Flask开发系列之Flask+redis实现IP代理池
Flask开发系列之Flask+redis实现IP代理池
代理池的要求
多站抓取,异步检测:多站抓取:指的是我们需要从各大免费的ip代理网站,把他们公开的一些免费代理抓取下来;一步检测指的是:把这些代理通过异步请求的方式,利用这些代理请求网站:如果能正常请求就证明代理可用,如果不能正常请求就证明代理不行,这时就可以把这个代理剔除掉,异步指的是:我们不需要一直等待代理请求网站,到得到response之后在执行相应的操作就可以了,异步可以提高检测效率。
定时筛选,持续更新:我们维护一个代理池,我们需要做的是需要定时从里面拿出一部分来检测,剔除掉不可用的代理。这可以保证代理是可用的
提供接口,易于提取:代理实际上是维护在一个队列中,队列可以使用数据库存储,也可以使用一些数据结构来存储,但是如果要获取代理的话,要提供一个简单的接口,最简单的是web形式的接口:本文主要演示一个利用python flask包来提供接口:之后使用python请求网址,从网页中拿到代理的信息了
代理池的架构
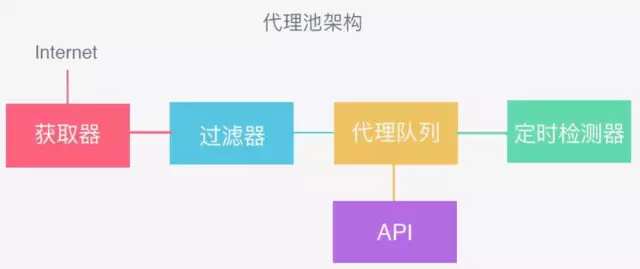
获取器:从各大网站平台抓取代理:ip和端口
过滤器:剔除掉不可用的代理
将可用代理放到代理队列
定时检测器:剔除不可用的代理
API:通过接口形式拿到代理对象,方便使用
测试实现版
import requests
import re
import time
import redis
from bloom_filter import BloomFilter
import ast pool = redis.ConnectionPool(host='localhost',password='xxx', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
bloombloom = BloomFilter(max_elements=10000, error_rate=0.1)
bloombloom.add(str({'http': '117.91.232.53:9999'})) def get_ip(i):
ip_list=[]
url = 'https://www.kuaidaili.com/free/inha/'
url = url + str(i + 1)
html = requests.get(url=url, ).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip, re.S)
ipstr = re.findall(matcher, html)
time.sleep(1)
for j in ipstr:
ip_list.append(j[0] + ':' + j[1])
print('共收集到%d个代理ip' % len(ip_list))
print(ip_list)
return ip_list def valVer(proxys):
global badNum,goodNum,good_list
good = []
for proxy in proxys:
try:
proxy_host = proxy
protocol = 'https' if 'https' in proxy_host else 'http'
proxies = {protocol: proxy_host}
print('现在正在测试的IP:', proxies)
response = requests.get('http://www.baidu.com', proxies=proxies, timeout=2)
if response.status_code != 200:
badNum += 1
print(proxy_host, 'bad proxy')
else:
goodNum += 1
good.append(proxies)
good_list.append(proxies)
print(proxy_host, 'success proxy')
except Exception as e:
print(e)
# print proxy_host, 'bad proxy'
badNum += 1
continue
print('success proxy num : ', goodNum)
print('bad proxy num : ', badNum)
print("这次:",good)
print("此时全部:",good_list)
return good def time_valVer(proxys):
good = []
for proxy in proxys:
try:
print('现在正在定时测试的IP:',proxy)
proxy = ast.literal_eval(proxy)
response = requests.get('http://www.baidu.com', proxies=proxy, timeout=2)
if response.status_code != 200:
r.lrem("ip_list", proxy, 1)
print(proxy, 'bad proxy')
else:
good.append(proxy)
good_list.append(proxy)
print(proxy, 'success proxy')
except Exception as e:
print(e)
continue def stone(good):
for IP in good:
if str(IP) in bloombloom:
print("%s不能存储,有相同的IP",IP)
continue
else:
print("存储的IP:", IP)
bloombloom.add(str(IP))
r.rpush("ip_list", str(IP)) if __name__ == '__main__': badNum = 0
goodNum = 0
good_list = []
for i in range(0,10):
if i%10 == 0 and i!=0:
proxy_list = []
for i in range(0, r.llen("ip_list")):
proxy_list.append(r.lindex("ip_list", i))
time_valVer(proxy_list)
else:
ip_list = get_ip(i)
good = valVer(ip_list)
stone(good)
from flask import Flask
import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 r = redis.Redis(host='localhost', port=6379,password='xxx',decode_responses=True)
app = Flask(__name__)
@app.route('/ip/<int:index>')
