典型性相关分析在SPSS中的实现
典型性相关分析是研究两组变量(每组变量中都可能有多个指标)之间相关关系的一种多元统计方法。它能够揭示出两组变量之间的内在联系。
本文着重模型在spss中的应用,通过一道例题解释各个指标的意义。详细推导过程请选修课程《多元统计分析》
一、问题提出
直接对这些变量的相关进行两两分析,很难得到关于这两组变量之间关系的一个清楚的印象。
因此我们需要把多个变量与多个变量之间的相关化为两个具有代表性的变量之间的相关。此时用到我们的典型性相关分析模型
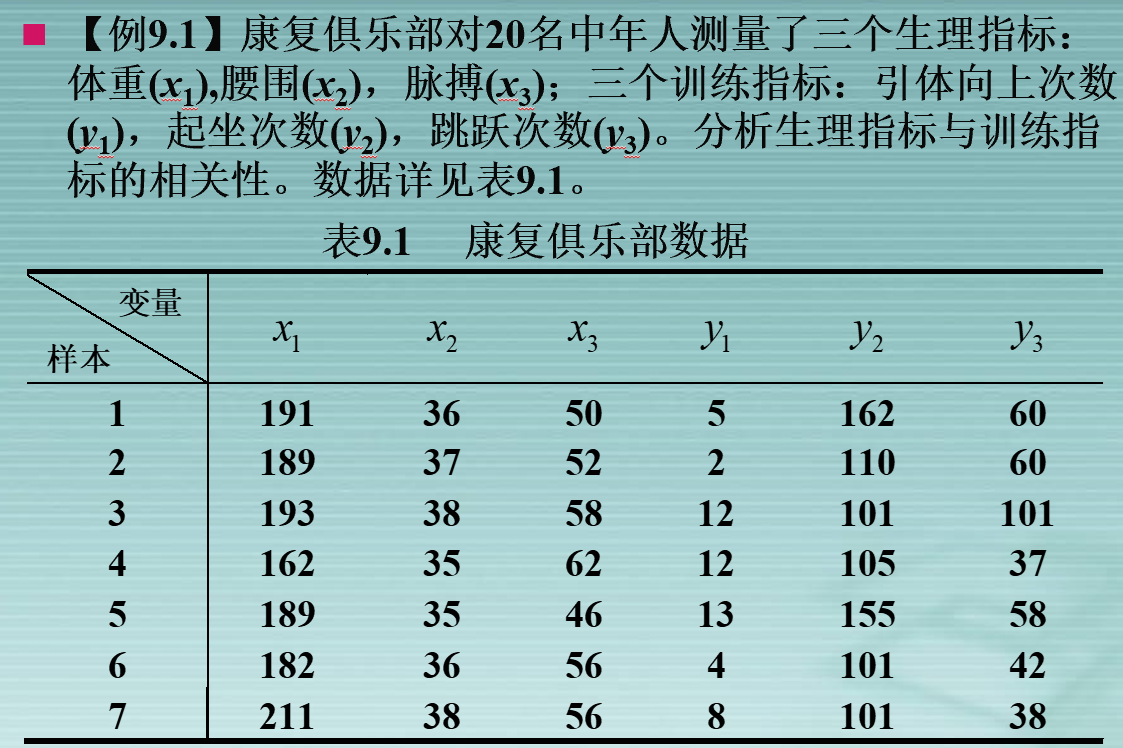
二、利用SPSS进行典型相关分析
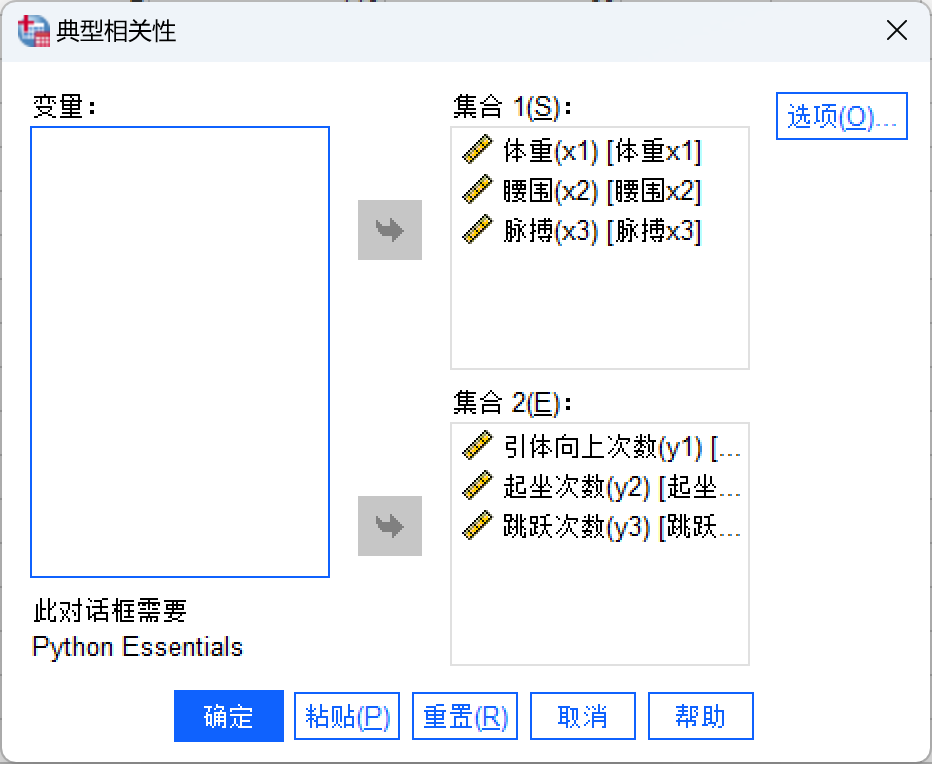
三、对软件导出的结果进行分析
1.文件导出
由于spss翻译的问题,软件上直接得到的结果并不能很好地让我们理解,因此我们可以选择将结果导出为word,修改一下翻译
具体修改的地方会在接下来的介绍中逐一揭示,标志为黄色强调
2.典型相关系数
在典型性相关分析中,每个一级指标下面有多个二级指标。我们只想对一级指标进行分析,但是一级指标是由二级指标进行决定的,那么要如何处理二级指标呢?
