HDFS集中化缓存管理
概述
使用场景
架构
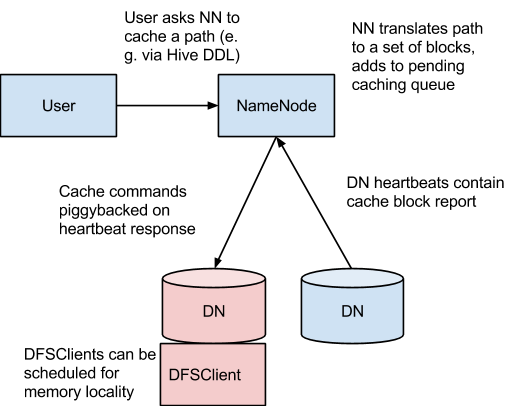
概念
缓存指令
缓存池
缓存管理命令接口
缓存管理命令addDirective
| <path> | 要缓存的路径。该路径可以是文件夹或文件。 |
| <pool-name> | 要加入缓存指令的缓存池。你必须对改缓存池有写权限以便添加新的缓存指令。 |
| -force | 不检查缓存池的资源限制 |
| <replication> | 要使用的缓存副本因子,默认为1 |
| <time-to-live> | 缓存指令可以保持有效多长时间。可以按照分钟,小时,天来指定,如30m,4h,2d。有效单位为[smhd]。“never”表示永不过期的指令。如果未指定该值,那么,缓存指令就不会过期。 |
removeDirective
| <id> | 要删除的缓存指令的ID。你必须对该指令的缓存池拥有写权限,以便删除它。要查看详细的缓存指令列表,可以使用-listDirectives命令。 |
removeDirectives
| <path> | 要删除的缓存指令的路径。你必须对该指令的缓存池拥有写权限,以便删除它。要查看详细的缓存指令列表,可以使用-listDirectives命令。 |
listDirectives
| <path> | 只列出带有该路径的缓存指令。注意,如果路径path在缓存池中有一条我们没有读权限的缓存指令,那么它就不会被列出来。 |
| <pool> | 只列出该缓存池内的缓存指令。 |
| -stats | 列出基于path的缓存指令统计信息。 |
缓存池命令
addPool
| <name> | 新缓存池的名称。 |
| <owner> | 该缓存池所有者的名称。默认为当前用户。 |
| <group> | 缓存池所属的组。默认为当前用户的主要组名。 |
| <mode> | 以UNIX风格表示的该缓存池的权限。权限以八进制数表示,如0755.默认值为0755. |
| <limit> | 在该缓存池内由指令总计缓存的最大字节数。默认不设限制。 |
| <maxTtl> | 添加到该缓存池的指令的最大生存时间。该值以秒,分,时,天的格式来表示,如120s,30m,4h,2d。有效单位为[smhd]。默认不设最大值。“never”表示没有限制。 |
modifyPool
| <name> | 要修改的缓存池的名称。 |
| <owner> | 该缓存池所有者的名称。 |
| <group> | 缓存池所属的组。 |
| <mode> | 以UNIX风格表示的该缓存池的权限。八进制数形式。 |
| <limit> | 在该缓存池内要缓存的最大字节数。 |
| <maxTtl> | 添加到该缓存池的指令的最大生存时间。 |
removePool
| <name> | 要删除的缓存池的名称 |
listPools
| -stats | 显示额外的缓存池统计信息 |
| <name> | 若指定,则仅列出该缓存池的信息 |
help
| <command name> | 要获得详细帮助信息的命令。如果没有指定命令,则打印所有命令的帮助信息。 |
配置
本地库
配置属性
|
属性名称
|
默认值
|
描述
|
| dfs.datanode.max.locked.memory |
0
|
DataNode的内存中缓存块副本要用的内存量(以字节表示)。DataNode的最大锁定内存软限制ulimit(RLIMIT_MEMLOCK)必须至少设为该值。 否则,DataNode在启动时会终止。默认值为0,表示禁止内存缓存。如果本地库对于该DataNode不可用,那么,该配置就无效。 |
| dfs.namenode.list.cache.directives.num.responses |
100
|
该参数控制NameNode在响应listDirectives RPC命令时通过wire发送的缓存指令数。 |
| dfs.namenode.list.cache.pools.num.responses |
100
|
该参数控制NameNode在响应listDirectives RPC命令时通过wire发送的缓存池数。 |
| dfs.namenode.path.based.cache.refresh.interval.ms |
30000
|
两次子路径缓存重复扫描的时间间隔,单位毫秒。路径缓存重复扫描发生在计算缓存哪个块,以及在哪个DataNode上缓存时。默认为30秒。 |