def reponse(index):
print(index)
print(r.lindex("ip_list", index))
return r.lindex("ip_list", index)
if __name__ == '__main__':
app.run(debug=True)
获取ip:

改进版
import requests
import re
import time
import redis
from bloom_filter import BloomFilter
import ast pool = redis.ConnectionPool(host='localhost',password='XXX', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
bloombloom = BloomFilter(max_elements=10000, error_rate=0.1) def get_ip(i):
ip_list=[]
url = 'https://www.kuaidaili.com/free/inha/'
url = url + str(i + 1)
html = requests.get(url=url, ).text
regip = '<td.*?>(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})</td>.*?<td.*?>(\d{1,5})</td>'
matcher = re.compile(regip, re.S)
ipstr = re.findall(matcher, html)
time.sleep(1)
for j in ipstr:
ip_list.append(j[0] + ':' + j[1])
print('共收集到%d个代理ip' % len(ip_list))
print(ip_list)
return ip_list def valVer(proxys):
global badNum,goodNum,good_list
good = []
for proxy in proxys:
try:
proxy_host = proxy
protocol = 'https' if 'https' in proxy_host else 'http'
proxies = {protocol: proxy_host}
response = requests.get('http://www.baidu.com', proxies=proxies, timeout=2)
if response.status_code != 200:
badNum += 1
else:
goodNum += 1
good.append(proxies)
good_list.append(proxies)
except Exception as e:
print(e)
badNum += 1
continue
print('success proxy num : ', goodNum)
print('bad proxy num : ', badNum)
print("这次:",good)
print("此时全部:",good_list)
return good def time_valVer(proxys):
for proxy in proxys:
try:
print('现在正在定时测试的IP:',proxy)
proxy = ast.literal_eval(proxy)
response = requests.get('http://www.baidu.com', proxies=proxy, timeout=2)
if response.status_code != 200:
r.lrem("ip_list", proxy, 1)
except Exception as e:
print(e)
continue def stone_redis(good):
for IP in good:
if str(IP) in bloombloom:
print("%s不能存储,有相同的IP",IP)
continue
else:
print("存储的IP:", IP)
bloombloom.add(str(IP))
r.rpush("ip_list", str(IP)) def init():
for i in range(0, r.llen("ip_list")):
print(r.lindex("ip_list", i))
bloombloom.add(r.lindex("ip_list", i)) if __name__ == '__main__':
badNum = 0
goodNum = 0
good_list = []
init()
for i in range(0,10):
if i%2 == 0 and i!=0:
proxy_list = []
for i in range(0, r.llen("ip_list")):
proxy_list.append(r.lindex("ip_list", i))
time_valVer(proxy_list)
else:
ip_list = get_ip(i)
good = valVer(ip_list)
stone_redis(good)
from flask import Flask, abort, request, jsonify
import redis # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库 r = redis.Redis(host='localhost', port=6379,password='XXX',decode_responses=True)
app = Flask(__name__)
@app.route('/ip/<int:index>', methods=['GET'])
def reponse(index):
print(index)
ip = {"ip":r.lindex("ip_list", index)}
print(r.lindex("ip_list", index))
return jsonify(ip)
if __name__ == '__main__':
app.run(debug=True)
获取ip:

Flask开发系列之Flask+redis实现IP代理池的更多相关文章
- Scrapy加Redis加IP代理池实现音乐爬虫
音乐爬虫 关注公众号"轻松学编程"了解更多. 目的:爬取歌名,歌手,歌词,歌曲url. 一.创建爬虫项目 创建一个文件夹,进入文件夹,打开cmd窗口,输入: scrapy star ...
- 利用 Flask+Redis 维护 IP 代理池
代理池的维护 目前有很多网站提供免费代理,而且种类齐全,比如各个地区.各个匿名级别的都有,不过质量实在不敢恭维,毕竟都是免费公开的,可能一个代理无数个人在用也说不定.所以我们需要做的是大量抓取这些免费 ...