答案是用二级指标对一级指标进行线性组合,即X=ax1+bx2+cx3+.....;
这种线性组合有无数种,因此我们需要进行约束,约束条件即为其相关系数达到最大,最后得到了三组线性组合

在第一组线性组合中,在α=0.1下,其是显著的,并且相关系数为0.796;说明在第一组线性组合下,两个一级指标之间有相关性
而第二组和第三组线性组合没有统计学意义
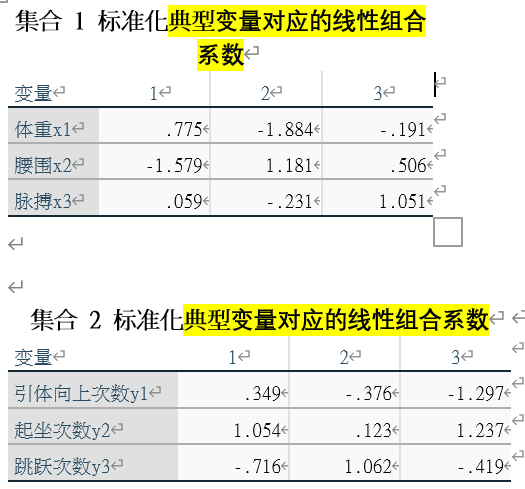
3.典型变量对应的线性组合系数
如图所示,我们可以得到三种线性组合的线性组合系数,即a1 a2 a3的值;但第二种和第三种没有通过假设检验,没有统计学意义
同时,我们倾向于关注标准化后的线性组合系数,因为其去除了量纲的影响
4.典型载荷分析
典型载荷分析可以得出二级指标对一级指标影响程度的大小。
影响程度的大小不是看线性组合系数,而是看典型载荷分析的值,因为线性组合系数是考虑了其他的二级指标而得到的
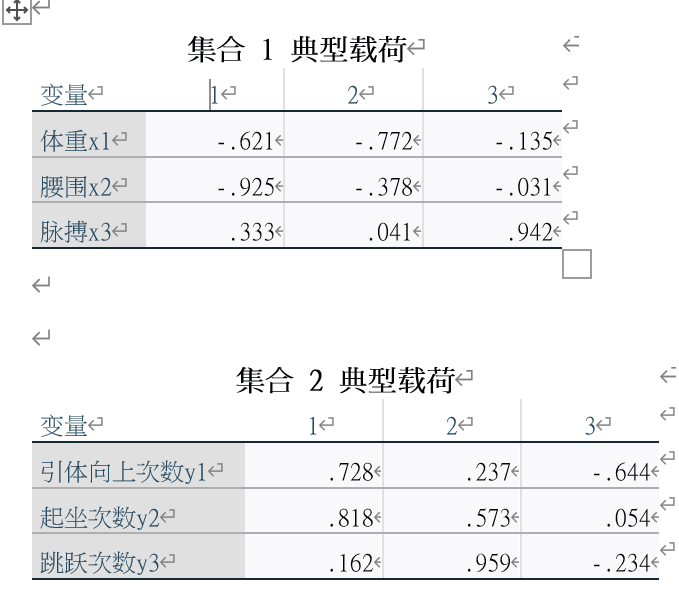
典型载荷的系数越大,二级指标对一级指标的影响就越大
5.典型冗余分析
典型冗余分析用来分析一组线性组合对数据的解释程度,用百分比来表示

因为只有第一组线性组合有统计学意义,因此我们只需要看第一组的解释比例即可
其中对变量一自身的为0.451;其中对变量二自身的为0.408;
如果两组都显著,那么可解释比例即为0.451+0.247
交叉的一般不看
典型性相关分析在SPSS中的实现的更多相关文章
- SPSS中两种重复测量资料分析过程的比较
在SPSS中,有两个过程可以对重复测量资料进行分析:一种是一般线性模型的重复度量:一种是混合线性模型,对于同样的数据资料,使用两种过程分析出的内容不大一样,注意是内容而不是结果,只要操作正确,结果应该 ...
