sklearn 中 make_blobs模块
# 生成用于聚类的各向同性高斯blob
sklearn.datasets.make_blobs(n_samples = 100,n_features = 2,center = 3,cluster_std = 1.0,center_box =( - 10.0,10.0),shuffle = True,random_state = None)
参数
n_samples: int, optional (default=100)
待生成的样本的总数。
n_features: int, optional (default=2)
每个样本的特征数。
centers: int or array of shape [n_centers, n_features], optional (default=3)
要生成的样本中心(类别)数,或者是确定的中心点。
cluster_std: float or sequence of floats, optional (default=1.0)
每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0]。
center_box: pair of floats (min, max), optional (default=(-10.0, 10.0))
中心随机生成时每个聚类中心的边界框。
shuffle:布尔值,可选(默认= True)
对样本进行随机播放。
random_state:int,RandomState实例或None,可选(default = None)
如果为int,random_state是随机数生成器使用的种子; 如果RandomState实例,random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。
返回
X : array of shape [n_samples, n_features]
生成的样本数据集。
y : array of shape [n_samples]
样本数据集的标签。
例子
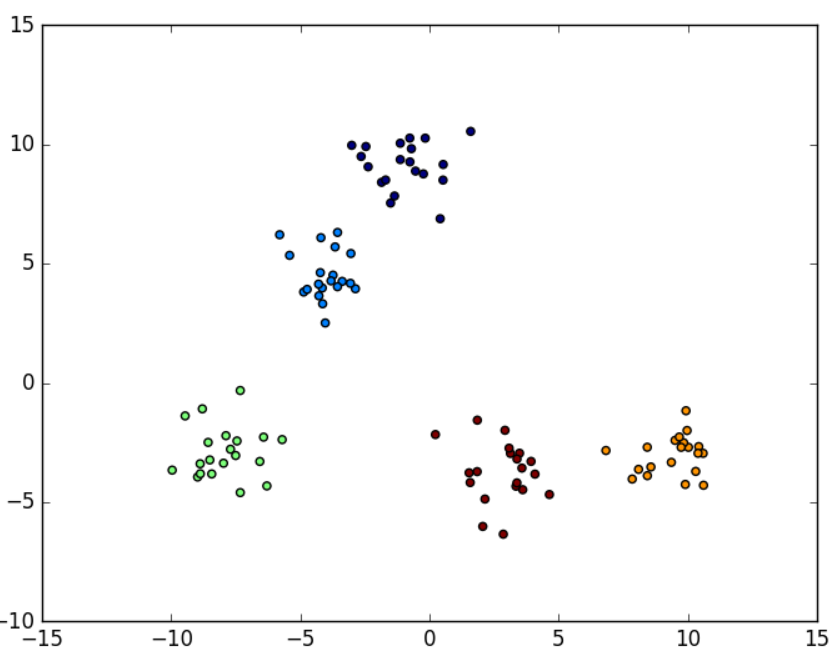
例如要生成5类数据(100个样本,每个样本有2个特征),代码如下
from sklearn.datasets import make_blobs
from matplotlib import pyplot data, label = make_blobs(n_samples=100, n_features=2, centers=5)
# 绘制样本显示
pyplot.scatter(data[:, 0], data[:, 1], c=label)
pyplot.show()
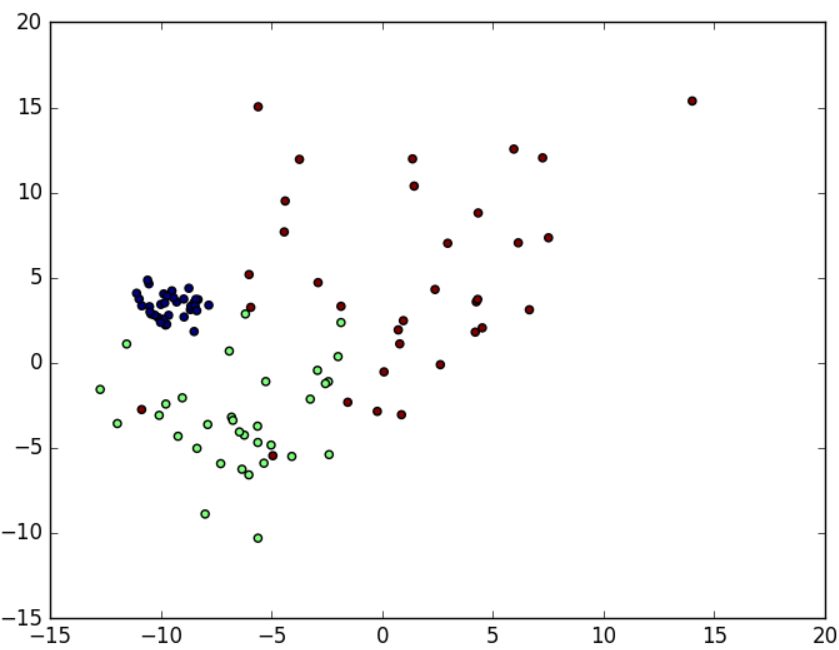
如果希望为每个类别设置不同的方差,需要在上述代码中加入cluster_std参数:
from sklearn.datasets import make_blobs
from matplotlib import pyplot data, label = make_blobs(n_samples=10, n_features=2, centers=3, cluster_std=[0.8, 2.5, 4.5])
# 绘制样本显示
pyplot.scatter(data[:, 0], data[:, 1], c=label)
pyplot.show()
sklearn 中 make_blobs模块的更多相关文章
- sklearn 中 make_blobs模块使用
sklearn.datasets.make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10 ...
