Spark Streamming 基本输入流I(-) :File/Hdfs
Spark Streamming 基本输入流I(-):从文件中进行读取
文件读取1:本地文件读取
这里我只给出实现代码及操作步骤
1、在本地目录下创建目录,这里我们创建目录为~/log/
2、然后手动在~/目录下创建两个文件夹。t1.dat ,t2.dat
t1.dat 格式如下:
hello hadoop
hello spark
hello Java
hellp hbase
hello scala
t2.dat格式如下:
My name is Brent,
how are you
nice to meet you
3、编写spark streamming程序,并将其运行起来。
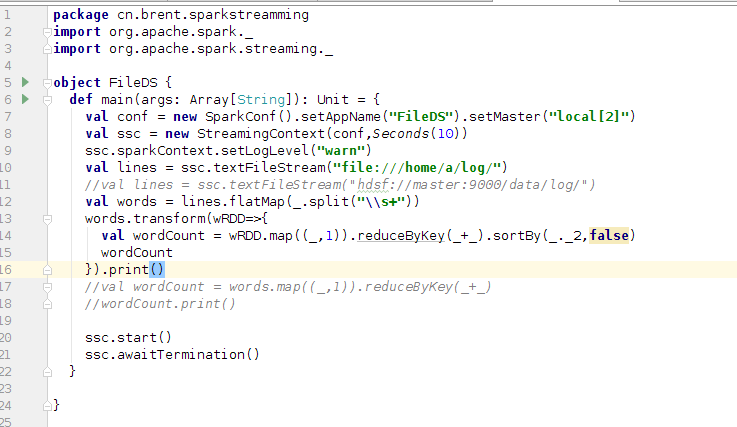
4、使用命令cp ~/t*.dat ./log/ 将t1.dat ,t2.dat移动到~/log目录下,
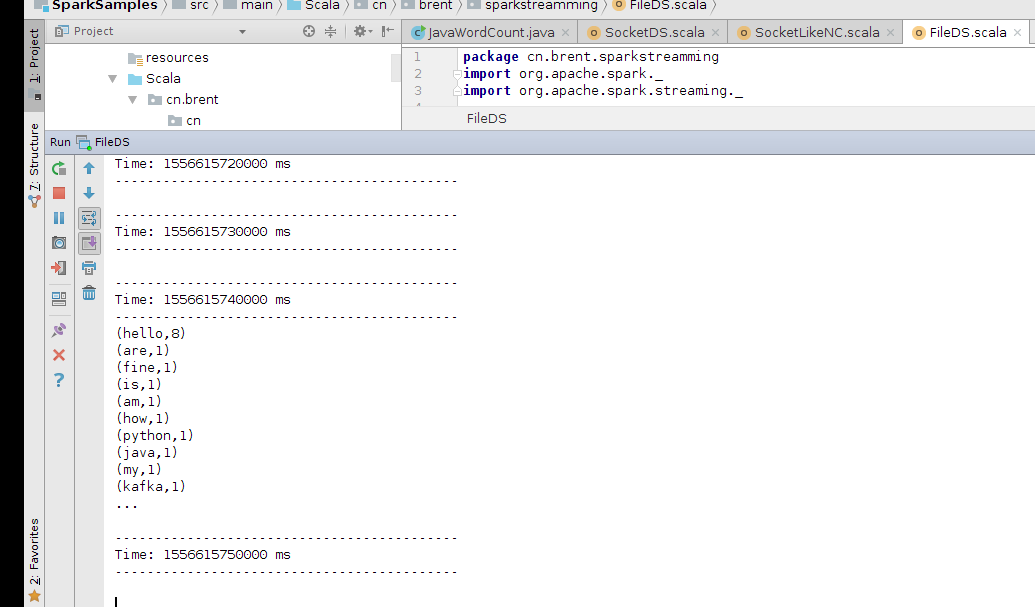
5、查看spark Streamming程序的运行情况。
文件读取2:HDFS文件读取
HDFS文件读取和本地是相差无几的,
不同之处如下
程序中修改文件引入路径//val lines = ssc.textFileStream("hdsf://master:9000/data/log/")
本地文件t1.dat 和 t2.dat 需要上传到hdfs://master:9000/data/log下
hdfs dfs -mkdir data/log 创建目录。
hdfs dfs -put t*.dat data/log/
注意点:
文件作为输入流容易出错的一点就是,目录下面的文件一定要是cp进来,而不是mv进来了,因为cp进行的文件时间戳是改变的,而mv进来的时间戳没有改变,spark Streamming就不会进行处理。
Spark Streamming 基本输入流I(-) :File/Hdfs的更多相关文章
- Spark Streamming 基本输入流(二) :Socket
Spark Streamming 可以通过socket 进行数据监听. socket的输入方可以通过nc 或者自己开发nc功能的程序. 1.系统自带的nc su root a yum install ...
