mapreduce的shuffle机制
1.1 概述:
mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;(从map的输出到reduce的输入)
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);
具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
1.2 主要流程:
Shuffle缓存流程:
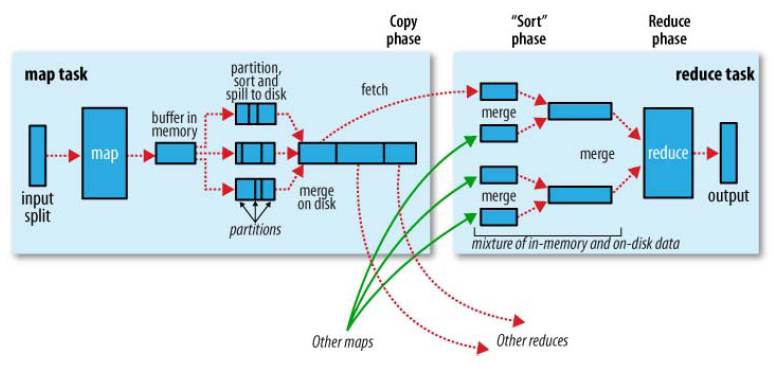
Buffer in memory:内存缓冲区
Partition:分区
Sort:分类
Spill to disk:切片到磁盘
Merge on disk:合并到磁盘
Fetch:拿来,拿取
Copy phase:复制阶段
Mixture of in-memory and on-disk data:内存和磁盘数据的混合
(可以看出一个maptask可以对应多个reducetask)
shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的,整体来看,分为3个操作:
1、分区partition
2、Sort根据key排序
3、Combiner进行局部value的合并
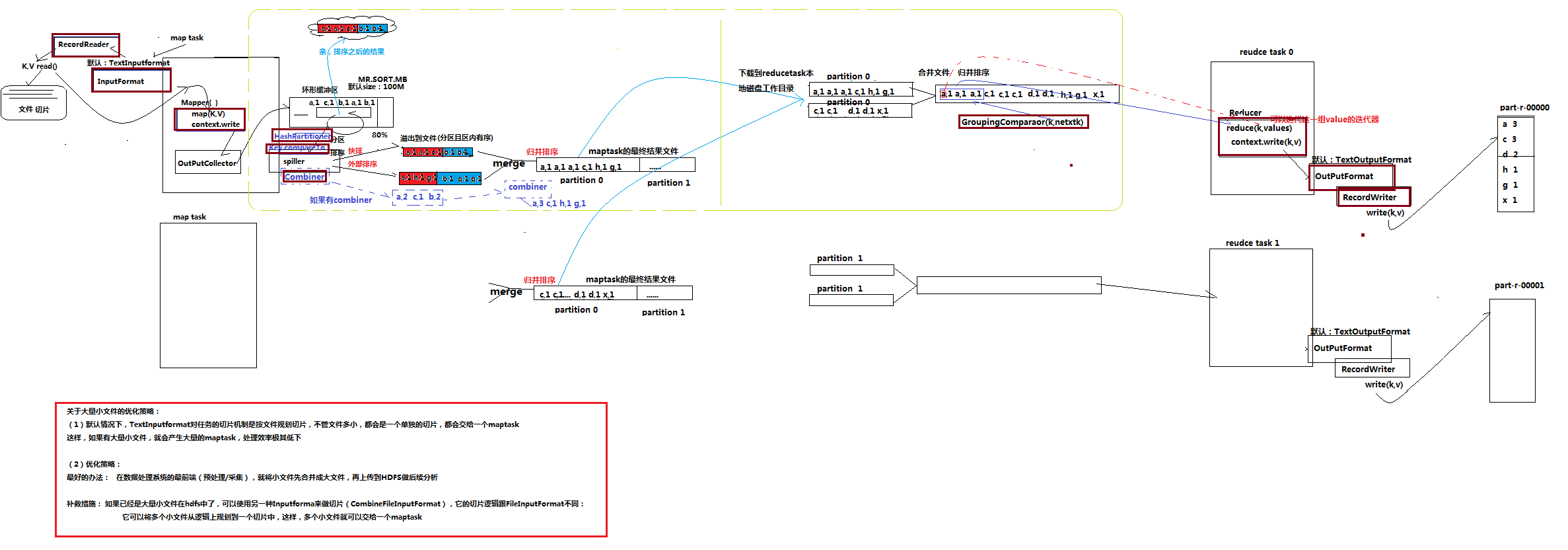
1.3 详细流程
1、 maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
(环形缓冲区默认100M)
2、 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(经过patition分区,key的compareto方法,经过排序,由combiner合并同key键值对,再经过快排/外部排序,溢出到文件)
3、 多个溢出文件会被合并成大的溢出文件
(经过merge文件合并,归并排序,得到maptask的最终结果文件)
------------------------------------------------------------------------------------------------------------
4、 在溢出过程,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5、 reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6、 reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)(一个reducetask可以对应多个maptask,两者是多对多)
7、 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
1.4 详细流程示意图
mapreduce的shuffle机制的更多相关文章
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- MapReduce原理——Shuffle机制
在Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle. Map方法输出的数据会获得对应的分区,进入环形缓冲区(缓冲区一半写索引,另一半写数据).数据达到缓冲区的80%会发生溢写.在 ...