- 【集成学习】sklearn中xgboost模块的XGBClassifier函数
# 常规参数 booster gbtree 树模型做为基分类器(默认) gbliner 线性模型做为基分类器 silent silent=0时,不输出中间过程(默认) silent=1时,输出中间过程 ...
- 【集成学习】sklearn中xgboost模块中plot_importance函数(绘图--特征重要性)
直接上代码,简单 # -*- coding: utf-8 -*- """ ################################################ ...
- sklearn中xgboost模块中plot_importance函数(特征重要性)
# -*- coding: utf-8 -*- """ ######################################################### ...
- 【集成学习】sklearn中xgboot模块中fit函数参数详解(fit model for train data)
参数解释,后续补上. # -*- coding: utf-8 -*- """ ############################################## ...
- sklearn中的metrics模块中的Classification metrics
metrics是sklearn用来做模型评估的重要模块,提供了各种评估度量,现在自己整理如下: 一.通用的用法:Common cases: predefined values 1.1 sklearn官 ...
- python中导入sklearn中模块提示ImportError: DLL load failed: 找不到指定的程序。
python版本:3.7 平台:windows 10 集成环境:Anaconda3.7 64位 在jupyter notebook中导入sklearn的相关模块提示ImportError: DLL l ...
- sklearn中的KMeans算法
1.聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇).这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布. 2.KMeans算法将一 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
随机推荐
- Struts2 用过滤器代替了 servlet ,???? 且不需要tomcat就可以直接做功能测试
Struts2 用过滤器代替了 servlet ,???? 且不需要tomcat就可以直接做功能测试
- Android系统自带分享功能的实现(可同时分享文字和图片)
/** * 分享功能 * * @param context * 上下文 * @param activityTitle * Activity的名字 * @param msgTitle * 消息标题 ...
- for-in 的坑
for-in 循环的下标为字符串,不是数字 var ar=[13,2,13,14]; function isSort(ar){ for(var i in ar){ console.log(i+':'+ ...
- 暴力破解Windows RDP(3389)
RDP是远程桌面协议. $ nmap your_target Starting Nmap 7.01 ( https://nmap.org ) at 2016-09-20 17:29 CST Nmap ...
- xml(带有命名空间的)读写操作
xml文件: <?xml version="1.0" encoding="UTF-8"?><!-- This file contains jo ...
- linux之epoll
1. epoll简介 epoll 是Linux内核中的一种可扩展IO事件处理机制,最早在 Linux 2.5.44内核中引入,可被用于代替POSIX select 和 poll 系统调用,并且在具有大 ...
- Android用Gson解析JSON字符串
在volley框架中有一个 protected Response<Result<T>> parseNetworkResponse(NetworkResponse respons ...
- fn project AWS Lambda 格式 functions
Creating Lambda Functions Creating Lambda functions is not much different than using regular funct ...
- 使用BasicDataSource连接池连接oracle数据库报错ORA-12505
先看连接池配置: <bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" ...
- python一个简单的web服务器和客户端
服务器: 当客户联系时创建一个连接套接字 从这个连接接收HTTP请求(*) 解释该请求所请求的特定文件 从服务器的文件系统获取该文件 并发送文件内容 ...