- Spark2.x(五十五):在spark structured streaming下sink file(parquet,csv等),正常运行一段时间后:清理掉checkpoint,重新启动app,无法sink记录(file)到hdfs。
场景: 在spark structured streaming读取kafka上的topic,然后将统计结果写入到hdfs,hdfs保存目录按照month,day,hour进行分区: 1)程序放到spa ...
- ParquetDecodingException: Can not read value at 0 in block -1 in file hdfs:...
: jdbc:hive2://master01.hadoop.dtmobile.cn:1> select * from cell_random_grid_tmp2 limit 1; INFO : ...
- kettle在本地执行向远程hdfs执行转换错误"Couldn't open file hdfs"
kettle在本地执行向远程hdfs执行转换时,会出现以下错误: ToHDFS.0 - ERROR (version 7.1.0.0-12, build 1 from 2017-05-16 17.18 ...
- ERROR: Found lingering reference file hdfs
Found lingering reference异常 ERROR: Found lingering reference file hdfs://jiujiang1:9000/hbase/month_ ...
- Spark No FileSystem for scheme file 解决方法
在给代码带包成jar后,放到环境中运行出现如下错误: Exception in thread "main" java.io.IOException: No FileSystem f ...
- 通过Spark SQL关联查询两个HDFS上的文件操作
order_created.txt 订单编号 订单创建时间 -- :: -- :: -- :: -- :: -- :: order_picked.txt 订单编号 订单提取时间 -- :: ...
- MapReduce 踩坑 - hadoop No FileSystem for scheme: file/hdfs
一.场景 hadoop-3.0.2 + hbase-2.0.0 一个mapreduce任务,在IDEA下本地提交到hadoop集群可以正常运行. 现在需要将IDEA本地项目通过maven打成jar包, ...
- Spark设置自定义的InputFormat读取HDFS文件
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/problem_spark_reading_hdfs_serial ...
随机推荐
- spring cloud 之 Feign的使用
1.添加依赖 2.创建FeignClient 原理:Spring Cloud应用在启动时,Feign会扫描标有@FeignClient注解的接口,生成代理,并注册到Spring容器中.生成代理时Fei ...
- Single Vendor Project in OpenStack
1.astara: ptl: name: Ryan Petrello irc: ryanpetrello email: ryan.petrello@dreamhost.com irc-channel: ...
- 让C:\Users文件夹放在D盘
新安装win7 在安装Win7的过程中,要求输入用户名及密码的时候,先不如输入任何信息,按“Shift+F10”呼出DOS窗口,输入以下命令: robocopy "C:\Users" ...
- Android中用Java代码实现zip文件解压缩
如果需要下载的文件有很多是中文名的,解压时有中文名的文件出现乱码,试了很多方法不能解决问题.据说有一个Java插件包,用这个插件包可以解决中文名乱码的问题,但不知解压的文件是否要用它提供的类压缩后的文 ...
- React.js 小书 Lesson13 - 渲染列表数据
作者:胡子大哈 原文链接:http://huziketang.com/books/react/lesson13 转载请注明出处,保留原文链接和作者信息. 列表数据在前端非常常见,我们经常要处理这种类型 ...
- HDU 5222 ——Exploration——————【并查集+拓扑排序判有向环】
Exploration Time Limit: 30000/15000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)T ...
- js录制视频并保存
使用webAPI录制视频 经测试, 只在谷歌和火狐浏览器里起效. 代码: const streamVideo = document.querySelector('.stream') const pla ...
- phpstorm一些简单配置
1.字体大小和行间距 2.设置编码:包括编辑工具编码和项目编码
- 线程的Interrupt方法与InterruptedException解析
线程阻塞状态与等待状态(当一个线程处于被阻塞或等待状态时,它暂时不活动,不允许任何代码且消耗最少的资源) 当一个线程试图获得一个内部的对象锁(而不是java.util.concurrent库中的锁), ...
- C#学习笔记7
1.重写GetHashCode方法注意点: (1)重写GetHashCode方法,也应重写Equals方法,否者编译器会警告. (2)相等的对象必须有相等的散列码(若a.Equals(b),则a.Ge ...