关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题答案就得去读官方文档吧。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import MySQLdb df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\aaa.csv',encoding='gb2312')
这是我本地测试用的,先看一下效果。
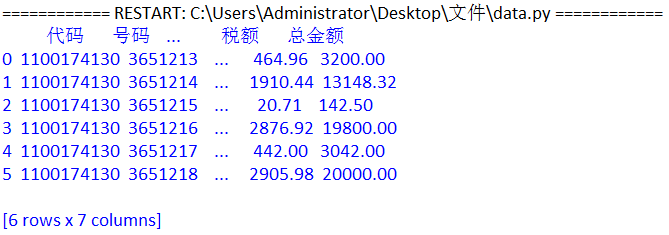
这里看到每一行中间都会出现一个“...”省略号,这是因为模块对于每一行的显示限制,以内存最小形式来显示,所以会以省略号代替其中间的内容。
如果数据行很多的话,对于pandas模块是自动默认只显示100行数据,如果超100行,例如120行,则中间的20行会被“ ... ”替代!
先处理pandas 读取数据后在行中间省略部分的处理:
df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\aaa.csv',encoding='gb2312')
pd.set_option('display.width',None)
print df
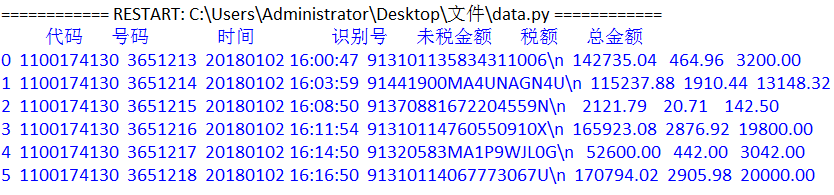
这里只需要添加pd.set_option('display.width',None)即可,http://pandas.pydata.org/pandas-docs/stable/options.html 我也是在官方文档中查找到的,其中有详细的解释,和set_option函数的其他方法。

在度娘中死活也找不到相关的回答,在google中也只有寥寥无几的回答,并且极少出现过这种情况,唯独我遇上了,所以记载以下。
如果是行与行之间的省略,则只需要添加:
pd.set_option('display.max_rows', None)

同样是以最大行数来显示数据。
这里分享一下pandas模块连接数据库的操作:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import MySQLdb #读取url为csv
data_url = 'https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv'
dat = pd.read_csv(data_url) mysql_da = MySQLdb.connect(host='localhost',port=3306,user='root',passwd='root',db='库名')
df = pd.read_sql('select * from 表',con = mysql_da)
pd.set_option('display.width',None)
mysql_da.close()
print df
这部分内容引用:https://www.cnblogs.com/zzhzhao/p/5269217.html#undefined 文章,这是一篇很好的文章,我也是其中学习了很多,但是博主她不知道有没有遇到我的问题。
因为我遇到了这样的问题,所以查了很多资料也未能解决,最后还是在官方文档中偶然间看到的!所以分享给遇到同样问题不知道答案的人!
关于Python pandas模块输出每行中间省略号问题的更多相关文章
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载文件
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-pandas模块-CSV文件读写
Pandas 即Python Data Analysis Library,是为了解决数据分析而创建的第三方工具,它不仅提供了丰富的数据模型,而且支持多种文件格式处理,包括CSV.HDF5.HTML 等 ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-03-数据整理
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- python pandas模块简单使用(读取excel为例)
第一步:模块安装 pip install pandas 第二步:使用(单个工作表为例) 说明:如果有多个工作表,那么只要指定sheetname=索引,(第一个工作表为0,第二个工作表为1,以此类推) ...
- python: pandas模块
10分钟入门 pandas 评:我跟作者的智商差距是有多大,才能让我用60分钟看完作者认为10分钟的内容... 详细内容见 Cookbook 习惯上我们先导入 : In [1]: import pan ...
- Python Logging模块 输出日志颜色、过期清理和日志滚动备份
# coding:utf-8 import logging from logging.handlers import RotatingFileHandler # 按文件大小滚动备份 import co ...
- python pandas模块,nba数据处理(1)
pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数.pandas兼具Numpy高性能的数组计算功能以及电子表格和关系型数据(如SQL)灵活的数据处理能力.它提供了复杂精细的索引功 ...
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- python重要的第三方库pandas模块常用函数解析之DataFrame
pandas模块常用函数解析之DataFrame 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器 ...
随机推荐
- Java 自定义注释@interface的用法
最简单的待校验的注解定义 @Documented @Constraint(validatedBy = ExistBlankByListValidator.class) @Target({PARAMET ...
- Kubernetes 1.10.0离线安装
讲述如何通过离线的方式安装Kubernetes,主要用于对Kubernetes的研究学习,不建议在生产环境使用,安装包获取地址: 链接:https://pan.baidu.com/s/1nX5_mem ...
- Nginx 如何设置反向代理 多服务器,配置区分开来,单独文件保存单个服务器 server 主机名配置,通过 include 实现
samcao 关注 2015.06.15 10:08* 字数 0 阅读 408评论 0喜欢 0 网络结构如上图.可能你只有一个公网的Ip地址. 但是您的内网有个网站需要映射至外网.而又不想添加其它 ...
- Node.js 操作 OSX 系统麦克风、扬声器音量
最近几年 Electron 很火,公司也正好有个项目想做跨平台客户端,大家研究了一下就选择了 Electron,第一次做 js 的项目遇到了不少坑,不过也都一点点解决了. 因为项目中需要对用户录音,H ...
- this指向及改变this指向的方法
一.函数的调用方式决定了 this 的指向不同,但总的原则,this指的是调用函数的那个对象: 1.普通函数调用,此时 this 指向 全局对象window function fn() { conso ...
- Linux中jdk的安装配置
1.下载jdk安装包 2.解压文件:tar -zxvf jdk-8u211-linux-x64.tar.gz 3.编辑环境变量:vi /etc/profile 4.在环境变量文末添加三行: expor ...
- ISP PIPLINE (九_2) Denoise 之 time domain denoise
时域噪声是空域噪声在时间上波动的一种描述. 1.多帧平均去噪法 1.1 理论: 1.2 帧数增加,噪声减小: 1.3 IIR滤波器的效果 2.1中的两种方法在拍摄视频的时候,如果有运动物体,则会出现拖 ...
- ORM之SQLALchemy
今天来聊一聊 Python 的 ORM 框架 SQLAlchemy SQLAlchemy 没有 Django 的 Models 好用!因为models是Django自带的ORM框架,也正是因为是Dja ...
- 1095 A+B for Input-Output Practice (VII)
一直presentation不对 ,看了别人的解释,还是不知道为什么最后还要\n http://acm.hdu.edu.cn/showproblem.php?pid=1095 #include< ...
- tensorflow 使用 4 非线性回归
# 输入一个 x 会计算出 y 值 y 是预测值,如果与 真的 y 值(y_data)接近就成功了 import tensorflow as tf import numpy as np # py 的画 ...