解读clickhouse存算分离在华为云实践
摘要:本文是我们对clickhouse做了最简单的支持obs的适配改造。
本文分享自华为云社区《clickhouse存算分离在华为云实践》,作者: he lifu。
clickhouse是一款非常优秀的OLAP数据库系统,2016年刚开源的时候就因为卓越的性能表现得到大家的关注,而近两年国内互联网公司的大规模应用和推广,使得它在业内声名鹊起,且受到了大家一致的认可。
从网络上公开分享的资料和客户使用的案例总结来看,clickhouse主要是应用在实时数仓和离线加速两个场景,其中有些实时业务为了追求极致的性能会上全SSD的配置,考虑到实时数据集的有限规模,这种成本尚能够接受,但是对于离线加速的业务,数据集普遍会很大,这个时候上全SSD配置的成本就会显得昂贵了,有没有办法既能满足较高的性能又能把成本控制的尽量低?我们的想法是弹性伸缩,把数据存储到低廉的对象存储上面,通过动态增加计算资源的方式满足高频时段的高性能需求,通过回收计算资源的方式控制低频时段的成本,所以我们把目标放在了存算分离这个特性上。
一.存算分离现状
clickhouse是存算一体的数据库系统,数据是直接落在本地磁盘上(包括云硬盘),关注社区动态的读者已经知道最新的版本可以支持数据持久化到对象存储和HDFS上了,以下是我们对clickhouse做了最简单的支持obs的适配改造,和原生的支持S3一样:
1.配置S3磁盘
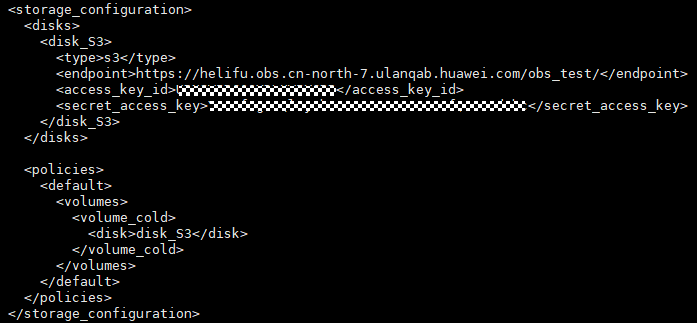
2.创建表并灌入数据

3.检查本地盘数据
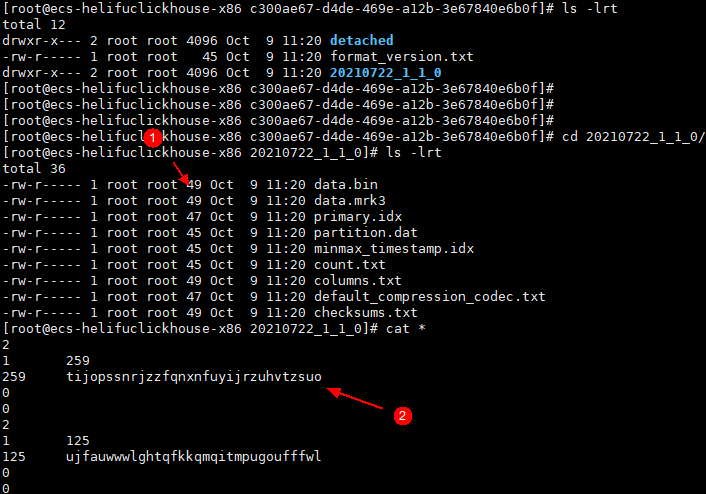
4.检查对象存储数据
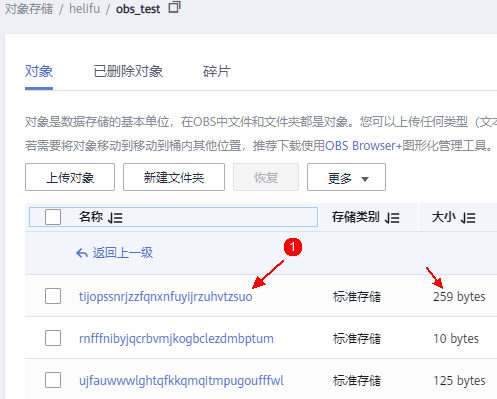
从上面几个图片来看, 可以发现本地磁盘上的数据文件内容记录了obs上的文件名(uuid),也就是说clickhouse和obs对象之间是通过本地数据文件中的“映射”关系关联起来的,注意这个“映射”关系是持久化在本地的,意味着需要冗余以满足可靠性。
然后进一步,我们看到社区也在努力把clickhouse往存算分离的方向推进:
- v21.3版本引入的Add the ability to backup/restore metadata files for DiskS3,允许把本地数据文件到obs对象的映射关系、本地数据的目录结构等属性,放到obs对象的属性里(object的metadata),这样解耦了数据目录必须在本地的限制,也解除了维持映射关系的本地文件可靠性而至少双副本的条件;
- v21.4版本引入的S3 zero copy replication,使得多个副本间可以共享一份远端数据,显著的降低了存算一体引擎多副本存储的开销。
但事实上,通过验证测试可以发现当前阶段存算分离距离可以上生产还有很长路要走,比如:atomic库下的表怎么搬到对象存储上(表定义sql文件中标识唯一性的UUID和数据目录UUID的对应关系)、弹性扩缩容时候如何快速有效均衡数据(拷贝数据会极大拉长操作窗口)、修改本地磁盘文件和远端对象如何保障一致性、节点宕机如何快速恢复等等棘手的问题。
二.我们的实践
