十一:Centralized Cache Management in HDFS 集中缓存管理
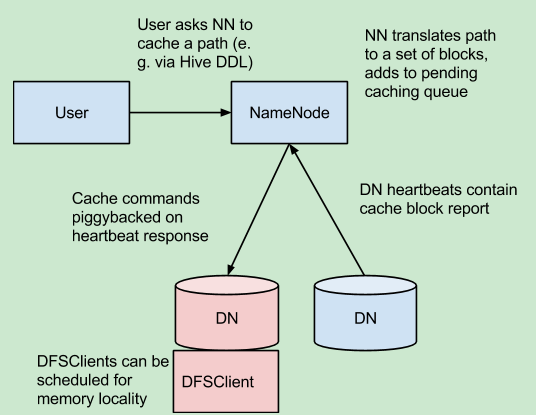
集中的HDFS缓存管理,该机制可以让用户缓存特定的hdfs路径,这些块缓存在堆外内存中。namenode指导datanode完成这个工作。
Centralized cache management in HDFS has many significant advantages.
- Explicit pinning prevents frequently used data from being evicted from memory. This is particularly important when the size of the working set exceeds the size of main memory, which is common for many HDFS workloads. 阻止经常使用的数据被逐出内存。
- Because DataNode caches are managed by the NameNode, applications can query the set of cached block locations when making task placement decisions. Co-locating a task with a cached block replica improves read performance.
- When block has been cached by a DataNode, clients can use a new , more-efficient, zero-copy read API. Since checksum verification of cached data is done once by the DataNode, clients can incur essentially zero overhead when using this new API.可以使用更高效的无复制的api读这些块。
- Centralized caching can improve overall cluster memory utilization. When relying on the OS buffer cache at each DataNode, repeated reads of a block will result in all nreplicas of the block being pulled into buffer cache. With centralized cache management, a user can explicitly pin only m of the n replicas, saving n-m memory.减少重复读时使用的
十一:Centralized Cache Management in HDFS 集中缓存管理的更多相关文章
- Centralized Cache Management in HDFS
Overview(概述) Centralized cache management in HDFS is an explicit caching mechanism that allows users ...
- HDFS集中式缓存管理(Centralized Cache Management)
Hadoop从2.3.0版本号開始支持HDFS缓存机制,HDFS同意用户将一部分文件夹或文件缓存在HDFS其中.NameNode会通知拥有相应块的DataNodes将其缓存在DataNode的内存其中 ...
- HDFS中的集中缓存管理详解
一.背景 Hadoop设计之初借鉴GFS/MapReduce的思想:移动计算的成本远小于移动数据的成本.所以调度通常会尽可能将计算移动到拥有数据的节点上,在作业执行过程中,从HDFS角度看,计算和数据 ...
- HDFS集中式的缓存管理原理与代码剖析--转载
原文地址:http://yanbohappy.sinaapp.com/?p=468 Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache ...
- HDFS集中式的缓存管理原理与代码剖析
转载自:http://www.infoq.com/cn/articles/hdfs-centralized-cache/ HDFS集中式的缓存管理原理与代码剖析 Hadoop 2.3.0已经发布了,其 ...
- 自定义缓存管理器 或者 Spring -- cache
Spring Cache 缓存是实际工作中非常常用的一种提高性能的方法, 我们会在许多场景下来使用缓存. 本文通过一个简单的例子进行展开,通过对比我们原来的自定义缓存和 spring 的基于注释的 c ...
- 【Hadoop学习】HDFS中的集中化缓存管理
Hadoop版本:2.6.0 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4146398.html 概述 ...
- HDFS集中化缓存管理
概述 HDFS中的集中化缓存管理是一个明确的缓存机制,它允许用户指定要缓存的HDFS路径.NameNode会和保存着所需快数据的所有DataNode通信,并指导他们把块数据缓存在off-heap缓存中 ...
- Webview离线功能(优先cache缓存+cache缓存管理)
在做Webview显示服务器的html功能时 需要加入离线功能. 开始思路很狭隘,以为一定应该是从服务器得到的html文件,下载到本地后加载~ 但是这样不能离线查看图片,因为图片数据并不再html中, ...
随机推荐
- Cornerstone|SVN
SQLite-database disk image is malformed missing from working copy mac下CornerstoneSVN出错 Description _ ...
- 协作开发中常用的Git命令小结
先提一下最基础的git命令用法: git clone 从远端克隆到本地仓库 git add . (注意add和. 之间有一个空格)将全部改动添加到暂存区 git checkout xxx 撤销更改 ...
- 基于DCT的图片数字水印实验
1. 实验类别 设计型实验:MATLAB设计并实现基于DCT的图像数字水印算法. 2. 实验目的 了解基于DCT的图像数字水印技术,掌握基于DCT系数关系的图像水印算法原理,设计并实现一种基于DCT的 ...
- redis之闪电内幕
一.简介和应用 二.Redis的对象redisObject 三.String 四.List 4.1 linkedlist(双端链表) 4.2 ziplist(压缩列表) 五.Hash 六.Set 七. ...
- 用PHP读取Excel、CSV文件
PHP读取excel.csv文件的库有很多,但用的比较多的有: PHPOffice/PHPExcel.PHPOffice/PhpSpreadsheet,现在PHPExcel已经不再维护了,最新的一次提 ...
- Product Helper
using System; using Microsoft.Xrm.Sdk; using Microsoft.Crm.Sdk.Messages; /// <summary> /// 产品 ...
- python django-admin startproject django-admin命令未找到
在使用pip install安装django后使用django-admin生成项目失败解决办法 1.配置环境变量-在系统环境变量path添加后运行 D:\Program Files (x86)\pyt ...
- Django项目中关于redis包版本的坑
1.环境 python:3.6 django:1.11.8 redis:3.2.1 2.遇到的问题 报错:redis.exceptions.DataError: Invalid input of ty ...
- Python 1.2 列表和字典基础
一. List创建.索引.遍历和内置增删函数 1.列表是Python的内置可变对象,由Array实现,支持任意类型的添加.组合和嵌套. L = [] # list declare L = [1, 1. ...
- linux 网络编程 1---(基本概念)
1.TCP和UDP协议 共同点:同为传输层协议 不同点: TCP:有连接,可靠 UPD 无连接,不保证可靠 TCP(即传输控制协议): 是一种面向连接的传输层协议,它是能提供高可靠性通信(即,数据无误 ...