| dfs.namenode.path.based.cache.retry.interval.ms |
30000
|
当NameNode不需要缓存某些数据,或者缓存那些没有缓存的数据时,它必须通过在DataNode心跳响应中发送DNA_CACHE或者DNA_UNCACHE命令,以便指导DataNode这么去做。该参数控制NameNode重复发送这些命令的频率。(即多长时间重发一次) |
| dfs.datanode.fsdatasetcache.max.threads.per.volume |
4
|
DataNode上缓存新数据时每个卷要用的最大线程数。 这些线程要消耗I/O和CPU。该参数影响普通DataNode操作。 |
| dfs.cachereport.intervalMsec |
10000
|
决定两次缓存上报动作的时间间隔,单位毫秒。超过这个时间后,DataNode会向NameNode发送其缓存状态的完整报告。 NameNode使用缓存报告来更新缓存块与DataNode位置之间的映射关系。如果内存缓存被禁用了(设置属性dfs.datanode.max.locked.memory为0,这是默认值),那么该参数就无效了。如果本地库对于该DataNode不可用,那么,该配置就无效。 |
| dfs.datanode.cache.revocation.timeout.ms |
900000
|
当DFSClient从DataNode正在缓存的块文件中读取数据时,DFSClient可以不做checksums校验。DataNode一直将块文件保存在缓存中直到客户端完成。然而,如果客户端一改往常般运行了很长时间,那么,DataNode可能需要从缓存中清除这个块文件。该参数控制DataNode等待一个正在执行无校验读操作的客户端发送一个副本要花多少时间。 |
| dfs.datanode.cache.revocation.polling.ms |
500
|
DataNode需要多长时间轮询一次客户端是否停止使用DataNode不想缓存的副本。 |
必选属性
|
属性名称
|
默认值
|
描述
|
| dfs.datanode.max.locked.memory | 该参数用于确定DataNode给缓存使用的最大内存量。DataNode用户的“locked-in-memory size”ulimit(ulimit -l)也需要增加以匹配该参数(详见下文OS限制)。当设置了该值时,请记住你还需要一些内存空间用于做其他事情,比如,DataNode和应用程序JVM堆内存、以及操作系统的页缓存。 |
可选属性
|
属性名称
|
默认值
|
描述
|
| dfs.namenode.path.based.cache.refresh.interval.ms |
300000
|
NameNode使用该参数作为两次子路径缓存重复扫描的动作之间的时间间隔,单位为毫秒。该参数计算要缓存的块和每个DataNode包含一个该块应当缓存的副本。 |
| dfs.datanode.fsdatasetcache.max.threads.per.volume |
4
|
DataNode使用该参数作为缓存新数据时每个卷要用的最大线程数。 |
| dfs.cachereport.intervalMsec |
10000
|
DataNode使用该参数作为两次发送缓存状态报告给NameNode的动作之间的时间间隔。单位为毫秒。 |
| dfs.namenode.path.based.cache.block.map.allocation.percent |
0.25
|
分配给已缓存块映射的Java堆内存的百分比。它是hash map,使用链式hash。如果缓存块的数目很大,那么map越小,访问速度越慢;map越大,消耗的内存越多。 |
OS限制
HDFS集中化缓存管理的更多相关文章
- 【Hadoop学习】HDFS中的集中化缓存管理
Hadoop版本:2.6.0 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4146398.html 概述 ...
- HDFS集中式缓存管理(Centralized Cache Management)
Hadoop从2.3.0版本号開始支持HDFS缓存机制,HDFS同意用户将一部分文件夹或文件缓存在HDFS其中.NameNode会通知拥有相应块的DataNodes将其缓存在DataNode的内存其中 ...