- 【待完成】[MapReduce_9] MapReduce 的 Shuffle 机制
0. 说明 待补充...
- Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制: Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle 将mapta ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
随机推荐
- 一:大数据架构回顾-Lambda架构
"我们正在从IT时代走向DT时代(数据时代).IT和DT之间,不仅仅是技术的变革,更是思想意识的变革,IT主要是为自我服务,用来更好地自我控制和管理,DT则是激活生产力,让别人活得比你好&q ...
- C#使用MX Component实现三菱PLC软元件数据采集的完整步骤(仿真)
前言 本文介绍了如何使用三菱提供的MX Component插件实现对三菱PLC软元件数据的读写,记录了使用计算机仿真,模拟PLC,直至完成测试的详细流程,并重点介绍了在这个过程中的易错点,供参考. 用 ...
- docker-compose 配置LNMP环境
仓库地址: https://gitee.com/haima1004/docker-lnmp 参考文档: 视频地址: https://www.bilibili.com/video/BV1S54y1B7K ...
- ansible(5)--ansible的script模块
1. script模块 作用:在远程主机运行本地的脚本: 调用格式: -m script -a "/PATH/TO/SCRIPT_FILE": 参数: creates:如果其后跟的 ...
- P3622 [APIO2007] 动物园 -题解
好写 爱写 没事干 所以有了这篇题解 洛谷P3622 [APIO2007] 动物园 题解 $Link$ hzoi题库 洛谷 题目说的挺繁琐,其实就传达了一个很简单的信息: \(n\)个动物,\(c\) ...
- 使用 JS 实现在浏览器控制台打印图片 console.image()
在前端开发过程中,调试的时候,我门会使用 console.log 等方式查看数据.但对于图片来说,仅靠展示的数据与结构,是无法想象出图片最终呈现的样子的. 虽然我们可以把图片数据通过 img 标签展示 ...
- PyQt5 GUI编程(组件使用)
一.简介 PyQt5 是一个用于创建图形用户界面(GUI)应用程序的 Python 绑定,它基于 Qt 库.PyQt5 提供了大量的组件(也称为控件或部件),用于构建复杂的用户界面.以下是一些常用的 ...
- docker镜像仓库管理Harbor
一 部署Harbor 前提: Harbor需要运行在docker上面,所以首先需要在harbor部署机器上面自行部署docker和docker-compose docker-compose安装命令如下 ...
- Stemciljs学习之组件生命周期
组件有许多生命周期方法,可用于了解组件何时"将"和"执行"加载.更新和呈现.可以将这些方法添加到组件中,以便在正确的时间挂接到操作中. 在组件类中实现以下方法之 ...
- 解决”将公司Linux服务器上的脚本导出到windows上打开串行的“问题
目录 一.前期准备 二.回车转换 一.前期准备 1.在linux服务器上写一个简单的脚本. [root@node5 ~]# vim linux脚本.sh [root@node5 ~]# cat lin ...