在云原生的时代,存算分离是趋势也是我们的工作方向,接下来的讨论将围绕华为公有云对象存储obs来展开。
1.引入文件语义
这里需要重点强调下华为云对象存储obs和其他竞品的最大差异化点:obs支持文件语义,支持文件和文件夹的rename操作。这点对于我们在接下来的系统设计和弹性伸缩实现上非常有价值,所以我们把obs的驱动集成进了clickhouse,然后修改了clickhouse的逻辑,这样数据在obs上长的和本地一模一样了:
Local Disk:

OBS:
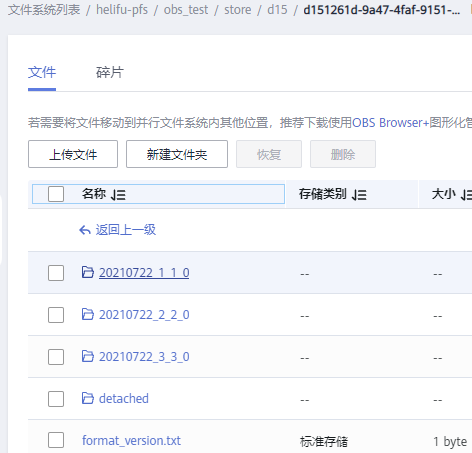
有了完整的数据目录结构后,再支持merge、detach、attach、mutate以及part回收等操作就比较方便了。
2.离线场景
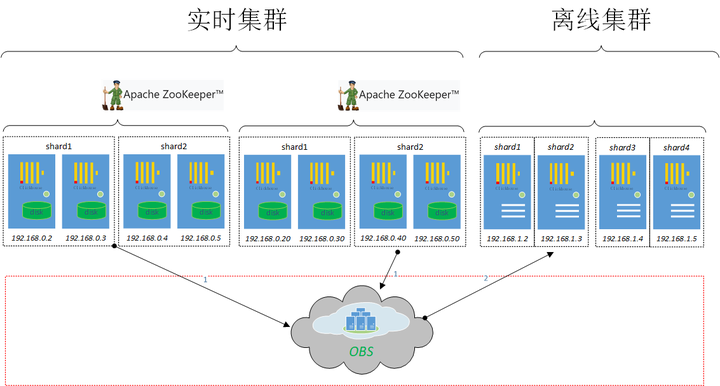
From bottom to top,我们再来看系统结构,离线加速场景中去除了对zookeeper的依赖,每个shard一个replica:

然后是扩缩容节点时候的数据均衡功能,通过obs的rename操作完成对part级别的低成本移动(和clickhouse copier工具的数据重新分发均衡不一样),节点宕机后新节点从对象存储侧构造出本地数据文件目录。
3.融合场景
ok,在上面离线场景的基础上我们继续融入实时场景(下图中的“实时集群”部分),不同业务的clickhouse集群,可以通过冷热分离分层存储的方式(这一功能相对比较成熟,业内普遍采用它来降低存储成本),把冷数据从实时集群里淘汰出来,再通过obs rename操作挂载到“离线集群”中,这样我们可以覆盖数据从实时到离线的完整的生命周期(包括从hive到clickhouse的ETL过程):
三.未来的展望
前面的实践是我们在存算分离方向的第一次尝试,还在不断的改进优化中,从宏观的角度来看仍旧是把obs作为拉远了的磁盘来使用,不过感谢obs的高吞吐,相同计算资源的前提下SSD和obs跑Star Schema Benchmark的性能延迟在5x左右,但是存储成本得到了显著的降低10x。未来,我们会在前面工作的基础上,去除obs作为拉远磁盘的属性,把单个表的数据统一在一个数据目录下,收编clickhouse的元数据,把它做成无状态的计算节点,达到sql on hadoop的效果,类似impala一样的MPP数据库。
解读clickhouse存算分离在华为云实践的更多相关文章
- ClickHouse 存算分离架构探索
背景 ClickHouse 作为开源 OLAP 引擎,因其出色的性能表现在大数据生态中得到了广泛的应用.区别于 Hadoop 生态组件通常依赖 HDFS 作为底层的数据存储,ClickHouse 使用 ...
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
- 腾讯云 CHDFS — 云端大数据存算分离的基石
随着网络性能提升,云端计算架构逐步向存算分离转变,AWS Aurora 率先在数据库领域实现了这个转变,大数据计算领域也迅速朝此方向演化. 存算分离在云端有明显优势,不但可以充分发挥弹性计算的灵活,同 ...