- HDFS中的集中缓存管理详解
一.背景 Hadoop设计之初借鉴GFS/MapReduce的思想:移动计算的成本远小于移动数据的成本.所以调度通常会尽可能将计算移动到拥有数据的节点上,在作业执行过程中,从HDFS角度看,计算和数据 ...
- HDFS集中式的缓存管理原理与代码剖析--转载
原文地址:http://yanbohappy.sinaapp.com/?p=468 Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache ...
- HDFS集中式的缓存管理原理与代码剖析
转载自:http://www.infoq.com/cn/articles/hdfs-centralized-cache/ HDFS集中式的缓存管理原理与代码剖析 Hadoop 2.3.0已经发布了,其 ...
- 十一:Centralized Cache Management in HDFS 集中缓存管理
集中的HDFS缓存管理,该机制可以让用户缓存特定的hdfs路径,这些块缓存在堆外内存中.namenode指导datanode完成这个工作. Centralized cache management i ...
- HTML5 离线缓存管理库
一.HTML5离线缓存技术 支持离线缓存是HTML5中的一个重点,离线缓存就是让用户即使在断网的情况下依然可以正常的运行应用.传统的本地存储数据的方式有 localstorage,sessionsto ...
- shiro缓存管理
一. 概述 Shiro作为一个开源的权限框架,其组件化的设计思想使得开发者可以根据具体业务场景灵活地实现权限管理方案,权限粒度的控制非常方便.首先,我们来看看Shiro框架的架构图:从上图我们可以很清 ...
- 缓存管理之MemoryCache与Redis的使用
一..MemoryCache介绍 MemoryCache是.Net Framework 4.0开始提供的内存缓存类,使用该类型可以方便的在程序内部缓存数据并对于数据的有效性进行方便的管理, 它通过在内 ...
随机推荐
- WebService第一天——概述与入门操作
一.概述 1.是什么 Web service是一个平台独立的,低耦合的,自包含的.基于可编程的web的应用程序,可使用开放的XML(标准通用标记语言下的一个子集)标准来描述.发布.发现.协调和配置这些 ...
- 一步一步学Linq to sql(三):增删改
示例数据库 字段名 字段类型 允许空 字段说明 ID uniqueidentifier 表主键字段 UserName varchar(50) 留言用户名 PostTime datetime 留言时间 ...
- hibernate 各历史版本下载 spring各历史版本下载
hibernate 各历史版本下载http://sourceforge.net/projects/hibernate/files/ spring各历史版本下载http://www.springsour ...
- nginx location优先级
目录 1. 配置语法 2. 配置实例 3. 总结: 网上查了下location的优先级规则,但是很多资料都说的模棱两可,自己动手实地配置了下,下面总结如下. 1. 配置语法 1> 精确匹配 lo ...
- windows 无法上网问题解决一例
dhcp获取ip地址,网卡驱动和ip地址获取正常,ping www.baidu.com可以ping通,但是打开浏览器或者qq上网不行,而且系统有提示腾讯管家出错的信息,初步怀疑360和腾讯管家打架导致 ...
- npm命令 VS yarn命令
npm yarn 说明 npm init yarn init 在项目中引导创建一个package.json文件 npm install yarn install/yarn 安装所有依赖包(依据pa ...
- Qt程序加图标
第一步 准备一个ICON图标 例如:myicon.ico 新建文本文件,里面编辑文字 IDI_ICON1 ICON DISCARDABLE "myicon.ico" 文件另存为 x ...
- windows本地连接腾讯云的mysql服务器
由于最近数据库需要用上Navicat作为数据库,但是我的mysql装在腾讯云的Ubuntu上,因此需要做些配置开放端口,和监听端口,因此略显麻烦,这里记录一下连接的具体步骤,方便以后又得装(flag) ...
- HTML5的 input:file上传类型控制(转载)
http://www.haorooms.com/post/input_file_leixing HTML5的 input:file上传类型控制 2014年8月29日 66352次浏览 一.input: ...
- hibernate 批量插入
Session session = sessionFactoryUpLowLimit.openSession(); session.beginTransaction(); for(int i=0 ;i ...