加 swap 分区
检查当前swap分区 [root@localhost ~]# free -g total used free shared buffers cached Mem: 15 0 14 0 0 0 -/+ ...
- P6623 [省选联考 2020 A 卷] 树
day2t2但难度不大,和AGC044C解法类似 题目大意: 给定一棵 \(n\) 个结点的有根树 \(T\),结点从 \(1\) 开始编号,根结点为 \(1\) 号结点,每个结点有一个正整数权值 \ ...
- Kubernetes 存储资源 PV、PVC 和StorageClass详解
一.存储机制介绍 在 Kubernetes 中,存储资源和计算资源(CPU.Memory)同样重要,Kubernetes 为了能让管理员方便管理集群中的存储资源,同时也为了让使用者使用存储更加方便,所 ...
- 机器学习策略篇:详解如何使用来自不同分布的数据,进行训练和测试(Training and testing on different distributions)
如何使用来自不同分布的数据,进行训练和测试 深度学习算法对训练数据的胃口很大,当收集到足够多带标签的数据构成训练集时,算法效果最好,这导致很多团队用尽一切办法收集数据,然后把它们堆到训练集里,让训练的 ...
- zookeeper的znode节点过多无法通过zkCli.sh移除节点
背景描述:zookeeper的一个目录下的znode节点过多,导致在执行ls 和rmr命令的时候,直接终止会话退出,无法递归删除下面的子节点,具体情况如下(生产环境的zookeeper是clickho ...
- Python生成PDF:Reportlab的六种使用方式
Reportlab是Python创建PDF文档的功能库 这里是整理过的六种Reportlab使用方式,主要参考的是<ReportLab User Guide> 一.使用文档模板DocTem ...
- 解决方案 | Claunch 如何更新配置文件
1.问题 比如我的电脑上有Claunch 3.26版本(绿色版本),但是更新的时候如何保证我的新版本的图标.链接也更新是个问题. 官网说得比较模糊: 2.解决方法 打开复制data数据覆盖到新版本同样 ...
- Vue 数组和对象更新,但视图未更新,背后的故事
在实际开发中,遇到遍历数组和对象,当property 发生改变时,并没有触发视图的更新今天来浅显的聊聊这背后的故事,有说的不对地方,还望指出! 本人博文地址:https://www.cnblogs.c ...