关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题答案就得去读官方文档吧。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import MySQLdb df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\aaa.csv',encoding='gb2312')
这是我本地测试用的,先看一下效果。
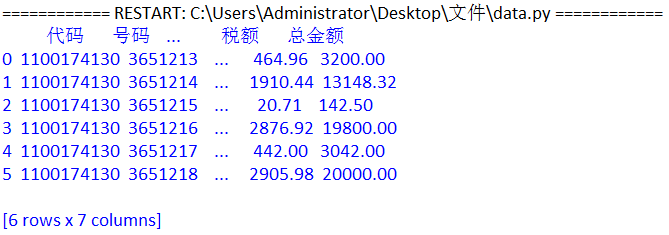
这里看到每一行中间都会出现一个“...”省略号,这是因为模块对于每一行的显示限制,以内存最小形式来显示,所以会以省略号代替其中间的内容。
如果数据行很多的话,对于pandas模块是自动默认只显示100行数据,如果超100行,例如120行,则中间的20行会被“ ... ”替代!
先处理pandas 读取数据后在行中间省略部分的处理:
df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\aaa.csv',encoding='gb2312')
pd.set_option('display.width',None)
print df
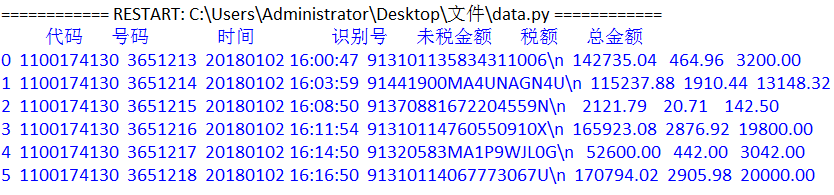
这里只需要添加pd.set_option('display.width',None)即可,http://pandas.pydata.org/pandas-docs/stable/options.html 我也是在官方文档中查找到的,其中有详细的解释,和set_option函数的其他方法。

在度娘中死活也找不到相关的回答,在google中也只有寥寥无几的回答,并且极少出现过这种情况,唯独我遇上了,所以记载以下。
如果是行与行之间的省略,则只需要添加:
pd.set_option('display.max_rows', None)

同样是以最大行数来显示数据。
这里分享一下pandas模块连接数据库的操作:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import MySQLdb #读取url为csv
data_url = 'https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv'
dat = pd.read_csv(data_url) mysql_da = MySQLdb.connect(host='localhost',port=3306,user='root',passwd='root',db='库名')
df = pd.read_sql('select * from 表',con = mysql_da)
pd.set_option('display.width',None)
mysql_da.close()
print df
这部分内容引用:https://www.cnblogs.com/zzhzhao/p/5269217.html#undefined 文章,这是一篇很好的文章,我也是其中学习了很多,但是博主她不知道有没有遇到我的问题。
因为我遇到了这样的问题,所以查了很多资料也未能解决,最后还是在官方文档中偶然间看到的!所以分享给遇到同样问题不知道答案的人!
关于Python pandas模块输出每行中间省略号问题的更多相关文章
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载文件
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-pandas模块-CSV文件读写
Pandas 即Python Data Analysis Library,是为了解决数据分析而创建的第三方工具,它不仅提供了丰富的数据模型,而且支持多种文件格式处理,包括CSV.HDF5.HTML 等 ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-03-数据整理
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- python pandas模块简单使用(读取excel为例)
第一步:模块安装 pip install pandas 第二步:使用(单个工作表为例) 说明:如果有多个工作表,那么只要指定sheetname=索引,(第一个工作表为0,第二个工作表为1,以此类推) ...
- python: pandas模块
10分钟入门 pandas 评:我跟作者的智商差距是有多大,才能让我用60分钟看完作者认为10分钟的内容... 详细内容见 Cookbook 习惯上我们先导入 : In [1]: import pan ...
- Python Logging模块 输出日志颜色、过期清理和日志滚动备份
# coding:utf-8 import logging from logging.handlers import RotatingFileHandler # 按文件大小滚动备份 import co ...
- python pandas模块,nba数据处理(1)
pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数.pandas兼具Numpy高性能的数组计算功能以及电子表格和关系型数据(如SQL)灵活的数据处理能力.它提供了复杂精细的索引功 ...
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- python重要的第三方库pandas模块常用函数解析之DataFrame
pandas模块常用函数解析之DataFrame 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器 ...
随机推荐
- Python2.7和3.7区别
区别一:print语法使用 Python2.7 print语法使用 >>> print "Hello Python" Python3.7 print语 ...
- 单机千万级MQTT连接服务器测试报告
目标:测试创建1000万客户端连接到服务器端,服务器操作系统 Linux(任意一款发行版服务器版本).分别在两台硬件一样的服务器,其中一台用于服务器端运行,另一台用于创建千万客户端连接客户端机器.在硬 ...
- 异步简析之BlockingCollection实现生产消费模式
目前市面上有诸多的产品实现队列功能,比如Redis.MemCache等... 其实c#中也有一个基础的集合类专门用来实现生产/消费模式 (生产模式还是建议使用Redis等产品) 下面是官方的一些资料和 ...
- ARP欺骗配置及演示过程
目录 环境 软件 网络拓扑图 配置流程 配置构思 具体流程 问题 演示过程 状态 检查Attack前centOS7_1的ARP地址表 在kali上输入以下命令发动攻击 此时查看centOS7_1的AR ...
- Win10家庭版WindowsUpdate属性为灰色
一般的取消Windows更新只需要打开任务管理器,点击服务 然后点击左下角的打开服务 找到WindowsUpdate,右键属性 按照正常的电脑只要在启动类型中选择禁用,然后在恢复里的第一次操作选择无操 ...
- python 在ubuntu下安装pycurl
https://www.linuxidc.com/Linux/2016-05/131574.htm
- 我的第一个chrome浏览器扩展 5分钟学习搞定
注意: 文件名必须是 manifest, ,注意扩展名是json, 新建一个文件夹,然后创建一个文本文件,作为这个扩展程序的配置文件,所以文件名是manifest.json, 感谢https://ww ...
- seleium_元素定位
一,元素定位 切换ifram 退出ifream alert定位 select多项选择操作 鼠标悬浮操作
- 使用kolin开发你的android应用
转载请注明出处,谢谢! 前段时间花了大概三周时间学习了kotlin,借着kotlin正好发布1.2,使用kotlin撸了一个android demo Github地址:https://github.c ...
- 动态sql语句,非存储过程,如何判断某条数据是否存在,如果不存在就添加一条
已知一个表 table 里面有两个字段 A1 和 A2 如何用动态语句 判断 A1 = A , A2=B 的数据是否存在,如果不存在,就添加一条数据, A1 = A , A2 = B INSERT ...