- SPSS中变量的度量标准
在SPSS中,每一个变量都有一个度量标准,这些度量标准说明变量的含义和属性,会对后续的分析产生影响. 1.名义:名义表示定类变量,定类变量表示事物的类别,只能计算频数和频率,各类别之间没有大小.顺序. ...
- spss中如何处理极端值、错误值
spss中如何处理极端值.错误值 spss中录入数据以后,第一步不是去分析数据,而是要检验数据是不是有录入错误的,是不是有不合常理的数据,今天我们要做一个描述性统计,进而查看哪些数据是不合理的.下面是 ...
- pearson相关分析在R中的实现
三个相关性函数: cor():R自带的,输入数据可以是vector,matrix,data.frame,输出两两的相关系数R值 cor.test():R自带的,输入数据只能是两个vector,输出两个 ...
- SPSS数据分析—相关分析
相关系数是衡量变量之间相关程度的度量,也是很多分析的中的当中环节,SPSS做相关分析比较简单,主要是区别如何使用这些相关系数,如果不想定量的分析相关性的话,直接观察散点图也可以. 相关系数有一些需要注 ...
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
https://www.zhihu.com/topic/19582125/top-answershttps://wenku.baidu.com/search?word=spss&ie=utf- ...
- SPSS输出结果如何在word中设置小数点前面显示加0
SPSS输出结果如何在word中设置小数点前面显示加0 在用统计分析软件做SPSS分析时,其输出的结果中,如果是小于1(绝对值)的数,那么会默认输出不带小数点的数值.例如0.362和 -0.141被显 ...
- SPSS数据分析—信度分析
测量最常用的是使用问卷调查.信度分析主要就是分析问卷测量结果的稳定性,如果多次重复测量的结果都很接近,就可以认为测量的信度是高的.与信度相对应的概念是效度,效度是指测量值和真实值的接近程度.二者的区别 ...
- SPSS数据分析—卡方检验
t检验和方差分析主要针对于连续变量,秩和检验主要针对有序分类变量,而卡方检验主要针对无序分类变量(也可以用于连续变量,但需要做离散化处理),用途同样非常广泛,基于卡方统计量也衍生出来很多统计方法. 卡 ...
- SPSS简单使用
当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量.数据录入.统计分析 ...
随机推荐
- Linux-0.11操作系统源码调试
学习操作系统有比较好的两种方式,第一种是跟着别人写一个操作系统出来,<操作系统真相还原>.<Orange's:一个操作系统的实现>等书就是教学这个的:另一种方式就是调试操作系统 ...
- Xcode多进程调试:WKWebView
由于WKWebView使用的是多线程架构,渲染模块和网络模块都各自在一个单独的进程里面,因此,如果需要设置渲染模块或者网络模块里面的断点,需要做一些特殊处理. 举个例子,假设在Xcode里面设置了渲染 ...
- element-ui使用el-date-picker日期组件常见场景
开始 最近一直在使用 element-ui中的日期组件. 所以想对日期组件常用的做一个简单的总结: 1.处理日期组件选择的时候面板联动问题 2.限制时间范围 解除两个日期面板之间的联动 我们发现2个日 ...
- PyQt5自定义信号
一.简介 在 PyQt5 中,自定义信号是一个常见的任务,通常用于在对象之间传递信息或触发特定行为.自定义信号需要继承自 QtCore.pyqtSignal 并定义其参数类型. 二.操作步骤 1.导入 ...
- CSS旋转正方体
CSS实现一个旋转的正方体,鼠标放上去会自动解体.比较普通的实现,留个记录.(代码里的注释方式写错了) <!doctype html> <html lang="en&quo ...
- Linux运维面试总结
1.Linux系统相关日志 /var/log/message:系统信息日志,包含错误信息 /var/log/secure:系统登录日志 /var/log/maillog:邮件日志 /var/log/c ...
- vue-i18n 初体验
vue-i18n 初体验 使用vue,如何国际化呢?采用 vue-i18n.(i18n,internationalization,i和n中间省略18个字符) vue-i18n 官网地址 https:/ ...
- .NET桌面程序混合开发之四:键盘事件的响应
1. 问题 在生产环境中,有一些场景需要窗体来响应键盘事件(注意,是窗体响应,而不是窗体上的控件响应),如解析扫码枪的扫描结果.但在嵌入WebView2的Form程序,Host Form无法对键盘事件 ...
- 004. github使用
github的使用 GitHub是一个git版本库的托管服务,GitHub是目前全球最大的软件仓库,拥有上班玩的开发者用户,也是软件开发和寻找资源的最佳途径,GitHub不仅可以托管各种git版本参控 ...
- k8s中的pod更新策略
StatefulSet(有状态集,缩写为sts)常用于部署有状态的且需要有序启动的应用程序,比如在进行SpringCloud项目容器化时,Eureka的部署是比较适合用StatefulSet部署方式的 ...