- 记一次企业级爬虫系统升级改造(六):基于Redis实现免费的IP代理池
前言: 首先表示抱歉,春节后一直较忙,未及时更新该系列文章. 近期,由于监控的站源越来越多,就偶有站源做了反爬机制,造成我们的SupportYun系统小爬虫服务时常被封IP,不能进行数据采集. 这时候 ...
- Flask开发系列之数据库操作
Flask开发系列之数据库操作 Python数据库框架 我们可以在Flask中使用MySQL.Postgres.SQLite.Redis.MongoDB 或者 CouchDB. 还有一些数据库抽象层代 ...
- Flask开发系列之快速入门
Flask开发系列之快速入门 文档 一个最小的应用 调试模式 路由 变量规则 构造 URL HTTP 方法 静态文件 模板渲染 访问请求数据 环境局部变量 请求对象 文件上传 Cookies 重定向和 ...
- Flask开发系列之Web表单
Flask开发系列之Web表单 简单示例 from flask import Flask, request, render_template app = Flask(__name__) @app.ro ...
- Flask开发系列之模板
Flask开发系列之模板 本文对<FlaskWeb开发:基于python的Web应用开发实战>模板一节做的总结. Jinja2模板引擎 模板 模板是一个包含响应文本的文件,其中包含用占位变 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- Python爬虫之ip代理池
可能在学习爬虫的时候,遇到很多的反爬的手段,封ip 就是其中之一. 对于封IP的网站.需要很多的代理IP,去买代理IP,对于初学者觉得没有必要,每个卖代理IP的网站有的提供了免费IP,可是又很少,写了 ...
随机推荐
- MQTT消息中间件Mosquitto的安装和配置
特别提示:本人博客部分有参考网络其他博客,但均是本人亲手编写过并验证通过.如发现博客有错误,请及时提出以免误导其他人,谢谢!欢迎转载,但记得标明文章出处:http://www.cnblogs.com/ ...
- 第八周总结&实验报告六
总结:这周主要是学习异常的使用,已经怎么解决异常,总的来说学习的还是有点难度的,因为前面的知识还需要时间去弥补,这门课程还是要加油的学习! 这周主要所学: 一.异常 1.异常是导致程序中断运行的一种指 ...
- java学期总结
第一周https://www.cnblogs.com/sqhe2000/p/11482760.html. 第二周https://www.cnblogs.com/sqhe2000/p/11521023. ...
- python3笔记四:if语句
一:学习内容 if语句 if-else语句 if-elif-else语句 if语句练习 二:if语句 1. 格式 if 表达式: 语句 2.逻辑 当程序执行到if语句时,首先计算表达式的值如果表 ...
- Java_IO流实验
实验题目链接:Java第09次实验(IO流) 0. 字节流与二进制文件 我的代码 package experiment.io; import java.io.DataInputStream; impo ...
- weblogic域,管理服务器,受管服务器,集群和机器的基本知识
1.域(Domain) •它是什么? –是一个逻辑上管理的WebLogic Server组,这些组从管理上当作一个整体来操作 •域里面有什么? –服务器 –服务器集群 –机器 •规则: –同一个域中的 ...
- 深入理解android的UI更新机制
深入理解android的UI更新机制 由问题开始: 如何更新android UI? 可以通过如下方法: 在主线程里直接操作UI控件. handler.post(Runnable) runOnUiThr ...
- CondenseNet: An Efficient DenseNet using Learned Group Convolutions
1. 摘要 作者提出了一个前所未有高效的新奇网络结构,称之为 CondenseNet,该结构结合了密集连接性和可学习的分组卷积模块. 密集连接性有利于网络中的特征复用,而可学习的分组卷积模块则可以移除 ...
- django-登录页面添加验证码
1,安装第三方库 pip install django-simple-captcha 2,注册应用 INSTALLED_APPS = [ 'django.contrib.admin', 'django ...
- Libvirt Live Migration 与 Pre-Copy 实现原理
目录 文章目录 目录 Libvirt 的 Live Migration 网络数据传输层 控制层 通过 libvirt 库实现虚拟机迁移的示例 KVM 的预拷贝(Pre-Copy)Live Migrat ...