- 存算分离实践:JuiceFS 在中国电信日均 PB 级数据场景的应用
01- 大数据运营的挑战 & 升级思考 大数据运营面临的挑战 中国电信大数据集群每日数据量庞大,单个业务单日量级可达到 PB 级别,且存在大量过期数据(冷数据).冗余数据,存储压力大:每个省公 ...
- 存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?
引言 随着大数据技术架构的演进,存储与计算分离的架构能更好的满足用户对降低数据存储成本,按需调度计算资源的诉求,正在成为越来越多人的选择.相较 HDFS,数据存储在对象存储上可以节约存储成本,但与此 ...
- 华为云BigData Pro解读: 鲲鹏云容器助力大数据破茧成蝶
华为云鲲鹏云容器 见证BigData Pro蝶变之旅大数据之路顺应人类科技的进步而诞生,一直顺风顺水,不到20年时间,已渗透到社会生产和人们生活的方方面面,.然而,伴随着信息量的指数级增长,大数据也开 ...
- 《一张图看懂华为云BigData Pro鲲鹏大数据解决方案》
8月27日,华为云重磅发布了业界首个鲲鹏大数据解决方案--BigData Pro.该方案采用基于公有云的存储与计算分离架构,以可无限弹性扩容的鲲鹏算力作为计算资源,以支持原生多协议的OBS对象存储服务 ...
- 华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生. 伴随5G.大数据.AI.IoT的飞速发展,数据呈现大规模.多样性的极速增长 ...
- 华为云FusionInsight MRS:助力企业构建“一企一湖,一城一湖”
摘要:华为云FusionInsight MRS新一代的数据湖,让大数据越用越快.越用越易.越用越稳.越用越省!让数据价值近在眼前! 10月30日,以"携手共赢·数创未来"为主题的第 ...
- “3+3”看华为云FusionInsight如何引领“数据新基建”持续发展
摘要:一个统一的现代化的数据基建需要三类架构来实践三种不同的应用场景. 近期,美国知名科技企业风投机构A16Z总结出一套通用的技术架构服务,分为以下三种场景. 一.数据基建架构全景 数据流向显示,左侧 ...
随机推荐
- git 创建本地分支并关联远程分支
1.查看远程分支 git branch 可以看到,我本地只有dev和master分支.现在同事创建了一个远程分支dev-glq,里面是他的代码.我应该再我本地创建一个分支,并且他的关联远程分支. 2. ...
- ubuntu20.04不定时卡死,鼠标和键盘都不可用,且tty无效
事情的经过: 已经在ubuntu上安装了好多东西,配置了好多环境,最近突然莫名卡死.我遇到的问题是: 1.如果开机之后只是打开终端,打开编辑器之类的操作,系统不会卡死. 2.一旦打开firefox火狐 ...
- Java Exception最佳实践(转)
https://www.dubby.cn/detail.html?id=9033 1.异常介绍 2.Java中的异常介绍 3.自定义异常 4.几个建议 1)不要生吞异常 2)申明具体的异常 3)尽可能 ...
- 文件 inode 与 no space left on device 异常
转载请注明出处: 文件inode 在 Linux 文件系统中,每一个文件或目录都会有一个 inode,它是一个数据结构,用于存储文件的元数据,比如文件的权限.所有者.大小.创建和修改的时间等.inod ...
- 两个对于电影片段的情绪研究(中国&国外)
1.国内的研究(A new standardized emotional film database for Asian culture) 测试片使用了8种情绪类型,每部片子有4个维度的分数,分数是从 ...
- Python 利用pandas和matplotlib绘制堆叠柱状图
在数据可视化中,堆叠柱状图是一种常用的图表类型,它能够清晰地展示多个类别的数据,并突出显示每个类别中各部分的总量和组成比例.本文将演示如何使用 Python 的 pandas 和 matplotlib ...
- 浅谈斜率优化DP
前言 考试 T2 出题人放了个树上斜率优化 DP,直接被同校 OIER 吊起来锤. 离 NOIP 还有不到一周,赶紧学一点. 引入 斜率 斜率,数学.几何学名词,是表示一条直线(或曲线的切线)关于(横 ...
- 27. 干货系列从零用Rust编写正反向代理,Rust中日志库的应用基础准备
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,内网穿透,后续将实现websocket代理等,会将实现 ...
- UIPath变量和参数
一. UIPath变量 变量(Variables),变量是所有编程语言中必不可少的部分.对于UIPath来说自然也是如此,其承载了我们RPA流程中数据传递的重要作用.对于接触过编程的开发者来说,变 ...
- StackGres 1.6 数据库平台工程功能介绍以及快速上手
StackGres 1.6 数据库平台工程功能 声明式 K8S CRs StackGres operator 完全由 Kubernetes 自定义资源管理.除了 kubectl 或任何其他 Kuber ...